Hello guys. I hope you can help me with this
I have been training my CNN model with input of size (32, 4, 9, 3, 224, 224 batch, (4,9,3 mn3 matrix) Height, weight).
First I have changed the size of the batch from 64 to 32 and then to 16 but the error remains. Then i have decided to use Dataparallale and model paralle but same.
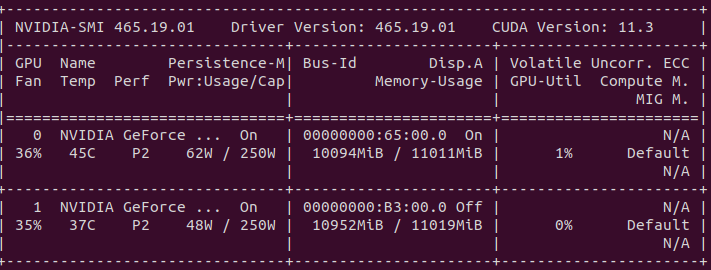
I have to GPU with the following characteristics:
the model:
import torch
import torchvision # torch package for vision related things
import torch.nn.functional as F # Parameterless functions, like (some) activation functions
import torchvision.datasets as datasets # Standard datasets
import torchvision.transforms as transforms # Transformations we can perform on our dataset for augmentation
from torch import optim # For optimizers like SGD, Adam, etc.
from torch import nn # All neural network modules
from torch.utils.data import DataLoader # Gives easier dataset managment by creating mini batches etc.
from tqdm import tqdm # For nice progress bar!
class CNNskl(nn.Module):
def __init__(self, in_channels=3, num_classes=120):
super(CNNskl, self).__init__()
self.conv1 = nn.Conv2d(
in_channels=in_channels,
out_channels=128,
kernel_size=3,
stride=1,
padding=2,
).to('cuda:0')
self.maxpool1 = nn.MaxPool2d(kernel_size=2)
self.conv2 = nn.Conv2d(
in_channels=128,
out_channels=64,
kernel_size=(3, 3),
stride=1,
padding=2,
).to('cuda:1')
self.maxpool2 = nn.MaxPool2d(kernel_size=2)
self.conv3 = nn.Conv2d(
in_channels=64,
out_channels=32,
kernel_size=3,
stride=2,
padding=2,
).to('cuda:0')
self.maxpool3 = nn.MaxPool2d(kernel_size=2)
self.fc1 = nn.Linear(32, 200).to('cuda:1')
self.fc2 = nn.Linear(200, num_classes).to('cuda:0')
self.dropout = nn.Dropout(0.5)
def forward(self, x):
# 64, 49, 100, 3
# 64, 1200, 4, 9, 3
#b1, d1, h1, w1, c1 = x.shape
#x = x.reshape(b1 * d1, c1, h1, w1)
# premier input
b, n, m, z, H, W = x.shape
x = x.reshape(b*n*m, z, H, W)
x = F.relu(self.conv1(x.to("cuda:0")))
x = self.maxpool1(x)
x = F.relu(self.conv2(x.to('cuda:1')))
x = self.maxpool2(x)
x = F.relu(self.conv3(x.to('cuda:0')))
x = self.maxpool3(x)
x = x.reshape(b, n*m, -1)
x = x.mean(dim=1)
x = self.fc1(x.to('cuda:1'))
x = self.dropout(self.fc2(x.to('cuda:0')))
return x
training script:
import os
import argparse
import torch
import torch.nn as nn
from torch.backends import cudnn
from torch.utils import data
from torch.utils.data import DataLoader
from torch.optim.lr_scheduler import ReduceLROnPlateau
from Models.PretrainedModel import Model3DResnet
from Models.ModelCnn import CNNskl
from NTU_RGBD_120_SkeletonDataset import SkeletonDataset as SkeletonDataset
import matplotlib.pyplot as plt
import pandas as pd
import time
import copy
class AverageMeter(object):
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].reshape(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res
# Plotting the accuracy and the validation accurary and loss
def plot_loss(v_train_loss, v_val_loss, namefile: str):
epochs = []
for i in range(1, 201):
epochs.append(i)
v_train_loss_rounded = [round(element, 0) for element in v_train_loss]
v_val_loss_rounded = [round(element, 0) for element in v_val_loss]
plt.plot(epochs, v_train_loss_rounded)
plt.plot(epochs, v_val_loss_rounded)
plt.xlabel("Epochs")
plt.ylabel("Loss")
plt.title("Loss")
plt.legend(["Training Loss", "Validation Loss"], loc = 1)
plt.savefig(namefile +'.png')
plt.show()
# def save_loss_accuracy(dic_value, path_file):
# dataframe = pd.DataFrame(dic_value.items(), columns=['epochs', 'values'])
# dataframe.to_csv(path_file, sep=',', index=True)
def plot_accurracy(v_train_accuracy, v_val_accuracy, namefile: str):
epochs = []
for i in range(1, 201):
epochs.append(i)
v_train_accuracy_rounded = [round(element, 0) for element in v_train_accuracy]
v_val_accuracy_rounded = [round(element, 0) for element in v_val_accuracy]
plt.plot(epochs, v_train_accuracy_rounded)
plt.plot(epochs, v_val_accuracy_rounded)
plt.xlabel("Epochs")
plt.ylabel("Accuracy")
plt.title("Accuracy")
plt.legend(["Training Accuracy", "Validation Accuracy"], loc = 1)
plt.savefig(namefile +'.png')
plt.show()
def save_loss_accuracy(dic_value, path_file):
dataframe = pd.DataFrame(dic_value.items(), columns=['epochs', 'values'])
dataframe.to_csv(path_file, sep=',', index=True)
# cette function permet de faire le training. Le pourquoi jai voulu l'utiliser est que lie au probleme de
# memory du GPU
def train_model(model, criterion, optimizer, num_epochs, train_loader, val_loader, device):
since = time.time
best_model_wts = copy.deepcopy(model.state_dict())
best_acc = 0.0
for epoch in range(num_epochs):
v_top1 = AverageMeter()
v_top3 = AverageMeter()
v_loss = AverageMeter()
# le paramettre unique doit etre le loader. il prendra la valeur de traininig ou de validation lorsque le
#
for phase in ["train", "val"]:
if phase == "train":
v_loader = train_loader
model.train()
if phase == "val":
v_loader = val_loader
model.eval()
for i, (datas, labels) in enumerate(v_loader):
datas = datas.to(device)
labels = labels.to('cuda:0')
labels = labels - 1
# get a prediction scores and clculate loss
# the model can receive bot data
pred = model(datas)
loss = criterion(pred, labels)
if phase == "train":
optimizer.zero_grad()
loss.backward()
optimizer.step()
# calculate loss and acc
prec1, prec3 = accuracy(pred.data, labels, topk=(1, 3))
v_loss.update(loss.item(), datas.size(0))
v_top1.update(prec1.item(), datas.size(0))
v_top3.update(prec3.item(), datas.size(0))
# print a message
print("[train] epochs: {}/{} batch: {}/{} loss: {:.4f}({:.4f}) proc@1: {:.4f}({:.4f}) proc@3: {:.4f}({:.4f})".format(
epoch, num_epochs, i, len(v_loader), v_loss.val, v_loss.avg,
v_top1.val, v_top1.avg, v_top3.val, v_top3.avg,
))
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="action based skeleton args")
parser.add_argument("--arraypath", default="Datasets/NTU/Skeleton/imagerepresentation/spatioVelo/", type=str)
parser.add_argument("--crossactioncsvpath", default="dataloaders/Labels/cross_action/", type=str)
parser.add_argument("--crossviewcsvpath", default="dataloaders/Labels/cross_view/", type=str)
parser.add_argument("--sequencelength", default=4, type=int)
parser.add_argument("--epochs", default=200, type=int)
parser.add_argument("--batchsize", default=8, type=int)
parser.add_argument("--lr", default=1e-3, type=float)
parser.add_argument("--gpu_number", default=0, type=int)
# print args
args = parser.parse_args()
print(args)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# Prepare the loader
train = SkeletonDataset(array_path=args.arraypath, csv_path=args.crossactioncsvpath + "cross_action_train.csv")
val = SkeletonDataset(array_path=args.arraypath, csv_path=args.crossactioncsvpath + "cross_action_val.csv")
train_loader = DataLoader(train, batch_size=args.batchsize, shuffle=True, num_workers=4)
val_loader = DataLoader(val, batch_size=args.batchsize, shuffle=False, num_workers=4)
# get a model
#model = Model3DResnet(num_classes = 120, output_layer = 4)
model = CNNskl()
# if torch.cuda.device_count()>1:
# print("Let's use", torch.cuda.device_count(), "GPUs!")
# model = nn.DataParallel(model)
model.to(device)
# get a optimizer and scheduler
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.SGD(model.parameters(), args.lr, momentum=0.9)
scheduler = ReduceLROnPlateau(optimizer, 'min', patience=1, verbose=True)
#Training the model
train_model(model, criterion, optimizer, args.epochs, train_loader, val_loader, device)
#Accuracy and loss plot
# save_loss_accuracy(dic_pltloss_train, "model_save/loss_train_accuracy_crossubject.csv")
# save_loss_accuracy(dic_pltaccuracy_train1, "model_save/accuracy_train1_crossubject.csv")
# save_loss_accuracy(dic_pltaccuracy_train3, "model_save/accuracy_train3_crossubject.csv")
# save_loss_accuracy(dic_pltloss_val, "model_save/loss_val_accuracy_crossubject.csv")
# save_loss_accuracy(dic_pltaccuracy_val1, "model_save/accuracy_val1_crossubject.csv")
# save_loss_accuracy(dic_pltaccuracy_val3, "model_save/accuracy_val3_crossubject.csv")
# plot_loss(pltloss_train, pltloss_val, namefile = "loss")
# plot_accurracy(pltaccuracy_train1, pltaccuracy_val1, namefile = "accuracy_1")
# plot_accurracy(pltaccuracy_train3, pltaccuracy_val3, namefile = "accuracy_3")
i am still having the same error:
Namespace(arraypath='Datasets/NTU/Skeleton/imagerepresentation/spatioVelo/', batchsize=32, crossactioncsvpath='dataloaders/Labels/cross_action/', crossviewcsvpath='dataloaders/Labels/cross_view/', epochs=200, gpu_number=0, lr=0.001, sequencelength=4)
Traceback (most recent call last):
File "Train.py", line 182, in <module>
train_model(model, criterion, optimizer, args.epochs, train_loader, val_loader, device)
File "Train.py", line 120, in train_model
pred = model(datas)
File "/home/coco/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/media/coco/coco_dev/My_project/Skeleton_image_representation/Models/ModelCnn.py", line 54, in forward
x = F.relu(self.conv1(x.to("cuda:0")))
File "/home/coco/.local/lib/python3.8/site-packages/torch/nn/modules/module.py", line 889, in _call_impl
result = self.forward(*input, **kwargs)
File "/home/coco/.local/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 399, in forward
return self._conv_forward(input, self.weight, self.bias)
File "/home/coco/.local/lib/python3.8/site-packages/torch/nn/modules/conv.py", line 395, in _conv_forward
return F.conv2d(input, weight, bias, self.stride,
RuntimeError: CUDA out of memory. Tried to allocate 28.06 GiB (GPU 0; 10.75 GiB total capacity; 662.97 MiB already allocated; 852.38 MiB free; 664.00 MiB reserved in total by PyTorch)