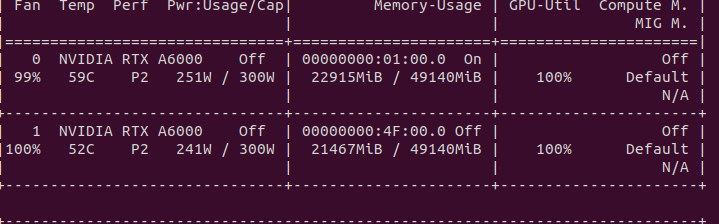
I’m not quite sure how a “memory violation” is triggered. How can I intentionally trigger such a memory violation? Just trying to figure out if I am hunting for a bug in my code or some pytorch library.
Here is the traceback of the simplified code:
torch.cuda.synchronize() # *********** THIS LINE IN TRACEBACK ***********
File “/opt/conda/lib/python3.10/site-packages/torch/cuda/init.py”, line 566, in synchronize
return torch._C._cuda_synchronize()
RuntimeError: CUDA error: an illegal memory access was encountered
The code: With lots of asserts to make sure data fed into model is ok:
class SimpleModel(pl.LightningModule):
def init(self, hparams):
super().init()
self.save_hyperparameters(hparams)
# just to make sure save_hyperparameters will create self.hparams
assert self.hparams['lr']
assert ENCODED_CHANNELS==50
self.img_to_lines_unet = unet.UNet(in_channels=1,out_channels=50, UNET_CHNLS = [32, 64, 128, 256, 512, 1024], UNET_ATTENTION=[False, False, False, False, False], bilinear=True)
self.conv = nn.Conv2d(in_channels=50, out_channels=4, kernel_size=1)
self.criterion_line = nn.CrossEntropyLoss(reduction='none')
self.criterion_line_old = nn.BCEWithLogitsLoss(reduction='none')
def forward(self, img_in):
intermediate = self.img_to_lines_unet(img_in)
return intermediate
def common_step(self, batch, batch_idx):
image, region_mask, all_line_mask = batch
selected_line_mask = None
selected_line_img_crop = None
batch_size = image.shape[0]
assert image.shape[0]==16
assert image.shape[1]==1
assert image.shape[2]==512
assert image.shape[3]==512
torch.cuda.synchronize()
intermediate = self(image)
torch.cuda.synchronize()
assert intermediate.shape[0]==16
assert intermediate.shape[1]==50
assert intermediate.shape[2]==512
assert intermediate.shape[3]==512
torch.cuda.synchronize()
predicted_line_mask = self.conv(intermediate)
torch.cuda.synchronize()
assert predicted_line_mask.shape[0]==16
assert predicted_line_mask.shape[1]==4
assert predicted_line_mask.shape[2]==512
assert predicted_line_mask.shape[3]==512
assert all_line_mask.shape[0]==16
assert all_line_mask.shape[1]==512
assert all_line_mask.shape[2]==512
torch.cuda.synchronize()
loss1 = self.criterion_line(predicted_line_mask, all_line_mask) # reduction none, so I can mask
torch.cuda.synchronize() # *********** THIS LINE IN TRACEBACK ***********
assert loss1.shape[0] == 16
assert loss1.shape[1] == 512
assert loss1.shape[2] == 512
assert region_mask.shape[0] == 16
assert region_mask.shape[1] == 1
assert region_mask.shape[2] == 512
assert region_mask.shape[3] == 512
loss1 = loss1 * region_mask[:,0,:,:]
loss1 = loss1.sum()
return loss1, loss1
def training_step(self, batch, batch_idx):
loss, loss1 = self.common_step(batch, batch_idx)
self.log('train_loss_line', loss1)
self.log("train_loss", loss)
return loss
def validation_step(self, batch, batch_idx):
loss, loss1 = self.common_step(batch, batch_idx)
self.log('val_loss_line', loss1)
self.log('val_loss', loss)
def configure_optimizers(self):
optimizer = torch.optim.Adam(self.parameters(), lr=self.hparams['lr'])
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=self.hparams['gamma'])
return {"optimizer": optimizer, "lr_scheduler": scheduler, "monitor": "val_loss"}