Hi
I am using Torch 1.7.1 and Cuda 10.1 in Titan XP.
but when i use .cuda() command,it always takes more than 10 mins.
According to the same problem answered before,i try to use torch.cuda.synchronize() before the .cuda() command,but synchronize still needs more than 10mins.
Is there anyway to accelerate this?
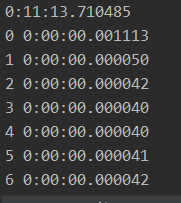
Here’s my code and result, thanks in advance.
import torch
from datetime import datetime
torch.cuda.set_device(2)
t1 = datetime.now()
torch.cuda.synchronize()
print(datetime.now() - t1)
for i in range(10):
x = torch.randn(10, 10, 10, 10) # similar timings regardless of the tensor size
t1 = datetime.now()
x.cuda()
print(i, datetime.now() - t1)
Thanks,but I’m not authorized to update gpu driver,thus i can only use cuda 10.1.
I tried to update pytorch to 1.8.1,which is the latest release i can get with cuda 10.1,but the problem remains.
Besides,the performance used to be great using pytorch 1.7.1,so i assume it is not the version problem.
The issue sounds a bit as if you are JIT compiling for your architecture.
Since you are using a Titan Xp, it should have a supported compute capability of 6.1. Do you have any other devices in this machine which might be older?
If so, could you mask the Titan Xp via export CUDA_VISIBLE_DEVICES=ID where ID denotes the GPU id and see if you are hitting the same issue again?