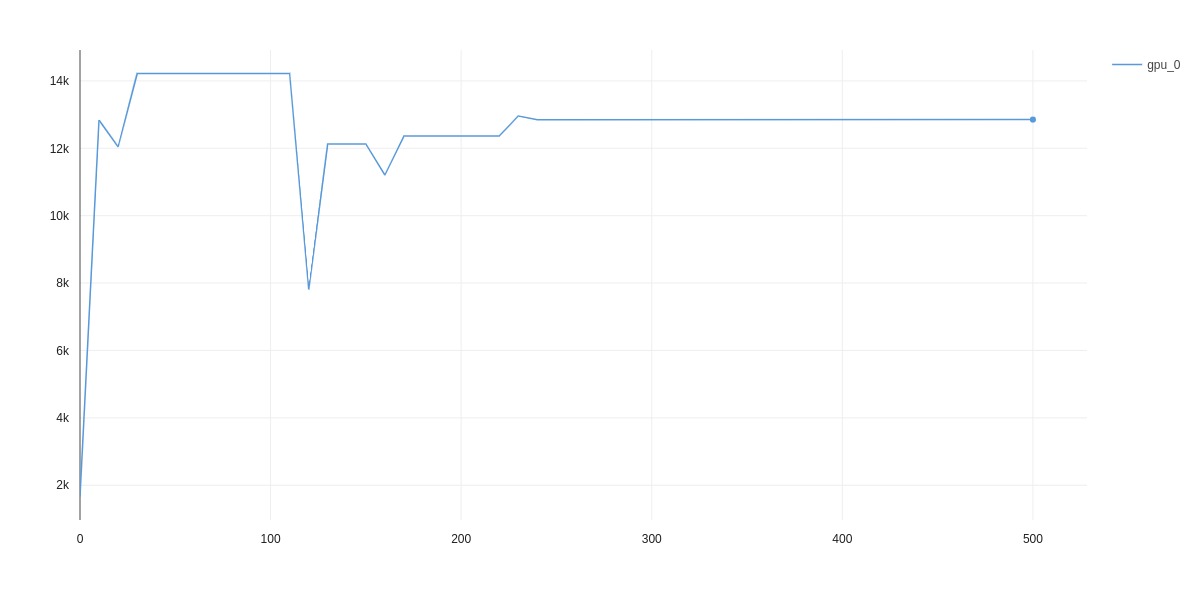
Hi,
I ran into a problem with CUDA memory leak. I’m training on a single GPU with 16GB of RAM and I keep running out of memory after some number of steps. Around 500 out of 4000.
My dataset is quite big, and it crashes during the first epoch.
I noticed that memory usage is growing steadily, but I can’t figure out why.
At first, I wasn’t forcing CUDA cache clear and thought that this might do the trick, but even after torch.cuda.empty_cache() I keep seeing the same issue:
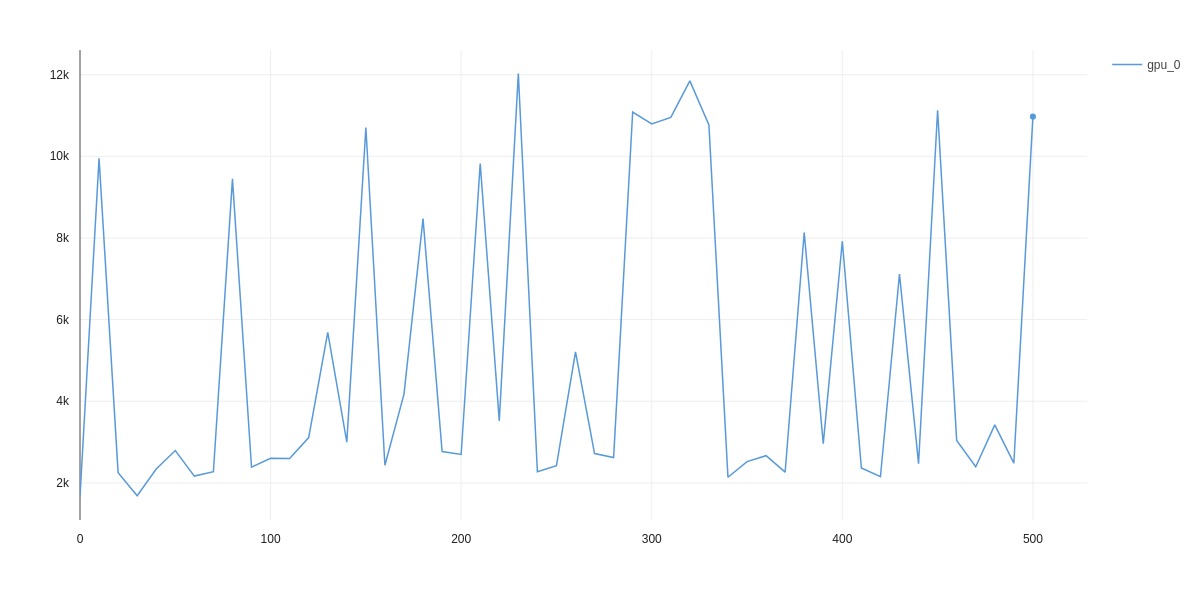
I’m using Pytorch Lightning, but I don’t think that it’s because of it, but rather because of my model.
Can anyone see the issue or point me in the right direction - how to find a memory leak?
Below is my full model:
from collections import OrderedDict
import pytorch_lightning as pl
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from preprocessing import GreedyDecoder, cer, wer
class SpeechRecognitionModel(pl.LightningModule):
def __init__(self, hparams: dict):
super(SpeechRecognitionModel, self).__init__()
self.hparams = hparams
self.criterion = nn.CTCLoss(blank=37)
n_cnn_layers = hparams['n_cnn_layers']
n_rnn_layers = hparams['n_rnn_layers']
rnn_dim = hparams['rnn_dim']
n_class = hparams['n_class']
n_feats = hparams['n_feats']
stride = hparams['stride']
dropout = hparams['dropout']
n_feats = n_feats // 2
self.cnn = nn.Conv2d(1, 32, 3, stride=stride, padding=3 // 2) # cnn for extracting heirachal features
# n residual cnn layers with filter size of 32
self.rescnn_layers = nn.Sequential(*[
ResidualCNN(32, 32, kernel=3, stride=1, dropout=dropout, n_feats=n_feats)
for _ in range(n_cnn_layers)
])
self.fully_connected = nn.Linear(n_feats * 32, rnn_dim)
self.birnn_layers = nn.Sequential(*[
BidirectionalGRU(rnn_dim=rnn_dim if i == 0 else rnn_dim * 2,
hidden_size=rnn_dim, dropout=dropout, batch_first=i == 0)
for i in range(n_rnn_layers)
])
self.classifier = nn.Sequential(
nn.Linear(rnn_dim * 2, rnn_dim), # birnn returns rnn_dim*2
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(rnn_dim, n_class)
)
def forward(self, x):
x = self.cnn(x)
x = self.rescnn_layers(x)
sizes = x.size()
x = x.view(sizes[0], sizes[1] * sizes[2], sizes[3]) # (batch, feature, time)
x = x.transpose(1, 2) # (batch, time, feature)
x = self.fully_connected(x)
x = self.birnn_layers(x)
x = self.classifier(x)
return x
def configure_optimizers(self):
optimizer = optim.AdamW(self.parameters(), self.hparams['learning_rate'])
scheduler = torch.optim.lr_scheduler.OneCycleLR(
optimizer,
max_lr=self.hparams['learning_rate'],
steps_per_epoch=int(len(self.train_dataloader()) // self.hparams['batch_size']),
epochs=self.hparams['epochs'],
anneal_strategy='linear'
)
return [optimizer], [scheduler]
def training_step(self, batch, batch_nb):
spectrograms, labels, input_lengths, label_lengths = batch
output = self.forward(spectrograms) # (batch, time, n_class)
output = F.log_softmax(output, dim=2)
output = output.transpose(0, 1) # (time, batch, n_class)
loss = self.criterion(output, labels, input_lengths, label_lengths)
torch.cuda.empty_cache()
comet_logs = {'training_loss': loss}
return {'loss': loss, 'log': comet_logs}
def validation_step(self, batch, batch_nb):
spectrograms, labels, input_lengths, label_lengths = batch
output = self(spectrograms) # (batch, time, n_class)
output = F.log_softmax(output, dim=2)
output = output.transpose(0, 1) # (time, batch, n_class)
loss_val = self.criterion(output, labels, input_lengths, label_lengths)
val_cer, val_wer = [], []
decoded_preds, decoded_targets = GreedyDecoder(output.transpose(0, 1), labels, label_lengths)
for j in range(len(decoded_preds)):
val_cer.append(cer(decoded_targets[j], decoded_preds[j]))
val_wer.append(wer(decoded_targets[j], decoded_preds[j]))
avg_cer = sum(val_cer) / len(val_cer)
avg_wer = sum(val_wer) / len(val_wer)
output = OrderedDict({
'val_loss': loss_val,
"avg_cer": torch.tensor(avg_cer),
"avg_wer": torch.tensor(avg_wer),
})
return output
def validation_epoch_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
val_cer = [x['avg_cer'] for x in outputs]
val_wer = [x['avg_wer'] for x in outputs]
avg_cer = sum(val_cer) / len(val_cer)
avg_wer = sum(val_wer) / len(val_wer)
comet_logs = OrderedDict({
'val_loss': avg_loss,
"avg_cer": avg_cer,
"avg_wer": avg_wer}
)
return {'val_loss': avg_loss, 'log': comet_logs}
class CNNLayerNorm(nn.Module):
"""Layer normalization built for cnns input"""
def __init__(self, n_feats):
super(CNNLayerNorm, self).__init__()
self.layer_norm = nn.LayerNorm(n_feats)
def forward(self, x):
# x (batch, channel, feature, time)
x = x.transpose(2, 3).contiguous() # (batch, channel, time, feature)
x = self.layer_norm(x)
return x.transpose(2, 3).contiguous() # (batch, channel, feature, time)
class ResidualCNN(nn.Module):
"""Residual CNN inspired by https://arxiv.org/pdf/1603.05027.pdf
except with layer norm instead of batch norm
"""
def __init__(self, in_channels, out_channels, kernel, stride, dropout, n_feats):
super(ResidualCNN, self).__init__()
self.cnn1 = nn.Conv2d(in_channels, out_channels, kernel, stride, padding=kernel // 2)
self.cnn2 = nn.Conv2d(out_channels, out_channels, kernel, stride, padding=kernel // 2)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.layer_norm1 = CNNLayerNorm(n_feats)
self.layer_norm2 = CNNLayerNorm(n_feats)
def forward(self, x):
residual = x # (batch, channel, feature, time)
x = self.layer_norm1(x)
x = F.gelu(x)
x = self.dropout1(x)
x = self.cnn1(x)
x = self.layer_norm2(x)
x = F.gelu(x)
x = self.dropout2(x)
x = self.cnn2(x)
x += residual
return x # (batch, channel, feature, time)
class BidirectionalGRU(nn.Module):
def __init__(self, rnn_dim, hidden_size, dropout, batch_first):
super(BidirectionalGRU, self).__init__()
self.BiGRU = nn.GRU(
input_size=rnn_dim, hidden_size=hidden_size,
num_layers=1, batch_first=batch_first, bidirectional=True)
self.layer_norm = nn.LayerNorm(rnn_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
x = self.layer_norm(x)
x = F.gelu(x)
x, _ = self.BiGRU(x)
x = self.dropout(x)
return x