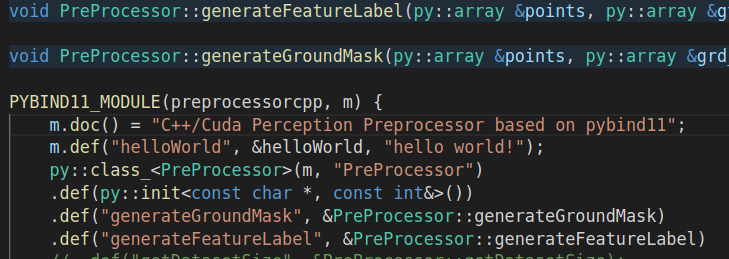
A cuda preprocessor with pybind11 is implemented and imported in Dataloader. DDP with multi-process is used for multi-gpus training(one machine). I find once I increase the num_workers(keep everything else frozen), the gpu 0 is occupied more, leading to gpu 0’s capabilty become the limit of the overall training speed.
Is it possible to move some cuda calculations within the preprocessor to other gpus?
I don’t know what exactly the “cuda preprocessor with pybind11” is doing in the DataLoader and how it’s implemented, but I would guess you are recreating new CUDA contexts on the default device (GPU0) and are thus increasing the memory usage. Try to use the corresponding GPU used in the DDP process to perform your GPU calculations in the DataLoader.
Finnally, The preprocessorcpp.so is imported and initialized in Dataset and its member func is called in getitem
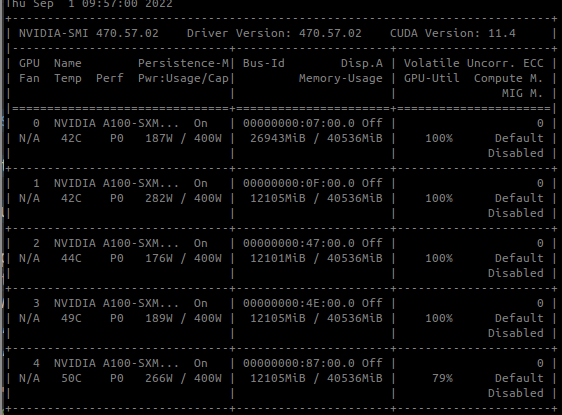
The DDP is used and it seems all the preprocessor’s cuda calculations is applied on gpu0:
GPU0’s memory is heavily used and some of the GPUs(e.g., gppu4) is not 100% of the GPU-Util collumn.
The DDP part is basically following the tutorial here. I do use rank to specify GPU ID for model and input data’s GPU, but it seems not working within the dataloader?
No, it’s not normal or expected and I would still guess that your extension is initializing a new CUDA context in each process on the default device.
Each rank will use a corresponding device as explained in the linked tutorial.
(E.g. see the print(f"Running basic DDP example on rank {rank}.") statement which prints the current rank) You should check what your extension is exactly doing and try to avoid initializing the default GPU0.
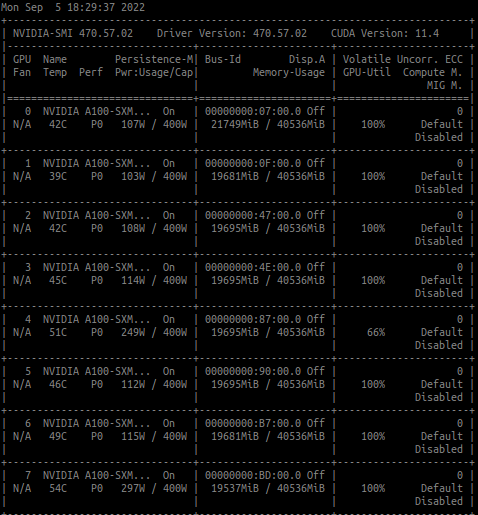
You are correct. It seems pytorch’s DDP cant take care of the c++/cuda extensions’ device id.
So I pass the rank as a param to the c++/cuda preprocessor and mannuly set the cuda device ID for each instance of the c++/cuda preprocessor class.
Following Nvidia’s official multi-gpu example: here, everything seems fine now.