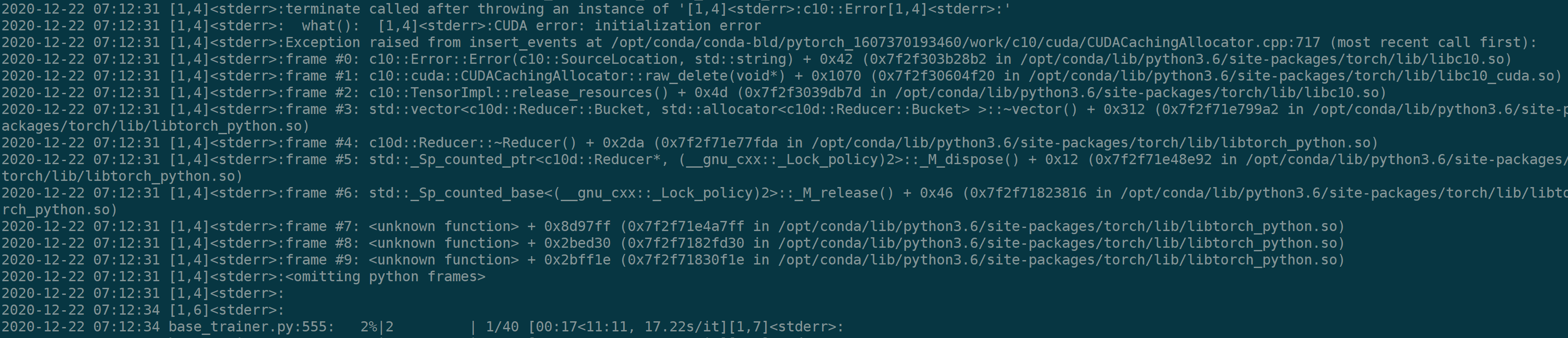
The problem crashed with the initialization error. From the call stack, it seems like it crashed when it tries to release some resource. The whole program is kinds of large. The basic logic is that, it first calls train() which creates the model, and run the training. Then, it calls the predict(), which also creates the model and run the prediction. The program is running distributed in 8 GPUs. Each GPU only predicts part of the test files and then rank=0 will concatenate those files.
The crash is at the prediction phase. Only one GPU crashes with this error and all other GPUs can finish the predictions well.
yes. no issue at training. it crashes only on inference. The code is kind of large and it is hard to extract. One strange thing is that if i skip the training and run the inference only, it runs well with loading previously trained model.
Thanks. Problem solved, but the root cause is unknown. Here is the story for reference. The program first calls train() to do model training, where the model will be built, optimizer will be constructed, and learning rate scheduler will also be initialized. The learning rate scheduler is based on a lambda expression. After train(), supposedly, the learning rate scheduler/model/optimizer should be collected by teh garbage collector, but not. The reason seems to be the lambda expression-based learning rate scheduler. In this case, the model/optimizer also are in the GPU memory without releasing resources. Then, in test(), the model will be re-built, which might have some issues, although the crash should be on data loader (if #workers is 0, also no issues). After refactoring the learning rate scheduler by removing the lambda expression, everything works fine.