I am training my models in a local machine with a GPU available. My particular application is in RL, where I have multiple workers working in parallel (implemented with python3 multiprocessing) collecting experience using my torch models on the cpu since only forward passes are needed. Periodically I also have a main process, that trains an instance of the model on the GPU and then updates the weights of the worker models.
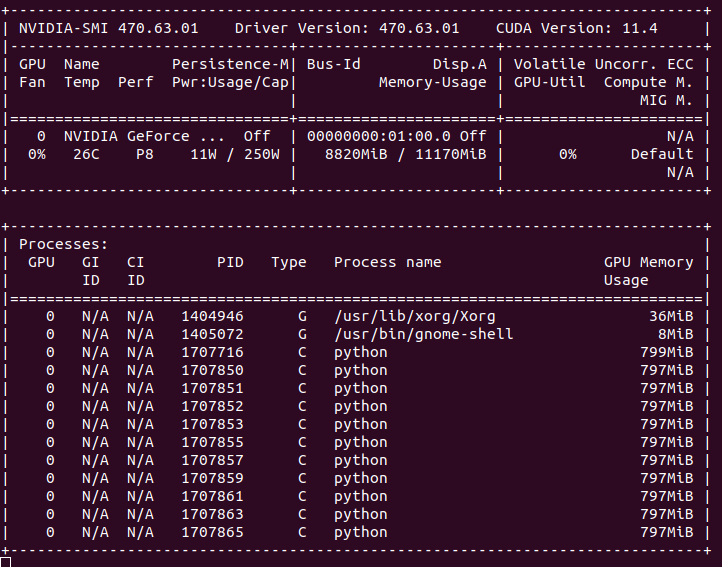
The problem that I face is that, also the worker processes take around 800 MBs of memory on the GPU (I assume for the CUDA kernels) even though they never access the GPU.
The screenshot shown, presents an exemple view of nvidia-smi. In this example I am using a simple MLP model (2MB of memory needed), and I am using 10 worker processes, which can be seen to take 797 MBs of memory each, and the master process (id 1707716) that takes 799 ( 2 MB more because of the model memory).
I am not adding portions of the code, as It is pretty complex and spread around multiple files but I wanted to ask if there is a way to avoid loading the kernel in the GPU memory for every process using torch or if there is a way to free it.
Based on the output of nvidia-smi you are initializing a CUDA context in each worker. I don’t know how you are spawning them but you might want to check if you are (accidentally) initializing it or could also try to mask the device in the workers.
Thank you for your reply and sorry for the delayed response!
I have tried to mask the device in the worker processes, in their init method of the worker processes, by setting “CUDA_VISIBLE_DEVICES”="" in the environment, but this has also not worked. I have also checked for accidental references to cuda without a finding any.
I produced a minimum working example of the problem in this repo: GitHub - amarildolikmeta/torch_workers_gpu
It requires open ai gym (it includes a simple test environment).
The main script initializes the worker processes then runs a loop alternating between the main process running some episodes in the gpu, followed by 2 workers processes running some episodes with the models in the CPU.
This minimum example reproduces this behaviour in my ubuntu 18.04, with python 3.6 and torch 1.10
I found the problem, and as you sad it was an “accidental” access to the cuda context, done when I copied the parameters between the model of the main process (in gpu) to the models of the workers processes (in cpu). This was done through the state_dict method, without mapping the tensors in the state_dict to the CPU before calling load_state_dict in the worker models.
Thanks again for the help!