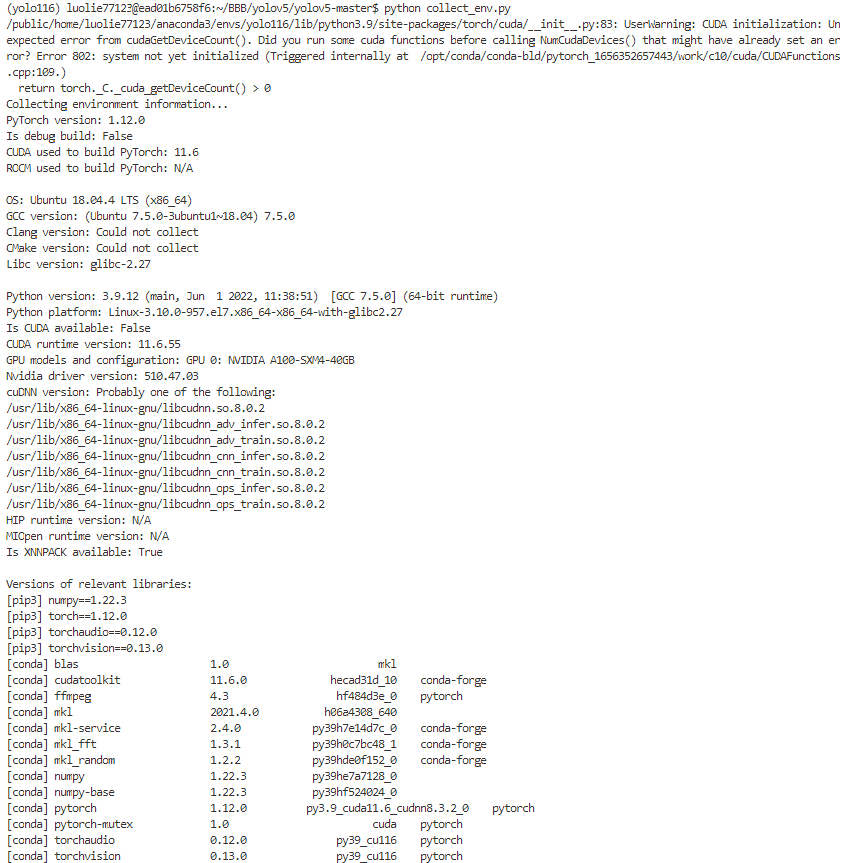
I created multiple environments based on Cuda10.2 and Cuda11.6 and reported the same error on the A100 card。 CUDA initialization: Unexpected error from cudaGetDeviceCount(),How do I solve it?
nvidia-smi =11.6, A100
1.export Cuda10.2->nvcc -V=10.2
conda create -n XXX python=3.9
conda activate XXX
conda install pytorch==1.10.1 torchvision==0.11.2 torchaudio==0.10.1 cudatoolkit=10.2 -c pytorch
python
import torch
torch.cuda.is_available()
return False
2.export Cuda11.6->nvcc -V=11.6
conda create -n XXX python=3.9
conda activate XXX
conda install pytorch torchvision torchaudio cudatoolkit=11.6 -c pytorch -c conda-forge (or) pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu116
python
import torch
torch.cuda.is_available()
return False
Such errors are reported(UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 802: system not yet initialized (Triggered internally at /opt/conda/conda-bld/pytorch_1639180549130/work/c10/cuda/CUDAFunctions.cpp:112.))
It seems your driver has trouble to initialize the device:
UserWarning: CUDA initialization: Unexpected error from cudaGetDeviceCount(). Did you run some cuda functions before calling NumCudaDevices() that might have already set an error? Error 802: system not yet initialized
Was this setup working before at all? If so, what changed which might cause the issue (e.g. did you update the drivers etc.)?
OK, I see. In this case you could check if any other CUDA sample would run (I would expect to see the same or similar errors) and might need to reinstall the drivers in this case.
Any news here? We are having exactly the same problem, A40s work well but not A100s. The configuration of A40 and A100 nodes are identical. I tested with different PyTorch versions (1.12, 1.11, 1.10).
No updates, as @LUO77123 didn’t follow up and the error is usually raised by a config error.
Check if any CUDA applications can run and make sure the right PyTorch binary with the desired CUDA runtime is installed.
I had a problem with a 4xA100 box where both host CUDA samples and docker PyTorch self-contained binaries returned cudaGetDeviceCount errors. I just figured out the root cause: A100 has MIG mode enabled by default, thus making getDeviceCount() error out.
I solved it by using sudo nvidia-smi -mig 0 to disable MIG mode, reboot since it was pending (perhaps due to loginctl linger settings), and the do sudo nvidia-smi -mig 0 again.
I recently ran into this issue again and managed to solve it with the help of a friend. The problem was caused by the Fabric Manager service not being started, which left the NVLink topology in an abnormal state.
You can check it by running systemctl status nvidia-fabricmanager. If it shows as “failed,” that’s likely the culprit.
To fix it, simply restart the service with: sudo systemctl start nvidia-fabricmanager