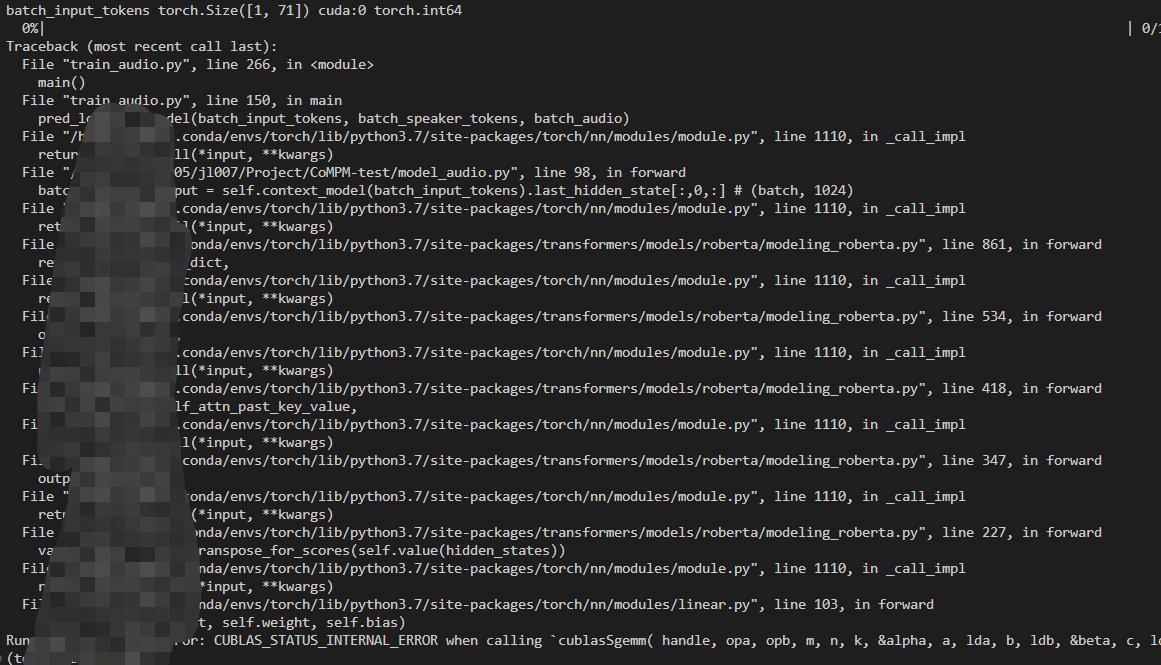
I don’t know i miss the problem “CUDA error: CUBLAS_STATUS_INTERNAL_ERROR when calling `cublasSgemm( handle, opa, opb, m, n, k, &alpha, a, lda, b, ldb, &beta, c, ldc)”. could you please give me some advice to solve it ? many thanks
hers is my code as follows, I add " self.linear_in_pro = torch.nn.Linear(feature_dim_audio, feature_dim_input_tokens)
device = torch.device(“cuda:0”)
linear_in_pro = self.linear_in_pro.to(device)
print(‘linear_in_pro’, self.linear_in_pro)" in my model. I train on “import os
os.environ[“CUDA_VISIBLE_DEVICES”]= ‘0’”:
“
-- coding: utf-8 --
import os
os.environ[“CUDA_VISIBLE_DEVICES”]= ‘0’
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
import os, sys
import math
import pandas as pd
import pdb
from transformers import RobertaTokenizer, RobertaModel
from transformers import BertTokenizer, BertModel
from transformers import GPT2Tokenizer, GPT2Model
from transformers import RobertaConfig, BertConfig
class ERC_model(nn.Module):
def init(self, model_type, clsNum, last, freeze, initial):
super(ERC_model, self).init()
self.gpu = True
self.last = last
"""Model Setting"""
# model_path = '/data/project/rw/rung/model/'+model_type
model_path = model_type
if 'roberta' in model_type:
self.context_model = RobertaModel.from_pretrained(model_path)
if initial == 'scratch':
config = RobertaConfig.from_pretrained(model_path)
self.speaker_model = RobertaModel(config)
else:
self.speaker_model = RobertaModel.from_pretrained(model_path)
elif model_type == 'bert-large-uncased':
self.context_model = BertModel.from_pretrained(model_path)
if initial == 'scratch':
config = BertConfig.from_pretrained(model_path)
self.speaker_model = BertModel(config)
else:
self.speaker_model = BertModel.from_pretrained(model_path)
else:
self.context_model = GPT2Model.from_pretrained(model_path)
tokenizer = GPT2Tokenizer.from_pretrained(model_path)
tokenizer.add_special_tokens({'cls_token': '[CLS]', 'pad_token': '[PAD]'})
self.context_model.resize_token_embeddings(len(tokenizer))
self.speaker_model = GPT2Model.from_pretrained(model_path)
self.speaker_model.resize_token_embeddings(len(tokenizer))
self.hiddenDim = self.context_model.config.hidden_size
zero = torch.empty(2, 1, self.hiddenDim).cuda()
self.h0 = torch.zeros_like(zero) # (num_layers * num_directions, batch, hidden_size)
self.speakerGRU = nn.GRU(self.hiddenDim, self.hiddenDim, 2, dropout=0.3) # (input, hidden, num_layer) (BERT_emb, BERT_emb, num_layer)
#audio projection
"""score"""
# self.SC = nn.Linear(self.hiddenDim, self.hiddenDim)
self.W = nn.Linear(self.hiddenDim, clsNum)
"""parameters"""
self.train_params = list(self.context_model.parameters())+list(self.speakerGRU.parameters())+list(self.W.parameters()) # +list(self.SC.parameters())
if not freeze:
self.train_params += list(self.speaker_model.parameters())
def forward(self, batch_input_tokens, batch_speaker_tokens, batch_audio):
"""
batch_input_tokens: (batch, len)
batch_speaker_tokens: [(speaker_utt_num, len), ..., ]
"""
# print('batch_input_tokens', batch_input_tokens.shape, batch_input_tokens.device, batch_input_tokens.dtype)
batch_audio = torch.tensor(batch_audio, dtype=torch.int64)
# print('batch_audio', batch_audio.shape)
batch_size_input, feature_dim_input_tokens = batch_input_tokens.size()
batch_size_input, feature_dim_audio = batch_audio.size()
self.linear_in_pro = torch.nn.Linear(feature_dim_audio, feature_dim_input_tokens)
device = torch.device("cuda:0")
linear_in_pro = self.linear_in_pro.to(device)
print('linear_in_pro', self.linear_in_pro)
batch_input_tokens = self.linear_in_pro(batch_audio.float())
# batch_input_tokens = batch_input_tokens.clone().detach()
batch_input_tokens = torch.tensor(batch_input_tokens, dtype=torch.int64)
print('batch_input_tokens', batch_input_tokens.shape, batch_input_tokens.device, batch_input_tokens.dtype)
if self.last:
batch_context_output = self.context_model(batch_input_tokens).last_hidden_state[:,-1,:] # (batch, 1024)
else:
# self.context_model = self.context_model.cuda()
batch_context_output = self.context_model(batch_input_tokens).last_hidden_state[:,0,:] # (batch, 1024)
#audio
# batch_context_output = batch_audio
batch_speaker_output = []
for speaker_tokens in batch_speaker_tokens:
if speaker_tokens.shape[0] == 0:
speaker_track_vector = torch.zeros(1, self.hiddenDim).cuda()
else:
if self.last:
speaker_output = self.speaker_model(speaker_tokens.cuda()).last_hidden_state[:,-1,:] # (speaker_utt_num, 1024)
else:
speaker_output = self.speaker_model(speaker_tokens.cuda()).last_hidden_state[:,0,:] # (speaker_utt_num, 1024)
speaker_output = speaker_output.unsqueeze(1) # (speaker_utt_num, 1, 1024)
speaker_GRU_output, _ = self.speakerGRU(speaker_output, self.h0) # (speaker_utt_num, 1, 1024) <- (seq_len, batch, output_size)
speaker_track_vector = speaker_GRU_output[-1,:,:] # (1, 1024)
batch_speaker_output.append(speaker_track_vector)
batch_speaker_output = torch.cat(batch_speaker_output, 0) # (batch, 1024)
final_output = batch_context_output + batch_speaker_output
# print('findal_output', final_output.shape)
# final_output = batch_context_output + self.SC(batch_speaker_output)
context_logit = self.W(final_output) # (batch, clsNum)
return context_logit
”