Hi there,
I’m having a problem with my CUDA when running transfer learned networks. My code is essentially the same as can be found on the PyTorch tutorial page for transfer learning (Transfer Learning for Computer Vision Tutorial — PyTorch Tutorials 2.2.0+cu121 documentation), and the error is as follows:
I used my code to successfully train/test a variety of networks before this error came up, which leads me to believe that the GPU is storing information in memory and not flushing it; any ideas on what I could do to free up this memory?
Thank you very much!
Tomaso
What kind of model are you using now?
Probably the current model just uses more memory so that you are running our of it.
Could you try to lower the batch size a bit and see, if it’s working?
@ptrblck thank you for your quick response!
The model was initially set to Inception v3 when the error first arose (after having it run successfully a number of times), but upon inspection the error also arises when running ResNet, VGG-Net, and AlexNet (all of which had also been run successfully).
I have tried to reduce batch size from 64 down to 32,16,8,4, etc… however the error persists; weirdly enough, while the ‘tried to allocate’ amount goes down (from 98.00MiB to, say, 16.00MiB) when the batch size is smaller, so does the amount of memory which is supposedly free (from 61.64MiB to, say, 12.00MiB), meaning there is still not enough free memory even when the batch size is reduced.
If all models fail now, could you check the GPU memory usage using nvidia-smi?
Maybe some other process uses all the memory and thus you get these OOM errors.
Absolutely, here is the output of the nvidia-smi command:
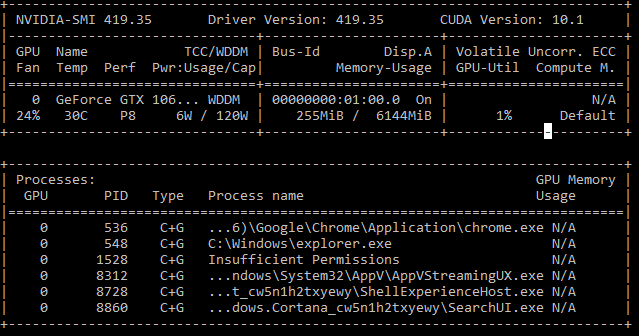
I’m not sure what to infer from this, apart from the fact that it doesn’t look like there is a process taking up much memory. Furthermore, if I monitor the usage during the handful of seconds between launching the script and the rise of the OOM error, the memory usage doesn’t change either; it’s almost as if the GPU isn’t even being called into action before the error arises.
Just to sum up your current issue:
- multiple models were working fine using the GPU (ResNet, VGG, AlexNet)
- after you ran out of memory using Inception_v3, all models run out of memory
-
nvidia-smi shows little memory usage and still all models which previously ran fine, run out of memory
Is that correct?
Yes that is all correct!
Just to add another observation about the GPU behaviour: I re-attempted to run a network with smaller batch-size (even though this had not worked before). Moving down from 64 to 16, surprisingly enough, the error did not arise, and the training process got under way. I then terminated the process, restarted the kernel, and tried again (still with batch-size 16 and the same model), and the error immediately arose.
Don’t know if that is helpful, but in any case thank you very much for all your time and help!
Could you try to repeat the last steps and have a look at nvidia-smi and the processes using the GPU memory?
It seems like the the kernel is not really shutdown and still allocates your memory.
I’ve been playing around with restarting the kernel before every run and it seems to have fixed the majority of the problems! By that I mean the models that were successfully run with batch size 64 earlier are now being successfully run again; and for those that weren’t, decreasing the batch size works in removing the OOM. However, this leads me a final point of inquiry I hope you won’t mind addressing!
All the models successfuly trained with batch size 64 achieved accuracies of ~60% on my dataset, after training for 20 epochs; however, if I run these models again, this time with batch size 32, the testing and training accuracies drop to ~30%, with all other parameters kept the same. I would be happy to run the networks that can’t run with batch size 64 using a lower batch size, but this seems to be having a large effect on my results.
Do you have any idea why this might be happening?
You could try to accumulate the gradients using @albanD’s suggestions posted here and thus artificially create a larger batch size. This might help the convergence of your model.
I will try that, thank you very much again for all your time and help!