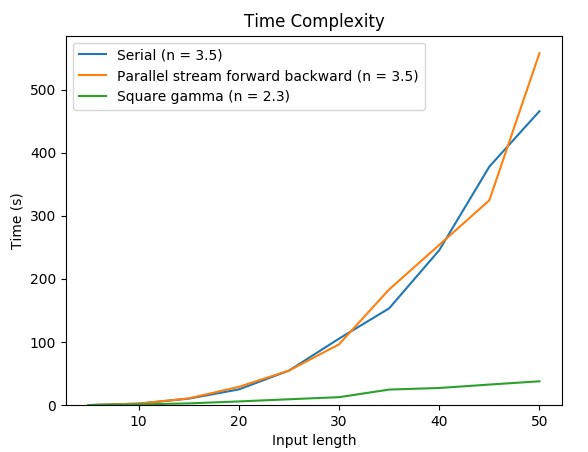
I’m trying to use CUDA streams to run n operations in parallel on a single GPU. However, based on a simple test script I wrote, running 100,000 matrix-vector multiplications in parallel streams actually takes longer than running them in serial. I’m hoping that someone can explain to me why this is the case. Does it have to do with the fact that the default stream synchronizes with all other streams?
test_streams.py:
import argparse
import datetime
import torch
def map_reduce_serial(args, map_func, reduce_func):
results = []
for arg in args:
results.append(map_func(arg))
return reduce_func(results)
def map_reduce_parallel(device, args, map_func, reduce_func):
results = []
main_stream = torch.cuda.current_stream(device)
for arg in args:
stream = torch.cuda.Stream(device)
stream.wait_stream(main_stream)
with torch.cuda.stream(stream):
results.append(map_func(arg))
main_stream.wait_stream(stream)
return reduce_func(results)
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--parallel', action='store_true', default=False)
parser.add_argument('-n', type=int, default=100000)
args = parser.parse_args()
device = torch.device('cuda')
W = torch.rand((20, 20), device=device)
def map_func(i):
x = torch.rand((20,), device=device)
return W * x
def reduce_func(results):
return torch.stack(results).sum().item()
if args.parallel:
map_reduce_func = lambda *args: map_reduce_parallel(device, *args)
else:
map_reduce_func = map_reduce_serial
torch.cuda.reset_max_memory_allocated(device)
start_time = datetime.datetime.now()
result = map_reduce_func(range(args.n), map_func, reduce_func)
torch.cuda.synchronize(device)
duration = datetime.datetime.now() - start_time
memory = torch.cuda.max_memory_allocated(device)
print('result:', result)
print('time:', duration)
print('memory:', memory)
if __name__ == '__main__':
main()
Running in serial:
$ python test_streams.py
result: 9972008.0
time: 0:00:02.027303
memory: 364826624
Running in parallel:
$ python test_streams.py --parallel
result: 9594629.0
time: 0:00:05.606621
memory: 364826624