Here’s the memory usage without torch.cuda.empty_cache()
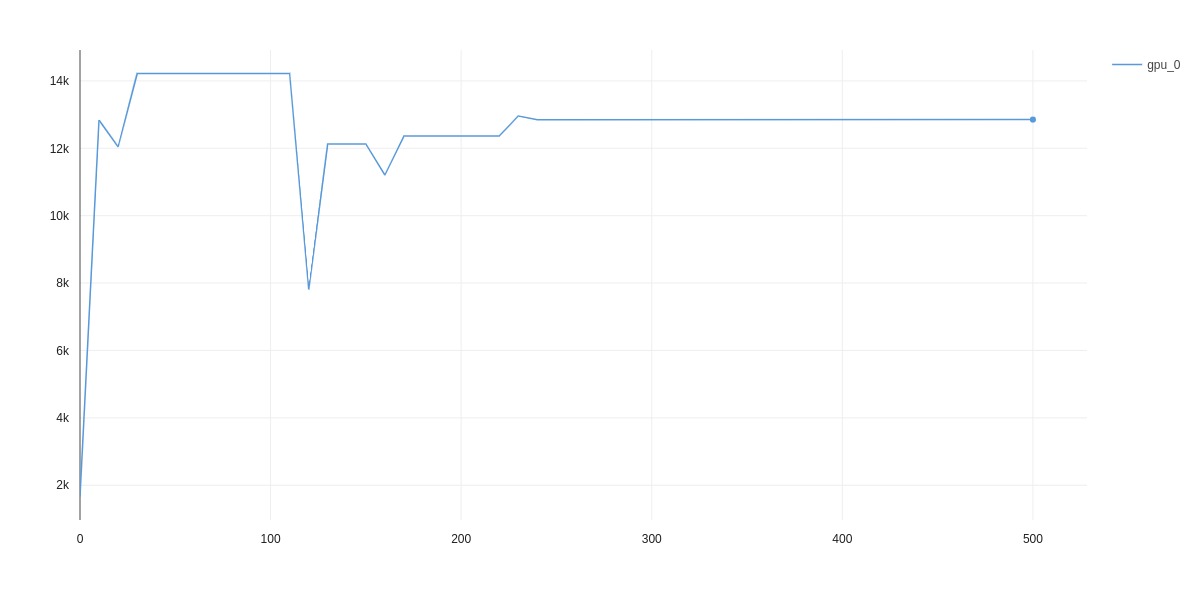
It doesn’t say much.
I also set up memory profiling found in this topic How to debug causes of GPU memory leaks? - #18 by Jean_Da_Rolt
Memory usage fluctuates a bit but stays around 12800Mb after step ~220
What I noticed is that it ALWAYS crashes on step 507/3957. Not sure if that indicates anything at all.
RuntimeError: CUDA out of memory. Tried to allocate 1.14 GiB (GPU 0; 14.76 GiB total capacity; 12.09 GiB already allocated; 483.44 MiB free; 13.48 GiB reserved in total by PyTorch)
I also tried to remove comet logger and all logging, but result was the same.
I could try to remove PyTorch Lightning and do training manually, I don’t think that it would help.