I am trying to train a deep learning model on a custom dataset for semantic segmentation.
When I am trying to train on my PC, I am getting the following error.
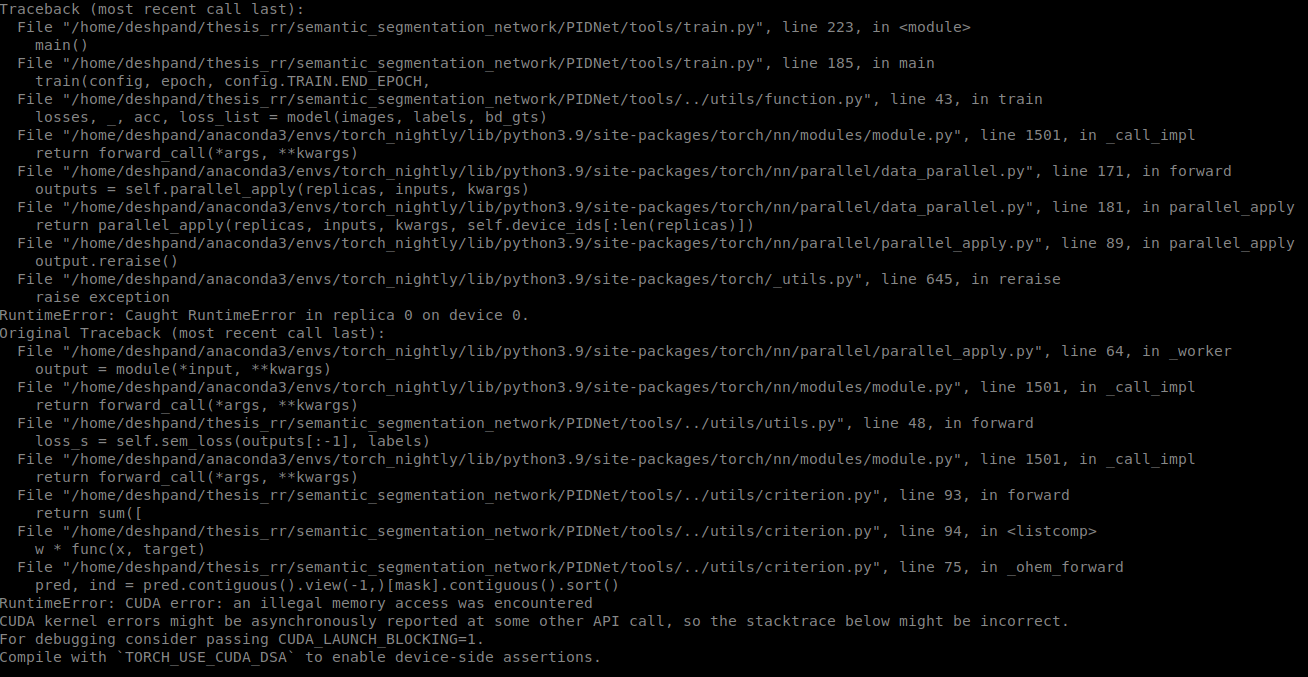
File "tools/train.py", line 223, in <module>
main()
File "tools/train.py", line 185, in main
train(config, epoch, config.TRAIN.END_EPOCH,
File "/home/deshpand/thesis_rr/semantic_segmentation_network/PIDNet/tools/../utils/function.py", line 43, in train
losses, _, acc, loss_list = model(images, labels, bd_gts)
File "/home/deshpand/anaconda3/envs/torch_env/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/home/deshpand/anaconda3/envs/torch_env/lib/python3.8/site-packages/torch/nn/parallel/data_parallel.py", line 169, in forward
return self.module(*inputs[0], **kwargs[0])
File "/home/deshpand/anaconda3/envs/torch_env/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/home/deshpand/thesis_rr/semantic_segmentation_network/PIDNet/tools/../utils/utils.py", line 48, in forward
loss_s = self.sem_loss(outputs[:-1], labels)
File "/home/deshpand/anaconda3/envs/torch_env/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1194, in _call_impl
return forward_call(*input, **kwargs)
File "/home/deshpand/thesis_rr/semantic_segmentation_network/PIDNet/tools/../utils/criterion.py", line 90, in forward
return sum([
File "/home/deshpand/thesis_rr/semantic_segmentation_network/PIDNet/tools/../utils/criterion.py", line 91, in <listcomp>
w * func(x, target)
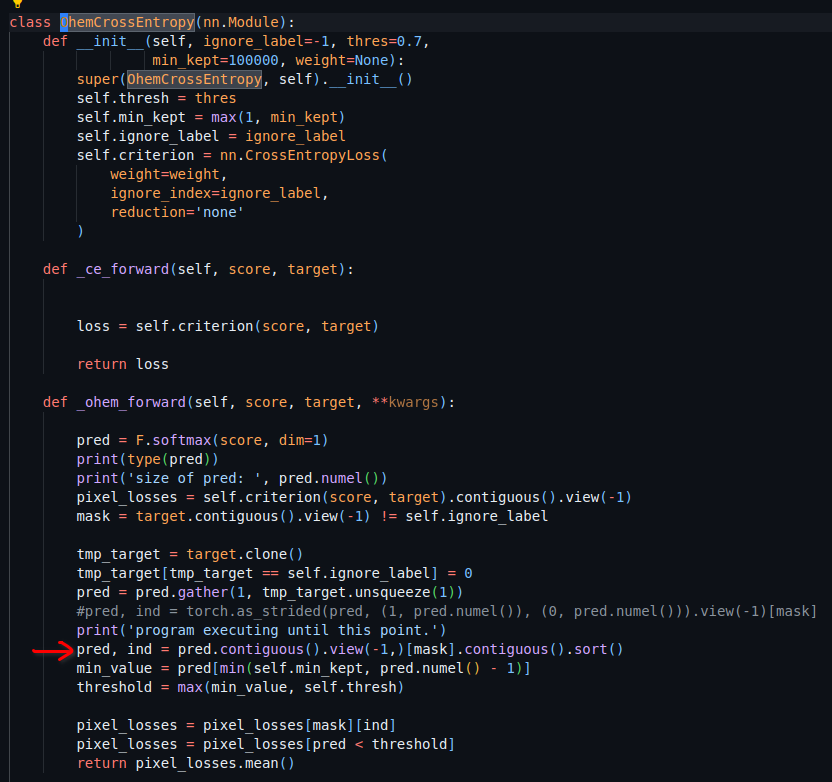
File "/home/deshpand/thesis_rr/semantic_segmentation_network/PIDNet/tools/../utils/criterion.py", line 72, in _ohem_forward
pred, ind = pred.contiguous().view(-1,)[mask].contiguous().sort()
RuntimeError: CUDA error: an illegal memory access was encountered
CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
This is the first time I have seen error like this. Can someone please explain what is going on here?
The specifications for my GPU are as follows.
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 515.86.01 Driver Version: 515.86.01 CUDA Version: 11.7 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA GeForce ... On | 00000000:01:00.0 On | N/A |
| 25% 36C P0 29W / 120W | 648MiB / 6144MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 902 G /usr/lib/xorg/Xorg 245MiB |
| 0 N/A N/A 1234 G /usr/bin/kwin_x11 123MiB |
| 0 N/A N/A 1289 G /usr/bin/plasmashell 48MiB |
| 0 N/A N/A 1481 G /usr/lib/firefox/firefox 173MiB |
| 0 N/A N/A 5801 G ...RendererForSitePerProcess 49MiB |
+-----------------------------------------------------------------------------+
I will really appreciate the help here. Also, I am using PyTorch version 1.13.1
>>> print(torch.__version__)
1.13.1
>>>
The graphics card model is GeForce GTX 1080Ti (6GB model)