for i in range(len(videos)):
try:
video_d = np.load(os.path.join(VIDEO_DATA_PATH,videos[i]))
video_d = video_d.transpose(0, 3, 1, 2)
for j in range(video_d.shape[0]):
video_d[j] = (video_d[j] - video_d[j].min())/(video_d[j].max() - video_d[j].min())
video_d = torch.from_numpy(video_d)
print(video_d.shape)
video_data = Variable(video_d) # this needs to be array of still frames
audio_d = np.load(os.path.join(AUDIO_DATA_PATH,audios[i]))
audio_d = torch.from_numpy(audio_d)
audio_d = audio_d.view(audio_d.size()[0], audio_d.size()[2], audio_d.size()[1])
audio_data = Variable(audio_d)
MINIBATCHSIZE = video_d.size()[0]
still_frame = video_d[2]
# To show a still frame
# show_image(still_frame.numpy())
still_frame = still_frame.view(1, still_frame.size()[0], still_frame.size()[1], still_frame.size()[2])
still_frame = Variable(still_frame.repeat(MINIBATCHSIZE, 1, 1, 1))
noise_data = Variable(torch.rand(MINIBATCHSIZE, 1, NOISE_OUTPUT))
# print(noise_data.size())
noise_data = noise_data.data.resize_(noise_data.size()).normal_(0, 0.6)
# plt.imshow(noise_data.numpy())
# plt.show()
# print(noise_data)
# print(noise_data.size())
if cuda:
audio_data = audio_data.cuda()
video_data = video_data.cuda()
noise_data = noise_data.cuda()
still_frame = still_frame.cuda()
# Train Generator
# print(audio_data.size())
# print(video_data.size())
# print(still_frame.size())
optimizer_unet.zero_grad()
optimizer_fd.zero_grad()
optimizer_sd.zero_grad()
gen_frames = unet(still_frame, audio_data, noise_data)
# print(gen_frames[0])
# img = gen_frames[random.randint(0, MINIBATCHSIZE -1)].cpu().detach().numpy().transpose(1, 2, 0)
# cv2.imwrite('./logs/'+str(time.time())+'.jpg', img)
#print(gen_frames.size())
#img = gen_frames[0].detach().numpy()
#show_image(img)
#return
# print("Generated frames ", gen_frames.size())
Lambda = 10
# print(video_data[0])
# print(torch.mean(torch.mean(torch.mean(torch.abs(video_data - gen_frames), 1), 1), 1))
print(torch.mean(torch.mean(torch.mean(torch.mean(torch.abs(video_data - gen_frames), 1), 1), 1)))
# return
l1_loss = torch.mean(torch.mean(torch.mean(torch.mean(torch.abs(video_data - gen_frames), 1), 1), 1))
print(l1_loss)
# return
out1 = frame_discriminator(video_data, still_frame)
out2 = frame_discriminator(gen_frames, still_frame)
out3 = sequence_discriminator(video_data, audio_data)
out4 = sequence_discriminator(gen_frames, audio_data)
# print(out1)
# print("out is ", out3.size())
# d_loss = -dis_loss(out2, out1, out4 ,out3)
frame_loss = fdis_loss(out2, out1)
sequence_loss = sdis_loss(out4, out3)
d_loss = -(frame_loss + sequence_loss)
g_loss = -gen_loss(out2, out4) + Lambda*l1_loss
g_loss.backward(retain_graph=True)
optimizer_unet.step()
d_loss.backward()
optimizer_fd.step()
optimizer_sd.step()
print("G loss {} FD loss {} SD loss {}".format(g_loss.data, frame_loss.data, sequence_loss.data))
batch_g_loss += g_loss.data
batch_d_loss += d_loss.data
tock = time.time()
print("Epoch {}, Done for file: {} Total time elapsed {} hr".format(epoch, videos[i], (tock-tick)/(60*60)))
except Exception as e:
rejected += 1
print(e)
print("Something went wrong with the file {}".format(videos[i]))
By “separated my discriminator loss function” I assume you mean that you are now using frame_loss and sequence_loss, which apparently were calculated together before this experiment?
If you just changes this line:
d_loss = -dis_loss(out2, out1, out4 ,out3)
to these
frame_loss = fdis_loss(out2, out1)
sequence_loss = sdis_loss(out4, out3)
d_loss = -(frame_loss + sequence_loss)
, it’s a bit strange, as I assume dis_loss just summed both losses as well.
I’m not sure how your training routine works exactly, but are you sure you need retain_graph=True for your generator backward?
Also, would it be possible to update the discriminator first and clear its intermediate variables before updating the generator, as this would save some memory. The DCGAN example gives a good overview of what I mean.
A small side note regarding the code: Variables are deprecated sind PyTorch 0.4.0, so that you can directly use tensors now. If you need gradient for a particular tensor, just set requires_grad=True when instantiating it. The volatile argument was replaced with a with statement:
with torch.no_grad():
# no gradients can be calculated
for data, target in val_loader:
...
I was getting an error when I didn’t use retain_graph=True, error said use retain_graph=True because it was not able to backpropagate, and the reason I separated discriminator loss because i wanted to see the outputs for the both the discriminators
I am kinda confused in this 1 generator 2 discriminator GAN, can you please give me a guideline that how should i approach it and what to backpropagate first discriminator or generator and what do you mean by clearing intermediate variables before updating
Yeah, you are right. Since you call d_loss.backward right after it, you need to retain the gradients.
Well, it seems in your setup you have one generator and two discriminators, one for frames and the other for sequences.
In the vanilla DCGAN training, you start by upgrading the discriminator.
Here the gradients for D using real samples are calculated. Note that no update step is performed yet.
In this section we use G to generate a fake sample, detach it so that no gradients will be calculated in G, and feed it to D to train it with this fake sample. After the backward call was called, the optimizer updated the parameters of D.
Finally in these lines of code we update G using the fake sample we created before, but this time without detaching it when passing to D, and using fake labels.
I’m not sure, how frame/sequence_discriminator of the loss functions are implemented, but you should take care that the right gradients are calculated for each model.
However, I think these points are unrelated to your OOM issue.
So back to the original question: if you use -dis_loss() then everything works, but if you split it to frame_loss and sequence_loss you get the OOM error?
Could you share the implementation of dis_loss?
Hey,
Sorry for late reply, these are my implementations of loss dis_loss is the combined loss and ‘fdis_loss’ and ‘sdis_loss’ are the separated ones
def dis_loss(FDwG1, FDwO1, SDwG2, SDwO2 ):
return (
torch.mean(torch.log(EPS + FDwO1)) +
torch.mean(torch.log(EPS + 1 - FDwG1)) +
torch.mean(torch.log(EPS + SDwO2)) +
torch.mean(torch.log(EPS + 1 - SDwG2))
)
def fdis_loss(FDwG1, FDwO1):
return (
torch.mean(torch.log(EPS + FDwO1)) +
torch.mean(torch.log(EPS + 1 - FDwG1))
)
def sdis_loss(SDwG2, SDwO2):
return (
torch.mean(torch.log(EPS + SDwO2)) +
torch.mean(torch.log(EPS + 1 - SDwG2))
)
FDwG1 is the output with generated images
FDwO1 is the output with original images
SDwG2 is the output with generated images
SDwO2 is the output with original images
EPS is the epsilon value , to care of infinite value of log,
Please refer the image down below , this is the loss i tried to implement
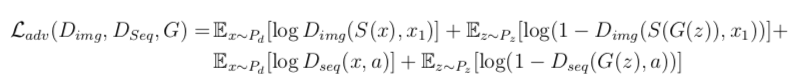
Thanks for the code. I’m still not sure, why the OOM memory should only be thrown once you separate the addition into two separate functions.
Is this behavior deterministic, i.e. could you reproduce it?