I am training my models(pretrained resnet and densenet) in rtx 2080ti, it works well. When I move the models to rtx a6000(i need lager batch size)the bug occurs, about 4.5GB is allocated and nearly 40GB is free! I have no idea about this bug, anything could help thank you very much.
Could you post an executable code snippet to reproduce this issue as well as the output of python -m torch.utils.collect_env, please?
I am sorry to answer you so late, I wasbusy with the project of my tutor recent days.
Here is the output of python -m torch.utils.collect_env
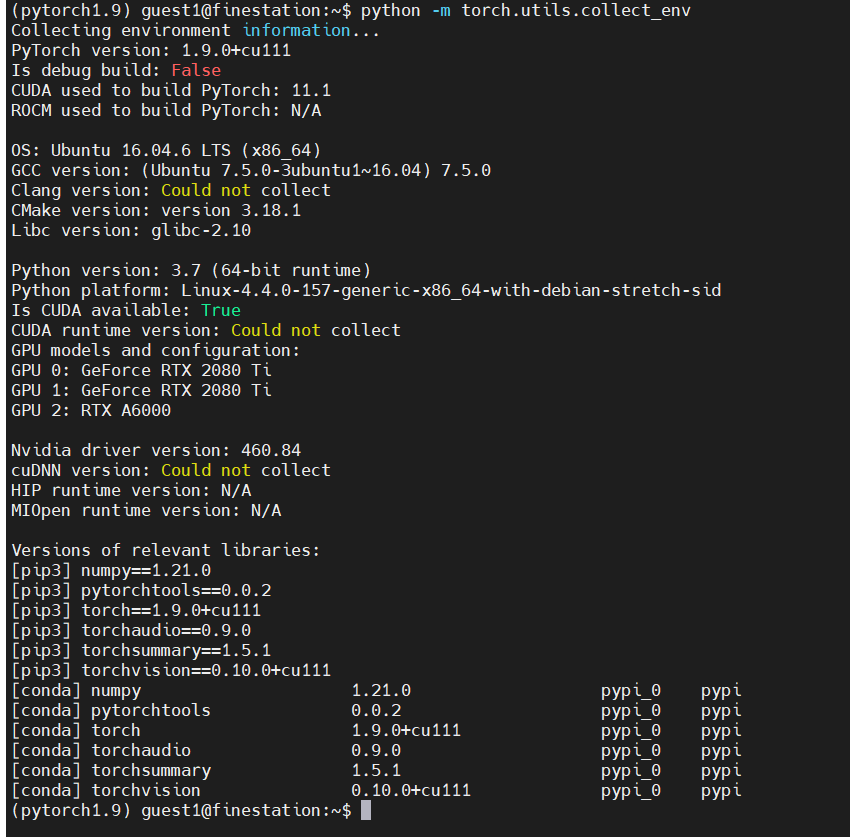
here is the output when the bug occurs
here is the training part of my code and the criterion_T is a self-defined loss function in this paper Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels
and here is the code of the paper code, my criterion_T’s loss is the ‘Truncated-Loss.py’ in that code
the bug occur in the line ![]()
for image, target, index in tqdm(loader_train, total=int(data_train.__len__()/opt.batch_size)):
#for image, target, index in loader_train:
target = target.cuda(opt.cuda_device)
# Target = F.one_hot(target[2].cuda(opt.cuda_device), opt.n_classes)
image = image.cuda(opt.cuda_device)
########## train resnet1
resnet.net.zero_grad()
out1 = resnet.net.forward(image)
with torch.no_grad():
cee1 = F.cross_entropy(out1, target, reduce=False, reduction='none')
L1 = cee1.cpu().numpy()
ind1 = np.argsort(L1)
update_num1 = get_update_num(L1[ind1])
# dataset_all.static_right_label(index[ind[:clean_num]].tolist())
update_all_num1 += update_num1
########## train resnet1
densenet.net.zero_grad()
out2 = densenet.net.forward(image)
with torch.no_grad():
cee2 = F.cross_entropy(out2, target, reduce=False, reduction='none')
L2 = cee2.cpu().numpy()
ind2 = np.argsort(L2)
update_num2 = get_update_num(L2[ind2])
# dataset_all.static_right_label(index[ind[:clean_num]].tolist())
update_all_num2 += update_num2
loss1 = criterion_T(out1, Target, index)
loss2 = criterion_T(out2, Target, index)
resnet.optimizer.step()
loss2.backward()
densenet.optimizer.step()```
Finally thank you very much for answer my question, good luck to you.Thanks for the update.
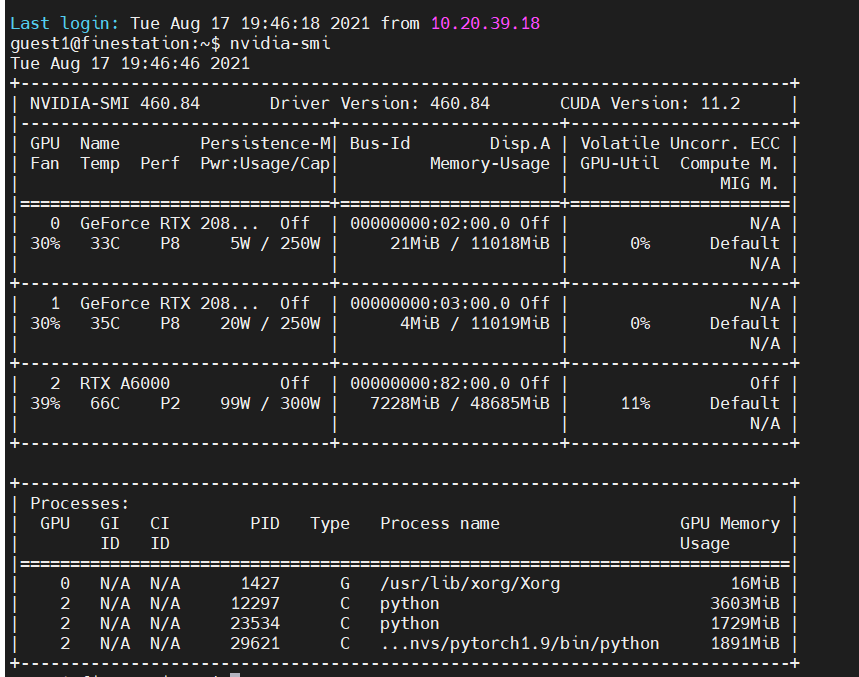
The screenshot shows that your GPU has a total capacity of 10.76GiB and cannot allocate the needed 98MiB anymore, so you are not using the A6000 as described in the previous post.
I guess you might have specified the wrong device while executing your script (either inside the script via to('cuda:wriong_id') or via CUDA_VISIBLE_DEVICES=wrong_id).
Could you check via nvidia-smi how much memory is reported to be free there when the script runs OOM?
Also, could you update the code snippet to be executable so that we could try to reproduce it on an A6000?
Try to reduce the code as much as possible by removing unnecessary code parts and please post it here or create e.g. a gist on GitHub.
Thank you for answer my question so patient, here is link to my code
Thanks for the code. It seems the data might not have been created as I’m running into:
FileNotFoundError: [Errno 2] No such file or directory: '/data/guest1/clothing1m/noised_label.txt'
while executing run.py.
I am sorry for that, it is so busy recent days, I have already up load the txt files to the code link, please unzip noised_label.zip before using. and you can get the data through clothing-1m data set.
and here is the location in my computer
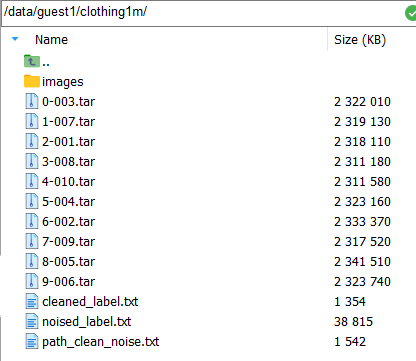
After downloading, please unzip all the tar files into ‘images’ folder directly. Thank you very much.
Could you update the code to work with random input tensors in the needed shape, please?
I assume the error would also show without downloading the real dataset (where each .tar file seems to be ~2.3GB large?).
Thanks for the update to the code.
I cannot reproduce the issue on an A6000 and the script runs fine for a few epochs:
root@dc9def623dde:/workspace/src/OOM-occurs-while-I-have-enough-cuda-memory# python run2.py
Namespace(base_path='/data/guest1/clothing1m/', batch_size=64, cuda_device=0, img_size=224, lr=0.01, n_classes=14, n_epochs=500)
Downloading: "https://download.pytorch.org/models/resnet101-63fe2227.pth" to /root/.cache/torch/hub/checkpoints/resnet101-63fe2227.pth
100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 171M/171M [00:04<00:00, 38.8MB/s]
Downloading: "https://download.pytorch.org/models/densenet121-a639ec97.pth" to /root/.cache/torch/hub/checkpoints/densenet121-a639ec97.pth
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 30.8M/30.8M [00:00<00:00, 109MB/s]
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 156/156 [01:25<00:00, 1.82it/s]
the 1 epoch right ratio: 0.0 0.0 ---accuracy1: 0.096154 accuracy2: 0.096154 learning rate: 0.01 0.01
100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 156/156 [01:20<00:00, 1.94it/s]
the 2 epoch right ratio: 0.0 0.0 ---accuracy1: 0.057692 accuracy2: 0.057692 learning rate: 0.01 0.01
nvidia-smi also reports a max. memory usage of ~20GB:
|===============================+======================+======================|
| 0 NVIDIA RTX A6000 On | 00000000:01:00.0 Off | Off |
| 56% 83C P2 247W / 300W | 19589MiB / 48684MiB | 99% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
Did you enable MIG on this device or limit the max. memory usage via e.g. PyTorch?
Thanks a lot, there is a limitation for my account, my team mate did that a few days ago without telling me. good luck to you!