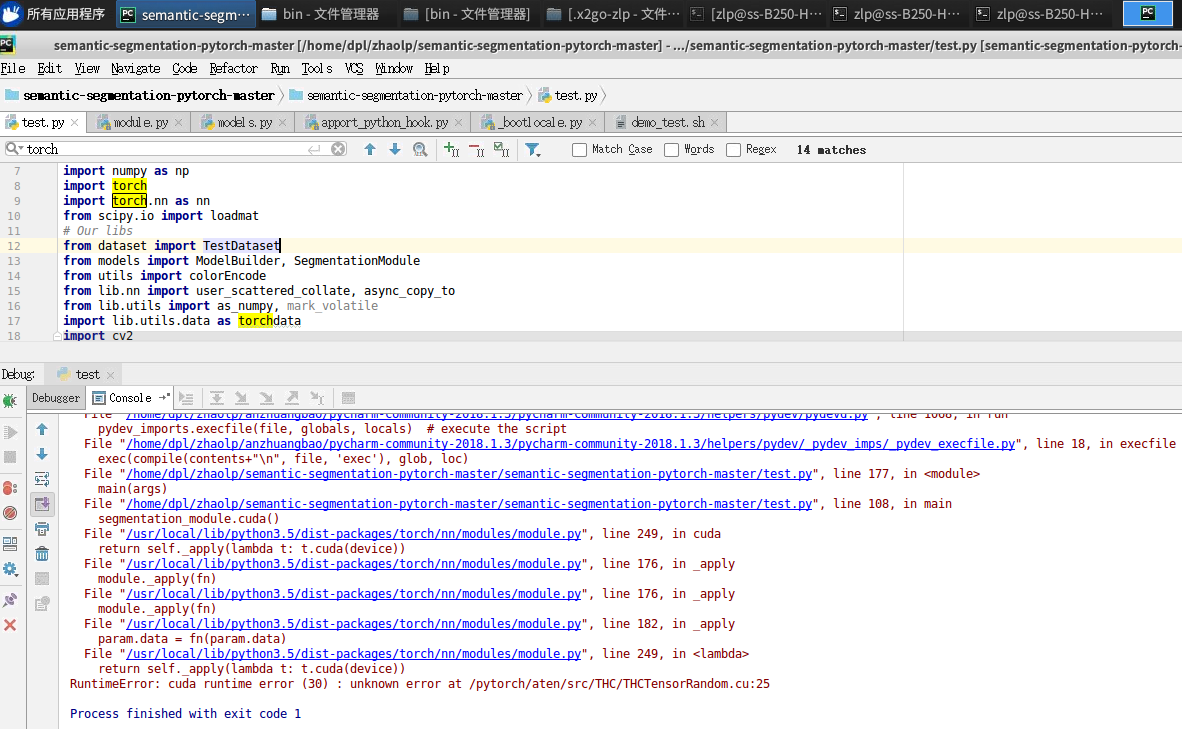
This is my code:
System libs
import os
import datetime
import argparse
from distutils.version import LooseVersion
Numerical libs
import numpy as np
import torch
import torch.nn as nn
from scipy.io import loadmat
Our libs
from dataset import TestDataset
from models import ModelBuilder, SegmentationModule
from utils import colorEncode
from lib.nn import user_scattered_collate, async_copy_to
from lib.utils import as_numpy, mark_volatile
import lib.utils.data as torchdata
import cv2
def visualize_result(data, preds, args):
colors = loadmat(‘data/color150.mat’)[‘colors’]
(img, info) = data
# prediction
pred_color = colorEncode(preds, colors)
# aggregate images and save
im_vis = np.concatenate((img, pred_color),
axis=1).astype(np.uint8)
img_name = info.split('/')[-1]
cv2.imwrite(os.path.join(args.result,
img_name.replace('.jpg', '.png')), im_vis)
def test(segmentation_module, loader, args):
segmentation_module.eval()
for i, batch_data in enumerate(loader):
# process data
batch_data = batch_data[0]
segSize = (batch_data['img_ori'].shape[0],
batch_data['img_ori'].shape[1])
img_resized_list = batch_data['img_data']
with torch.no_grad():
pred = torch.zeros(0, args.num_class, segSize[0], segSize[1])
for img in img_resized_list:
feed_dict = batch_data.copy()
feed_dict['img_data'] = img
del feed_dict['img_ori']
del feed_dict['info']
feed_dict = async_copy_to(feed_dict, args.gpu_id)
# forward pass
pred_tmp = segmentation_module(feed_dict, segSize=segSize)
pred = pred + pred_tmp.cpu() / len(args.imgSize)
_, preds = torch.max(pred, dim=1)
preds = as_numpy(preds.squeeze(0))
# visualization
visualize_result(
(batch_data['img_ori'], batch_data['info']),
preds, args)
print('[{}] iter {}'
.format(datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"), i)
def main(args):
torch.cuda.set_device(args.gpu_id)
# Network Builders
builder = ModelBuilder()
net_encoder = builder.build_encoder(
arch=args.arch_encoder,
fc_dim=args.fc_dim,
weights=args.weights_encoder)
net_decoder = builder.build_decoder(
arch=args.arch_decoder,
fc_dim=args.fc_dim,
num_class=args.num_class,
weights=args.weights_decoder,
use_softmax=True)
crit = nn.NLLLoss(ignore_index=0)
segmentation_module = SegmentationModule(net_encoder, net_decoder, crit)
# Dataset and Loader
list_test = [{'fpath_img': args.test_img}]
dataset_val = TestDataset(
list_test, args, max_sample=args.num_val)
loader_val = torchdata.DataLoader(
dataset_val,
batch_size=args.batch_size,
shuffle=False,
collate_fn=user_scattered_collate,
num_workers=5,
drop_last=True)
segmentation_module.cuda()
# Main loop
test(segmentation_module, loader_val, args)
print('Inference done!')
if name == ‘main’:
assert LooseVersion(torch.version) >= LooseVersion(‘0.4.0’),
‘PyTorch>=0.4.0 is required’
parser = argparse.ArgumentParser()
# Path related arguments
#parser.add_argument('--test_img', default='./TEST_IMG/test_img/ADE_val_00001519.jpg',help='folder to test path')
parser.add_argument('--test_img', default='/home/dpl/zhaolp/semantic-segmentation-pytorch-master/semantic-segmentation-pytorch-master/TEST_IMG/test_img/ADE_val_00001519.jpg',help='folder to test path')
parser.add_argument(’–model_path’, default=’./MODEL_PATH/model_path’,
parser.add_argument('--model_path', default='/home/dpl/zhaolp/semantic-segmentation-pytorch-master/semantic-segmentation-pytorch-master/MODEL_PATH/model_path',
help='folder to model path')
parser.add_argument('--suffix', default='_epoch_20.pth',
help="which snapshot to load")
# Model related arguments
parser.add_argument('--arch_encoder', default='resnet50_dilated8',
help="architecture of net_encoder")
parser.add_argument('--arch_decoder', default='ppm_bilinear_deepsup',
help="architecture of net_decoder")
parser.add_argument('--fc_dim', default=2048, type=int,
help='number of features between encoder and decoder')
# Data related arguments
parser.add_argument('--num_val', default=-1, type=int,
help='number of images to evalutate')
parser.add_argument('--num_class', default=150, type=int,
help='number of classes')
parser.add_argument('--batch_size', default=1, type=int,
help='batchsize. current only supports 1')
parser.add_argument('--imgSize', default=[300, 400, 500, 600],
nargs='+', type=int,
help='list of input image sizes.'
'for multiscale testing, e.g. 300 400 500')
parser.add_argument('--imgMaxSize', default=1000, type=int,
help='maximum input image size of long edge')
parser.add_argument('--padding_constant', default=8, type=int,
help='maxmimum downsampling rate of the network')
parser.add_argument('--segm_downsampling_rate', default=8, type=int,
help='downsampling rate of the segmentation label')
# Misc arguments
parser.add_argument('--result', default='.',
help='folder to output visualization results')
parser.add_argument('--gpu_id', default=0, type=int,
help='gpu_id for evaluation')
args = parser.parse_args()
print(args)
# absolute paths of model weights
args.weights_encoder = os.path.join(args.model_path,
'encoder' + args.suffix)
args.weights_decoder = os.path.join(args.model_path,
'decoder' + args.suffix)
assert os.path.exists(args.weights_encoder) and \
os.path.exists(args.weights_encoder), 'checkpoint does not exitst!'
if not os.path.isdir(args.result):
os.makedirs(args.result)
main(args)