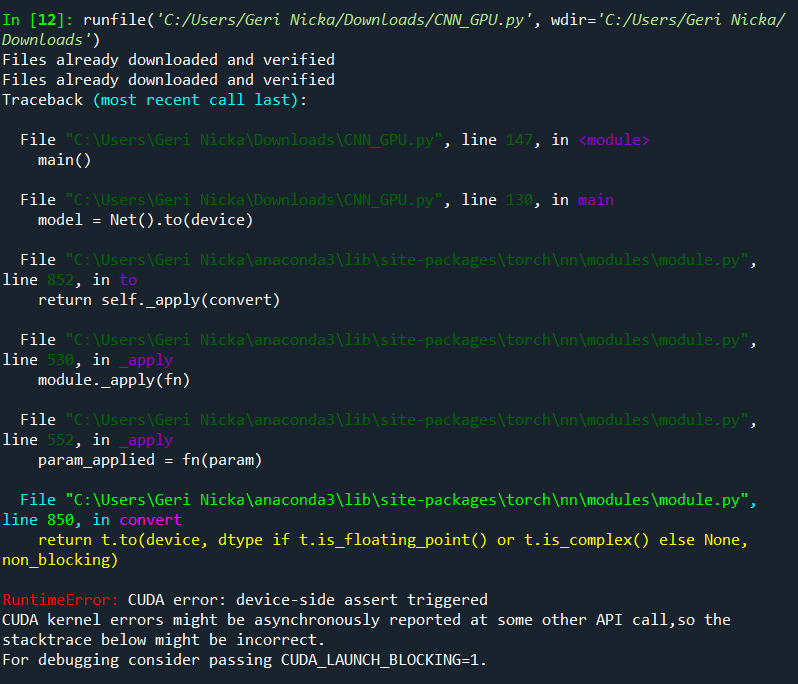
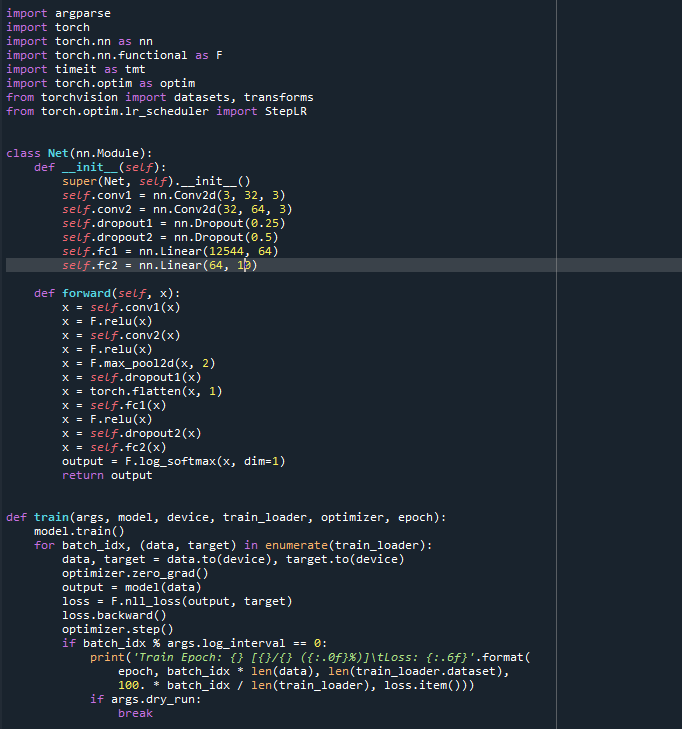
I have used this network architecture for MNIST and CIFAR10 and runs successfully but when I try to train the CIFAR100 data i get the following error. Of course I changed various settings in the network class for MNIST and CIFAR10 but cannot understand what is wrong with CIFAR100.
You can debug these CUDA Runtime Errors best if you run your code on CPU. This will give you a more useful traceback error.
But Most of the time CUDA Runtime Errors can be the cause of some index mismatching so like you tried to train a network with 10 output nodes on a dataset with 100 labels.
Which is exactly what your screenshot is showing.
Keep in mind that CIFAR-10 and MNIST have 10 classes but CIFAR-100 has 100 classes.
Did you maybe forget to change the
Yes agreed with @RaLo4
you have forgotten to change the size at the last layer from 10 to 100, that’s why it’s giving an error during loss computation.