Can someone guide me the proper installation of cuda, tensorflow and pytorch from beginning with proper compatible versions for my local machine. And which python-version, so that its packages should be compatible with cuda, torch and tensorflow.
±--------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| No running processes found |
±--------------------------------------------------------------------------------------+
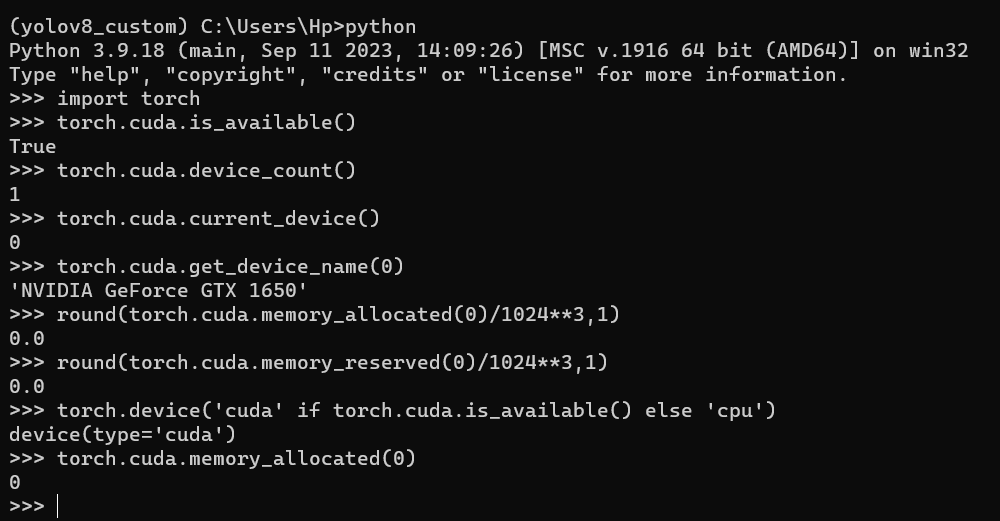
Your GTX 1650, with a compute capability of 7.5, is supported in all currently released PyTorch binaries and you can install the stable or nightly release from here.
You would only need to install an NVIDIA driver (which seems to be the case already) as the binaries ship with their own CUDA dependencies.
Sorry, but I’m not familiar enough with your Windows environment and don’t know what might be causing the issue. I would start by checking which environment is used and that the same python.exe from the same PyTorch env is used.
yeah i’ve resolved the issue of compatibility but another issue i’m having:-
E torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 308.00 MiB (GPU 0; 4.00 GiB total capacity; 5.51 GiB already allocated; 0 bytes free; 5.79 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
can you help me in resolving this error? i can’t figure out how to use less memory
You would need to reduce the batch size or use a smaller model to reduce the memory usage.
Alternatively, you could also check torch.utils.checkpoint to trade compute for memory.
you first create an environment in conda with the required python version mostly 3.8.* and then pip3 install instead of conda install inside the environment and then you can use the environment as your python interpreter will use the torch GPU as your kernel in running the program
Hey everyone,
I am a fresher. I was trying to do model training of Yolov8m model on my system, that has a GTX 1650. Cuda 12.1 was installed with pytorch and its showing when I do the version check, but still while training the model it is not supporting and the loss values are ‘nan’ and map values are 0. I even tried installing the cuda toolkit 12.3 from Nvidia, still no good. I even tried installing cuda 11.8, still same issue.
Can someone please guide me what the problem is and how I can solve it.
Thank you.
Your locally installed CUDA toolkit won’t be used as PyTorch ships with its own CUDA runtime dependencies. Why do you assume it’s any kind of compatibility issues and not broken training code, as is usually the case when NaN values are returned?
Sorry but I am a fresher. When with the same code I tried it on google colab and it worked and the yolo model was trained. But when I am using that code through my system kernel, the model is returning ‘NaN’ values.
The data is an image set of 178 images with multiple bounding boxes and I am using yolov8m with 100 epochs and batch size of 4. The same I did with colab and cuda 11.8, it ran and was successful. But when I created an environment and installed pytorch and cuda 11.8 on my personal laptop, it was not working. I tried installing cuda older versions, but pytorch didn’t support that. Today, I tried installing pytorch and cuda 11.8 on my friend’s laptop which has rtx 2080, it worked. All this time the same dataset, annotations and .py files were used. So, I wanted to know more about what the problem is and how it can be resolved.
Can you please guide me, how to allocate and reserve memory. It will be very helpful to me.
Yesterday after the conversation with you, I created a tensor. Its showing allocated but reserved is still 0.
Only mention of 1650ti one. I also tried by installing multiple versions of cuda, subsequently installing pytorch with relevant commands. But gpu was not showing. Then I checked above link.