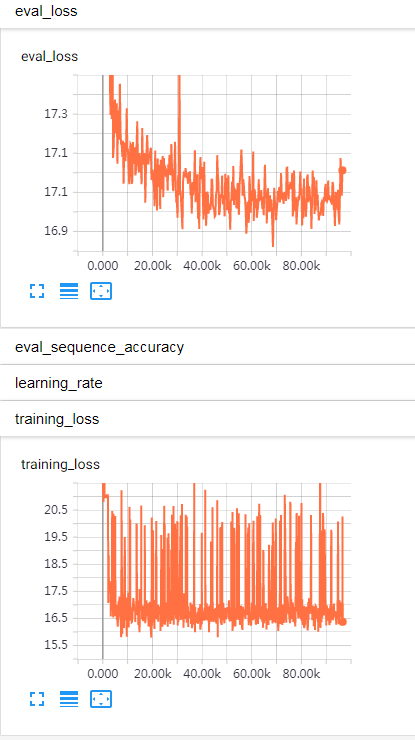
I’m trying to train a captcha recognition model. Model details are resnet pretrained CNN layers + Bidirectional LSTM + Fully Connected. It reached 90% sequence accuracy on captcha generated by python library captcha. The problem is that these generated captcha seems to have similary location of each character. When I randomly add spaces between characters, the model does not work any more. So I wonder is LSTM learning segmentation during training? Then I try to use CTC loss. At first, loss goes down pretty quick. But it stays at about 16 without significant drop later. I tried different layers of LSTM, different number of units. 2 Layers of LSTM reach lower loss, but still not converging. 3 layers are just like 2 layers. The loss curve:
#encoding:utf8
import os
import sys
import torch
import warpctc_pytorch
import traceback
import torchvision
from torch import nn, autograd, FloatTensor, optim
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import MultiStepLR
from tensorboard import SummaryWriter
from pprint import pprint
from net.utils import decoder
from logging import getLogger, StreamHandler
logger = getLogger(__name__)
handler = StreamHandler(sys.stdout)
logger.addHandler(handler)
from dataset_util.utils import id_to_character
from dataset_util.transform import rescale, normalizer
from config.config import MAX_CAPTCHA_LENGTH, TENSORBOARD_LOG_PATH, MODEL_PATH
class CNN_RNN(nn.Module):
def __init__(self, lstm_bidirectional=True, use_ctc=True, *args, **kwargs):
super(CNN_RNN, self).__init__(*args, **kwargs)
model_conv = torchvision.models.resnet18(pretrained=True)
for param in model_conv.parameters():
param.requires_grad = False
modules = list(model_conv.children())[:-1] # delete the last fc layer.
for param in modules[8].parameters():
param.requires_grad = True
self.resnet = nn.Sequential(*modules) # CNN with fixed parameters from resnet as feature extractor
self.lstm_input_size = 512 * 2 * 2
self.lstm_hidden_state_size = 512
self.lstm_num_layers = 2
self.chracter_space_length = 64
self._lstm_bidirectional = lstm_bidirectional
self._use_ctc = use_ctc
if use_ctc:
self._max_captcha_length = int(MAX_CAPTCHA_LENGTH * 2)
else:
self._max_captcha_length = MAX_CAPTCHA_LENGTH
if lstm_bidirectional:
self.lstm_hidden_state_size = self.lstm_hidden_state_size * 2 # so that hidden size for one direction in bidirection lstm is the same as vanilla lstm
self.lstm = self.lstm = nn.LSTM(self.lstm_input_size, self.lstm_hidden_state_size // 2, dropout=0.5, bidirectional=True, num_layers=self.lstm_num_layers)
else:
self.lstm = nn.LSTM(self.lstm_input_size, self.lstm_hidden_state_size, dropout=0.5, bidirectional=False, num_layers=self.lstm_num_layers) # dropout doen't work for one layer lstm
self.ouput_to_tag = nn.Linear(self.lstm_hidden_state_size, self.chracter_space_length)
self.tensorboard_writer = SummaryWriter(TENSORBOARD_LOG_PATH)
# self.dropout_lstm = nn.Dropout()
def init_hidden_status(self, batch_size):
if self._lstm_bidirectional:
self.hidden = (autograd.Variable(torch.zeros((self.lstm_num_layers * 2, batch_size, self.lstm_hidden_state_size // 2))),
autograd.Variable(torch.zeros((self.lstm_num_layers * 2, batch_size, self.lstm_hidden_state_size // 2)))) # number of layers, batch size, hidden dimention
else:
self.hidden = (autograd.Variable(torch.zeros((self.lstm_num_layers, batch_size, self.lstm_hidden_state_size))),
autograd.Variable(torch.zeros((self.lstm_num_layers, batch_size, self.lstm_hidden_state_size)))) # number of layers, batch size, hidden dimention
def forward(self, image):
'''
:param image: # batch_size, CHANNEL, HEIGHT, WIDTH
:return:
'''
features = self.resnet(image) # [batch_size, 512, 2, 2]
batch_size = image.shape[0]
features = [features.view(batch_size, -1) for i in range(self._max_captcha_length)]
features = torch.stack(features)
self.init_hidden_status(batch_size)
output, hidden = self.lstm(features, self.hidden)
# output = self.dropout_lstm(output)
tag_space = self.ouput_to_tag(output.view(-1, output.size(2))) # [MAX_CAPTCHA_LENGTH * BATCH_SIZE, CHARACTER_SPACE_LENGTH]
tag_space = tag_space.view(self._max_captcha_length, batch_size, -1)
if not self._use_ctc:
tag_score = F.log_softmax(tag_space, dim=2) # [MAX_CAPTCHA_LENGTH, BATCH_SIZE, CHARACTER_SPACE_LENGTH]
else:
tag_score = tag_space
return tag_score
def train_net(self, data_loader, eval_data_loader=None, learning_rate=0.008, epoch_num=400):
try:
if self._use_ctc:
loss_function = warpctc_pytorch.warp_ctc.CTCLoss()
else:
loss_function = nn.NLLLoss()
# optimizer = optim.SGD(filter(lambda p: p.requires_grad, self.parameters()), momentum=0.9, lr=learning_rate)
# optimizer = MultiStepLR(optimizer, milestones=[10,15], gamma=0.5)
# optimizer = optim.Adadelta(filter(lambda p: p.requires_grad, self.parameters()))
optimizer = optim.Adam(filter(lambda p: p.requires_grad, self.parameters()))
self.tensorboard_writer.add_scalar("learning_rate", learning_rate)
tensorbard_global_step=0
if os.path.exists(os.path.join(TENSORBOARD_LOG_PATH, "resume_step")):
with open(os.path.join(TENSORBOARD_LOG_PATH, "resume_step"), "r") as file_handler:
tensorbard_global_step = int(file_handler.read()) + 1
for epoch_index, epoch in enumerate(range(epoch_num)):
for index, sample in enumerate(data_loader):
optimizer.zero_grad()
input_image = autograd.Variable(sample["image"]) # batch_size, 3, 255, 255
tag_score = self.forward(input_image)
if self._use_ctc:
tag_score, target, tag_score_sizes, target_sizes = self._loss_preprocess_ctc(tag_score, sample)
loss = loss_function(tag_score, target, tag_score_sizes, target_sizes)
loss = loss / tag_score.size(1)
else:
target = sample["padded_label_idx"]
tag_score, target = self._loss_preprocess(tag_score, target)
loss = loss_function(tag_score, target)
print("Training loss: {}".format(float(loss)))
self.tensorboard_writer.add_scalar("training_loss", float(loss), tensorbard_global_step)
loss.backward()
optimizer.step()
if index % 250 == 0:
print(u"Processing batch: {} of {}, epoch: {}".format(index, len(data_loader), epoch_index))
self.evaluate(eval_data_loader, loss_function, tensorbard_global_step)
tensorbard_global_step += 1
self.save_model(MODEL_PATH + "_epoch_{}".format(epoch_index))
except KeyboardInterrupt:
print("Exit for KeyboardInterrupt, save model")
self.save_model(MODEL_PATH)
with open(os.path.join(TENSORBOARD_LOG_PATH, "resume_step"), "w") as file_handler:
file_handler.write(str(tensorbard_global_step))
except Exception as excp:
logger.error(str(excp))
logger.error(traceback.format_exc())
def predict(self, image):
# TODO ctc version
'''
:param image: [batch_size, channel, height, width]
:return:
'''
tag_score = self.forward(image)
# TODO ctc
# if self._use_ctc:
# tag_score = F.softmax(tag_score, dim=-1)
# decoder.decode(tag_score)
confidence_log_probability, indexes = tag_score.max(2)
predicted_labels = []
for batch_index in range(indexes.size(1)):
label = ""
for character_index in range(self._max_captcha_length):
if int(indexes[character_index, batch_index]) != 1:
label += id_to_character[int(indexes[character_index, batch_index])]
predicted_labels.append(label)
return predicted_labels, tag_score
def predict_pil_image(self, pil_image):
try:
self.eval()
processed_image = normalizer(rescale({"image": pil_image}))["image"].view(1, 3, 255, 255)
result, tag_score = self.predict(processed_image)
self.train()
except Exception as excp:
logger.error(str(excp))
logger.error(traceback.format_exc())
return [""], None
return result, tag_score
def evaluate(self, eval_dataloader, loss_function, step=0):
total = 0
sequence_correct = 0
character_correct = 0
character_total = 0
loss_total = 0
batch_size = eval_data_loader.batch_size
true_predicted = {}
self.eval()
for sample in eval_dataloader:
total += batch_size
input_images = sample["image"]
predicted_labels, tag_score = self.predict(input_images)
for predicted, true_label in zip(predicted_labels, sample["label"]):
if predicted == true_label: # dataloader is making label a list, use batch_size=1
sequence_correct += 1
for index, true_character in enumerate(true_label):
character_total += 1
if index < len(predicted) and predicted[index] == true_character:
character_correct += 1
true_predicted[true_label] = predicted
if self._use_ctc:
tag_score, target, tag_score_sizes, target_sizes = self._loss_preprocess_ctc(tag_score, sample)
loss_total += float(loss_function(tag_score, target, tag_score_sizes, target_sizes) / batch_size)
else:
tag_score, target = self._loss_preprocess(tag_score, sample["padded_label_idx"])
loss_total += float(loss_function(tag_score, target)) # averaged over batch index
print("True captcha to predicted captcha: ")
pprint(true_predicted)
self.tensorboard_writer.add_text("eval_ture_to_predicted", str(true_predicted), global_step=step)
accuracy = float(sequence_correct) / total
avg_loss = float(loss_total) / (total / batch_size)
character_accuracy = float(character_correct) / character_total
self.tensorboard_writer.add_scalar("eval_sequence_accuracy", accuracy, global_step=step)
self.tensorboard_writer.add_scalar("eval_character_accuracy", character_accuracy, global_step=step)
self.tensorboard_writer.add_scalar("eval_loss", avg_loss, global_step=step)
self.zero_grad()
self.train()
def _loss_preprocess(self, tag_score, target):
'''
:param tag_score: value return by self.forward
:param target: sample["padded_label_idx"]
:return: (processed_tag_score, processed_target) ready for NLLoss function
'''
target = target.transpose(0, 1)
target = target.contiguous()
target = target.view(target.size(0) * target.size(1))
tag_score = tag_score.view(-1, self.chracter_space_length)
return tag_score, target
def _loss_preprocess_ctc(self, tag_score, sample):
target_2d = [
[int(ele) for ele in sample["padded_label_idx"][row, :] if int(ele) != 0 and int(ele) != 1]
for row in range(sample["padded_label_idx"].size(0))]
target = []
for ele in target_2d:
target.extend(ele)
target = autograd.Variable(torch.IntTensor(target))
# tag_score = F.softmax(F.sigmoid(tag_score), dim=-1)
tag_score_sizes = autograd.Variable(torch.IntTensor([self._max_captcha_length] * tag_score.size(1)))
target_sizes = autograd.Variable(sample["captcha_length"].int())
return tag_score, target, tag_score_sizes, target_sizes
# def visualize_graph(self, dataset):
# '''Since pytorch use dynamic graph, an input is required to visualize graph in tensorboard'''
# # warning: Do not run this, the graph is too large to visualize...
# sample = dataset[0]
# input_image = autograd.Variable(sample["image"].view(1, 3, 255, 255))
# tag_score = self.forward(input_image)
# self.tensorboard_writer.add_graph(self, tag_score)
def save_model(self, model_path):
self.tensorboard_writer.close()
self.tensorboard_writer = None # can't be pickled
torch.save(self, model_path)
self.tensorboard_writer = SummaryWriter(TENSORBOARD_LOG_PATH)
@classmethod
def load_model(cls, model_path=MODEL_PATH, *args, **kwargs):
net = cls(*args, **kwargs)
if os.path.exists(model_path):
model = torch.load(model_path)
if model:
model.tensorboard_writer = SummaryWriter(TENSORBOARD_LOG_PATH)
net = model
return net
def __del__(self):
if self.tensorboard_writer:
self.tensorboard_writer.close()
if __name__ == "__main__":
from dataset_util.dataset import dataset, eval_dataset
data_loader = DataLoader(dataset, batch_size=2, shuffle=True)
eval_data_loader = DataLoader(eval_dataset, batch_size=2, shuffle=True)
net = CNN_RNN.load_model()
net.train_net(data_loader, eval_data_loader=eval_data_loader)
# net.predict(dataset[0]["image"].view(1, 3, 255, 255))
# predict_pil_image test code
# from config.config import IMAGE_PATHS
# import glob
# from PIL import Image
#
# image_paths = glob.glob(os.path.join(IMAGE_PATHS.get("EVAL"), "*.png"))
# for image_path in image_paths:
# pil_image = Image.open(image_path)
# predicted, score = net.predict_pil_image(pil_image)
# print("True value: {}, predicted: {}".format(os.path.split(image_path)[1], predicted))
print("Done")
The above codes are main part. If you need other components that makes it running, leave a comment. Got stuck here for quite long. Any advice for training crnn + ctc is appreciated.