I am trying to train a model that uses pixels as data samples.
Because the dataset is small, i am trying to keep the entire dataset on the GPU.
When timing the run of the model, the first 5 iterations are fast, but then it slows down drastically:
The first iterations is slow due to “cold start”, then the next 4 are fast, and the next ones are vary slow.
If i keep the data on the CPU, and move the batch to the GPU one batch at a time, the model runs at full speed all the time, but the time it takes to move the tensors is too long.
If i keep the data on the GPU, but after every iteration i call torch.cuda.empty_cache() the model runs at full speed, but empty_cache takes 1.25 seconds …
I tried to detach and clone the batch before using the forward pass, it did nothing.
what could be the cause of this problem. and how could it be fixed ?
I would appreciate any advice
This is interesting. Could you post a code snippet to reproduce this issue? You don’t need to include actual data (e.g., use random tensor(s) in place of your dataset) as that should not affect the performance issue here.
import torch
import torch.nn as nn
import numpy as np
from time import time
from torch.utils.data import Dataset, DataLoader
class NerfIntegrator:
def __call__(self, rgb_values, sigma_values, interval_sizes):
# the format of rgb_values is [...,number_of_samples,3]
# the format if sigma_values is [...,number_of_samples,1]
# where ... represents any amount of dimensions
# the integral of sigma
scaled_sigma = sigma_values * interval_sizes
T_t = torch.exp(-torch.cumsum(scaled_sigma, dim=-1))
colors = ((T_t * (1 - torch.exp(-scaled_sigma))).unsqueeze(-1) * rgb_values).sum(dim=-2)
return colors
class ClassicalMLP(nn.Module):
def __init__(self, number_of_inputs, number_of_outputs, layers_size, number_of_layers, activition_function=nn.ReLU):
super().__init__()
layers_channels = [number_of_inputs] + [layers_size for _ in
range(number_of_layers)] + [number_of_outputs]
layers = []
for i, (input, output) in enumerate(zip(layers_channels[:-1], layers_channels[1:])):
layers += [nn.Linear(input, output)]
if i != len(layers_channels) - 2:
layers += [activition_function()]
self.mlp = nn.Sequential(*layers)
def forward(self, sampling_locations):
return self.mlp(sampling_locations)
class nerf_mlp(nn.Module):
def __init__(self):
super().__init__()
self.sigma_mlp = ClassicalMLP(3,
256 + 1,
256,
5)
self.rgb_mlp = ClassicalMLP(256 + 3,
3,
256,
5)
def forward(self, sampling_locations, directions):
sigma_plus_feature_vector = self.sigma_mlp.forward(sampling_locations)
sigma_values = (sigma_plus_feature_vector[..., 0]).abs()
feature_vector = sigma_plus_feature_vector[..., 1:]
rgb_input = torch.cat([feature_vector, directions], dim=-1)
rgb_values = torch.tanh(self.rgb_mlp.forward(rgb_input).abs())
return_values = torch.cat([sigma_values.unsqueeze(-1), rgb_values], dim=-1)
return return_values
class Nerf3DModel(torch.nn.Module):
def __init__(self):
super().__init__()
self.integrator = NerfIntegrator()
self.coarse_mlp = nerf_mlp()
self.fine_mlp = nerf_mlp()
def evaluate_color_from_rays(self, network_values_at_samples, interval_sizes):
rgb_values = network_values_at_samples[..., 1:4]
sigma_values = network_values_at_samples[..., 0]
colors = self.integrator(rgb_values, sigma_values, interval_sizes)
return colors, sigma_values
def forward(self, input_x):
rays = input_x["ray_directions"]
camera_positions = input_x["camera_origin"]
rays = rays / rays.norm(dim=-1, keepdim=True)
# i replaced sampler netwroks with tensors of ones, to simplify the code
# the problem presists
shape = list(rays.shape)
shape = shape[:-1] + [64] + [shape[-1]]
coarse_sampling_locations = torch.ones(shape, device=rays.device)
sampling_start = torch.ones(shape, device=rays.device)
sampling_end = torch.ones(shape, device=rays.device)
coarse_interval_sizes = torch.ones(shape[:-1], device=rays.device)
repeats = [1] * (len(coarse_sampling_locations.shape) - 2) + [coarse_sampling_locations.shape[-2]] + [1]
coarse_directions = rays.unsqueeze(-2).repeat(repeats)
network_values_at_samples = self.coarse_mlp(coarse_sampling_locations, coarse_directions)
# the first 3 outputs of the DNN are the rgb channels and the last one is
# the sigma channel
resulting_coarse_image, sigma_values = self.evaluate_color_from_rays(network_values_at_samples,
coarse_interval_sizes)
shape[-2] = 192
fine_sampling_points = torch.ones(shape, device=rays.device)
fine_interval_sizes = torch.ones(shape[:-1], device=rays.device)
repeats = [1]*(len(rays.shape) - 1) + [fine_sampling_points.shape[-2]] + [1]
fine_directions = rays.unsqueeze(-2).repeat(repeats)
network_values_at_fine_samples = self.fine_mlp(fine_sampling_points, fine_directions)
resulting_fine_image, _ = self.evaluate_color_from_rays(network_values_at_fine_samples, fine_interval_sizes)
network_output = {
"rgb_coarse": resulting_coarse_image,
"rgb_fine": resulting_fine_image,
"rays": rays,
"camera_positions": camera_positions,
"sampling_locations_coarse": coarse_sampling_locations,
"fine_sampling_locations": fine_sampling_points,
}
return network_output
class LossFunction(nn.Module):
def forward(self, input_batch, prediction):
gb_rgb = input_batch["rgb"]
predication_rgb_coarse = prediction["rgb_coarse"]
predication_rgb_fine = prediction["rgb_fine"]
coarse_rgb_loss = (gb_rgb - predication_rgb_coarse).norm(dim=-1).mean()
fine_rgb_loss = (gb_rgb - predication_rgb_fine).norm(dim=-1).mean()
return_value = coarse_rgb_loss + fine_rgb_loss
return {"loss_value": return_value, "coarse_rgb_loss":coarse_rgb_loss, "fine_rgb_loss":fine_rgb_loss}
class RandomDataset(Dataset):
def __init__(self):
super().__init__()
self.data = [{
"rgb": torch.rand(800, 800, 3).cuda().reshape(-1, 3),
"ray_directions": torch.rand(800, 800, 3).cuda().reshape(-1, 3),
"camera_origin": torch.rand(1, 3).cuda(),
} for _ in range(10)]
self.sample_length = self.data[0]["rgb"].shape[0]
self.chunk_size = 1024
self.chunks_per_sample = int(np.ceil(self.sample_length / self.chunk_size))
self.length = self.chunks_per_sample * len(self.data)
def __len__(self):
return self.length
def __getitem__(self, idx):
sample_index = idx // self.chunks_per_sample
batch_index = idx % self.chunks_per_sample
sample = self.data[sample_index]
start = batch_index * self.chunk_size
end = (batch_index + 1) * self.chunk_size
end = min(end, self.sample_length)
pixel_keys = ["rgb","ray_directions"]
chunk = {
key: sample[key][start:end] for key in pixel_keys
}
chunk["camera_origin"] = sample["camera_origin"]
return chunk
if __name__ == '__main__':
dataset = RandomDataset()
data_loader = DataLoader(dataset, batch_size=1)
device = torch.device("cuda")
model = Nerf3DModel().to(device)
loss_function = LossFunction()
optimizer = torch.optim.Adam(model.parameters())
for epoch in range(1000):
for batch in data_loader:
t1 = time()
optimizer.zero_grad()
pred = model(batch)
loss = loss_function(batch,pred)
loss["loss_value"].backward()
optimizer.step()
print(time() - t1)
this coda example shows the problem.
i am running on GTX 3090. so if there is not enough sapce on the gpu, you can change
“chunk size” in the dataset to smothing smaller then 1024
the code printed:
0.6795637607574463
0.01598954200744629
0.007995367050170898
0.01598811149597168
0.00799417495727539
0.10390162467956543
0.19186925888061523
0.17587995529174805
0.18573331832885742
0.16800951957702637
0.19200444221496582
0.16811847686767578
0.19177031517028809
0.1763777732849121
as you can see, the first iterations are fast, but then come the slowdown
CUDA operations are executed asynchronously and based on your description and code snippet it seems you are not synchronizing the code, which could yield wrong results (and e.g. only profile the kernel launches until a sync is automatically added).
Add torch.cuda.synchronize() before starting and stopping the timer and compare the results again.
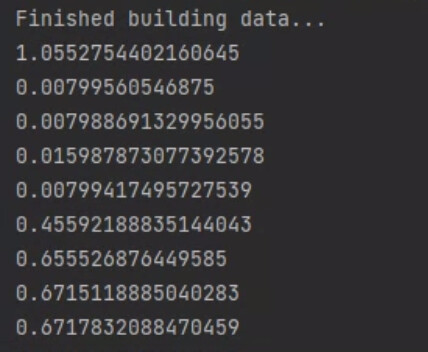
thank you ! now when timing the code, every iteration takes the same amount of time,
but there is one thing i don’t understand, if i do not synchronize cuda, when i reach the line
print(time() - t1)
all the computations must be complete, as i already called backward and optimizer.step and so on …
in order to reach this line, all the computations must be complete, so how come it is sometimes faster and sometimes slower ?
is the pytorch code evaluated lazily ? meaning if i call some cuda operation before another is complete it is added to some queue ?
No, the CUDA operations will be added to a queue and launched when they are ready, while the CPU can run ahead and execute the next operations until a synchronization is reached (e.g. if a GPU result is needed on the CPU).
I wouldn’t call it lazy evaluation, but asynchronous execution instead. Lazy execution often refers to creating a (graph of) operations and start the execution when a result is needed (which is used in the PyTorch/XLA backend, if I’m not mistaken).