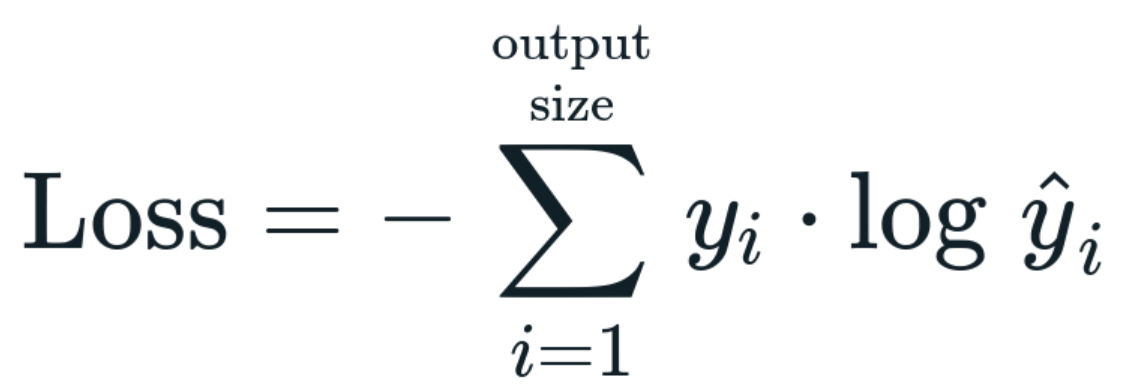Hey all,
I am training my highly imbalanced sentiment classification dataset using transformers’ library’s ELECTRA(similar to BERT) model by appending a classification head on top of it. The dataset has 5 classes. And I logging the loss every 10 steps.
The imbalance dataset stats are as follows:
The number of 1 labels: 135
The number of 2 labels: 43
The number of 3 labels: 74
The number of 4 labels: 303
The number of 5 labels: 2242
The batch_size I am using is 16.
The
The problem I am facing is the training loss I am encountering is starts from 1.5, which reduces to about 0.7.
Following are the doubts I have:
Is it theoretically possible to have loss output from nn.CrossEntropyLoss >1?
Also I thought loss output comes in terms of %, so how am I supposed to interpret this loss which starts with greater than 1 value?
its is , it just gives you -(summation (log(p_i))) where p_i is the confidence in the prediction of i’th class , so in theory since natural log function is bound from 0 to - inf between 0 and 1 (since we are taking a negative of that ) the cross entory function is bound between 0 to inf
First of all, Thanks for the replies.
Also then, what do you all suggest I should Log in the logger to plot, the Cross entropy loss coming from the network , or use calculate precision, recall by hand and plot it? @archit-spec@Mah_Neh
Specifically , I want to report that the model is learning, what loss/metric should I report?
Oh no, just from categorical/classification point of view u can answer. I am doing simple sentiment analysis which is just classification.
So, I should calculate the accuracy of the predictions using the target(output from model) and predicted labels, is this what you are saying? Please clarify .Thanks again.