Hi,
Apologies if this is solved somewhere, I’ve googled around but I can’t figure out what to do.
I have 2.2.2 in a conda environment on a linux machine, installed via
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
I have following nvidia-smi:
Tue Apr 9 03:35:46 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.54.03 Driver Version: 535.54.03 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA A100 80GB PCIe Off | 00000000:31:00.0 Off | On |
| N/A 67C P0 252W / 300W | 791MiB / 81920MiB | N/A Default |
| | | Enabled |
+-----------------------------------------+----------------------+----------------------+
| 1 NVIDIA A100 80GB PCIe Off | 00000000:4B:00.0 Off | On |
| N/A 67C P0 251W / 300W | 739MiB / 81920MiB | N/A Default |
| | | Enabled |
+-----------------------------------------+----------------------+----------------------+
| 2 NVIDIA A100 80GB PCIe Off | 00000000:B1:00.0 Off | On |
| N/A 34C P0 45W / 300W | 87MiB / 81920MiB | N/A Default |
| | | Enabled |
+-----------------------------------------+----------------------+----------------------+
| 3 NVIDIA A100 80GB PCIe Off | 00000000:CA:00.0 Off | On |
| N/A 34C P0 42W / 300W | 87MiB / 81920MiB | N/A Default |
| | | Enabled |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| MIG devices: |
+------------------+--------------------------------+-----------+-----------------------+
| GPU GI CI MIG | Memory-Usage | Vol| Shared |
| ID ID Dev | BAR1-Usage | SM Unc| CE ENC DEC OFA JPG |
| | | ECC| |
|==================+================================+===========+=======================|
| 0 0 0 0 | 751MiB / 81050MiB | 98 0 | 7 0 5 1 1 |
| | 5MiB / 131072MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 1 0 0 0 | 725MiB / 81050MiB | 98 0 | 7 0 5 1 1 |
| | 5MiB / 131072MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 2 7 0 0 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 2 8 0 1 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 2 9 0 2 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 2 10 0 3 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 2 11 0 4 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 2 12 0 5 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 2 13 0 6 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 3 7 0 0 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 3 8 0 1 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 3 9 0 2 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 3 11 0 3 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 3 12 0 4 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 3 13 0 5 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
| 3 14 0 6 | 12MiB / 9728MiB | 14 0 | 1 0 0 0 0 |
| | 0MiB / 16383MiB | | |
+------------------+--------------------------------+-----------+-----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 0 0 1877752 C ...odinger2024-1/internal/bin/gdesmond 686MiB |
| 1 0 0 1877801 C ...odinger2024-1/internal/bin/gdesmond 686MiB |
+---------------------------------------------------------------------------------------+
In my python interperter I get:
>>> torch.__version__
'2.2.2'
>>> torch.cuda.is_available()
True
But, if I run:
>>> torch.cuda.current_device()
# long traceback
RuntimeError: device >= 0 && device < num_gpus INTERNAL ASSERT FAILED at "/opt/conda/conda-bld/pytorch_1711403380481/work/aten/src/ATen/cuda/CUDAContext.cpp":50, please report a bug to PyTorch. device=1, num_gpus=
# long traceback
I will put the full error below. I am not sure what to do here? I used to run some models with tensorflow that required me to do something like
export CUDA_VISIBLE_DEVICES=MIG-e343b8ed-9408-52cc-90b7-683cf8ec07f0
Before I could run any jobs, usually in a format like this, inside a .sh script:
export CUDA_VISIBLE_DEVICES=MIG-8ad5411d-a2b7-5a4c-9d7e-d973c6c03b08
source activate dd-nvi
python -u progressive_docking_2.py
I tried to do the same thing here, in terminal I passed:
export CUDA_VISIBLE_DEVICES=MIG-e343b8ed-9408-52cc-90b7-683cf8ec07f0
Then echo:
echo $CUDA_VISIBLE_DEVICES
MIG-e343b8ed-9408-52cc-90b7-683cf8ec07f0
Now I could run
>>> import torch
>>> torch.cuda.is_available()
True
>>> torch.cuda.current_device()
0
>>> torch.cuda.get_device_name(0)
'NVIDIA A100 80GB PCIe MIG 1g.10gb'
This all looks correct. I can now move a tensor to device:
>>> X_train = torch.FloatTensor([0., 1., 2.])
>>> X_train = X_train.to("cuda")
However, I can seem to actually use this environment in a jupyter notebook on this server, because I get the error regarding CUDA call failed. I’ve tried setting stuff like this
!export CUDA_VISIBLE_DEVICES=MIG-e343b8ed-9408-52cc-90b7-683cf8ec07f0
But it doesn’t seem to do anything as I can’t echo it back (but I can echo test, see the space between them in the output, indicating $CUDA_VISIBLE_DEVICES is empty.)
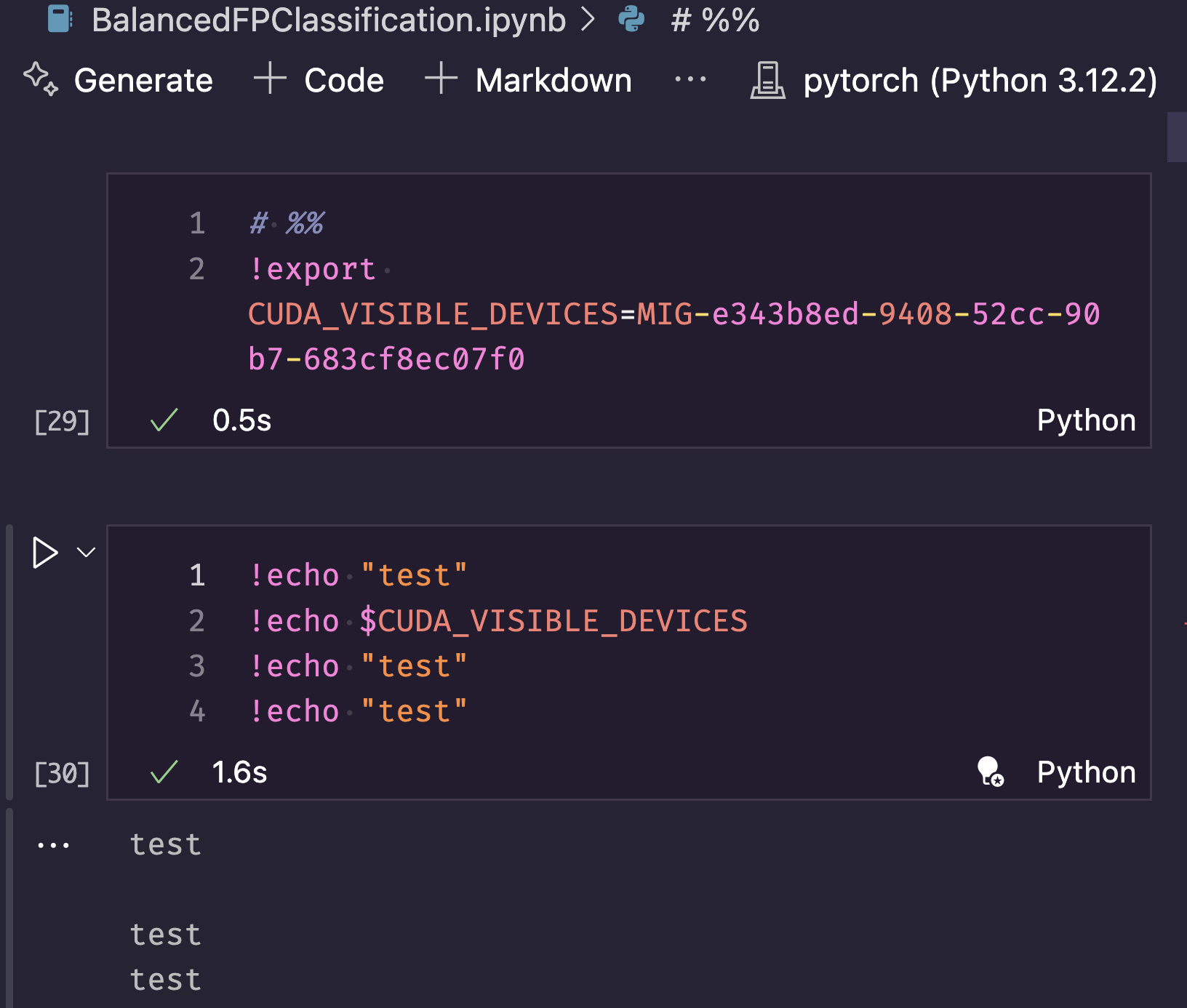
And so now when I get to the part of my code that does something with CUDA, it fails with that same CUDA call failed error
(edit: I can only embed one image so I guess I can’t share that line, I am doing this):
X_train = X_train.to(device)
X_test = X_test.to(device)
y_train = y_train.float().to(device)
y_test = y_test.float().to(device)
RuntimeError: device >= 0 && device < num_gpus INTERNAL ASSERT FAILED at "/opt/conda/conda-bld/pytorch_1711403380481/work/aten/src/ATen/cuda/CUDAContext.cpp":50, please report a bug to PyTorch. device=1, num_gpus= The above exception was the direct cause of the following exception: DeferredCudaCallError Traceback (most recent call last) Cell In[27], [line 3](vscode-notebook-cell:?execution_count=27&line=3) [1](vscode-notebook-cell:?execution_count=27&line=1) # %% ----> [3](vscode-notebook-cell:?execution_count=27&line=3) X_train = X_train.to(device) [4](vscode-notebook-cell:?execution_count=27&line=4) X_test = X_test.to(device) [5](vscode-notebook-cell:?execution_count=27&line=5) y_train = y_train.float().to(device)
I am really stuck as to what I am supposed to do here. I tried to be thorough about following a bunch of tutorials before getting here and my models are running (slowly) on my local Mac using MPS. I’ve gotten TensorFlow to work on this server before so I have a little experience but out of ideas.