I am new to pytorch but I do program some in CUDA (enough to be dangerous).
My understanding is that when, say, a numpy array is passed as a tensor, then it is in GPU memory. It can then be manipulated by the GPU and finally transferred back to the CPU memory.
Then, there are CUDA tensors. CUDA also operates on GPU memory.
What is the difference?
Can GPU profiling be done in pytorch as it can be done in CUDA with the nvidia profiler?
No, numpy arrays will share the same underlying data, if tensor = torch.from_numpy(array) is used (no copy triggered) and can be pushed to the GPU via tensor = tensor.to('cuda'), where operations on this tensor will be executed on the GPU.
I’m not sure what CUDA tensors are. If you are referring to PyTorch tensors on the GPU, then note that each tensor has a device associated with it and can be stored on different devices, such as the CPU, GPU, TPU, etc.
I would only request one more bit of clarification, if I may. I can load a .cu file into Nsight Systems Compute (although I had to replace my Graphics card from Pascal architecture to Turing architecture, ouch). But can Nsight read a python script (.py) and interpret the pytorch cuda references?
Yes, you can fine the CLI options here. The most basic would be nsys profile python script.py and you could add more options e.g. to create backtraces etc.
It depends on the operations you are using. If the current method synchronizes the code by e.g. pushing a value to the CPU, then you could see synchronizations in the timeline.
The majority of ops in PyTorch do not synchronize besides a few exceptions (e.g. some methods in the torch.linalg namespace check the output info to give you an error in case the linalg operation failed. This should be relaxed in upcoming PyTorch releases).
Yes, you would see the runtimes in the profile. Note that the profiling itself might add overhead.
Thank you …
I have just found that the delay was caused by converting my float tensors into double precision at the beginning of my script e.g. tensor_A.double() … not sure why … But I decided to remove the conversion …
Hi! I would like to ask more questions about Nsight profiling vs using torch.cuda.Event…
The problem that I have is that the runtime of Nsight profiling is much faster (about 14 ms) than using torch.cuda.Event (about 74 ms)…
My questions are
What are the differences between the two? Is it because the Nsight profiling is running on Asynchronization mode, but the using torch.cuda.Event is running on Synchronization mode.
Which of these two results should I use as the reference for the runtime performance of my network?
Details on how I ran Nsight Profiler and torch.cuda.event are as follows:
Nsight Profiler. I have used the Nsight Profiler with command line
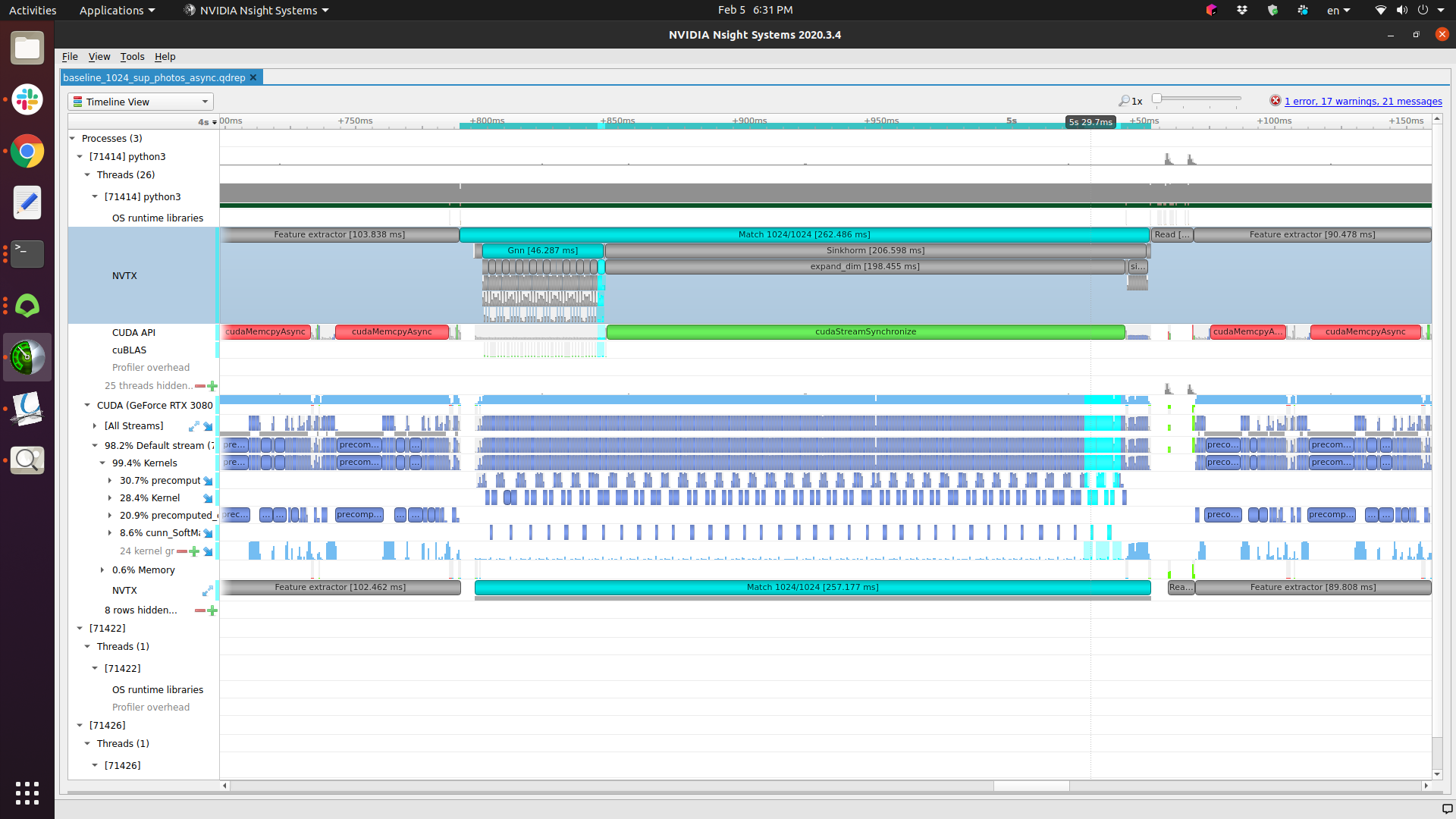
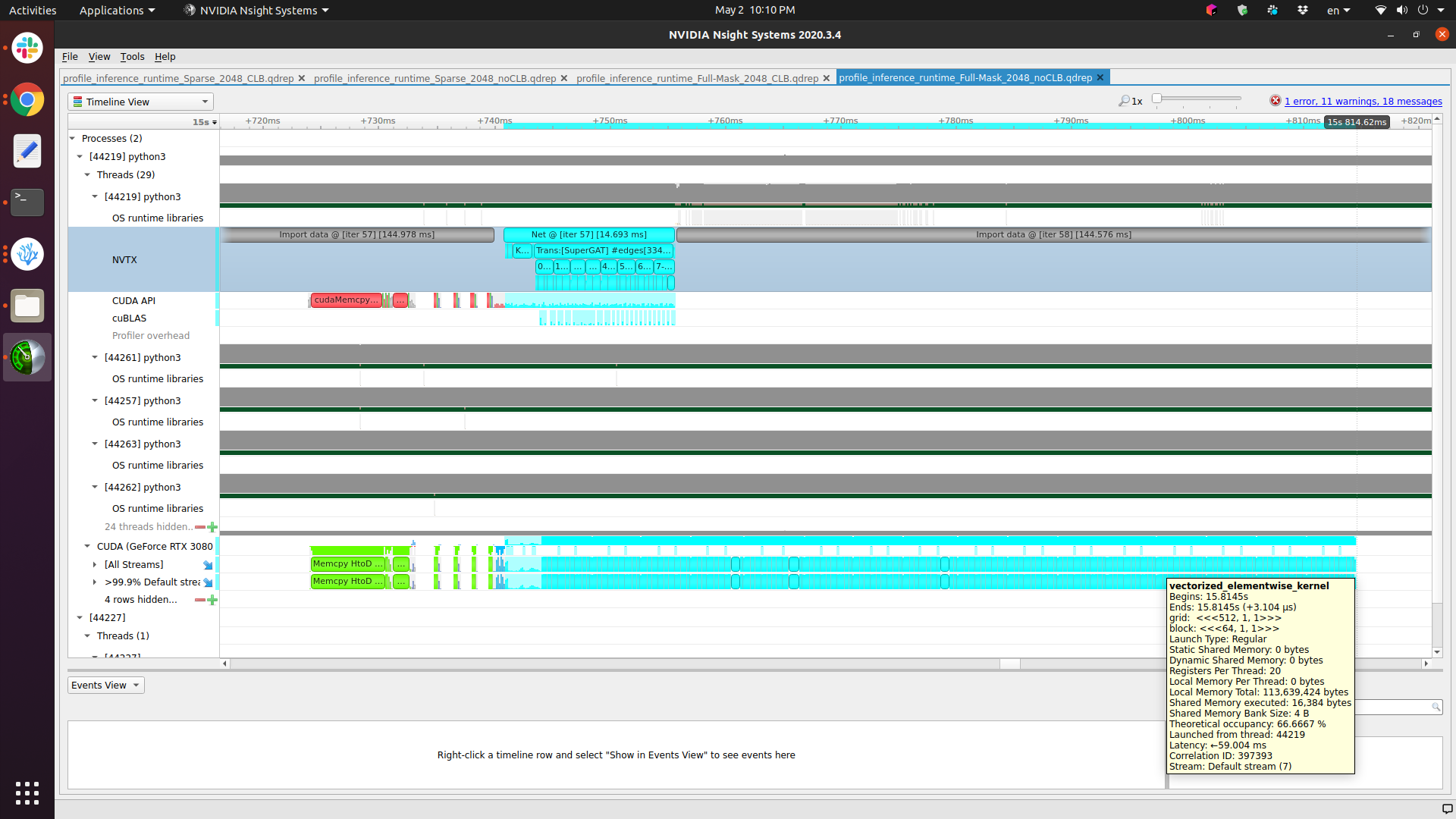
which gives the following runtime results. Notice that the (below) light blue range measured at CUDA is much longer than the (above) runtime measured at NVTX (also denoted as Net @ [iter 57] 14.693 ms):
I assume you are checking the NVTX timeline and compare it to the kernel times in the CUDA GeForce... timeline. If so, it seems that the kernel launches are shown in the first one and you see that the CPU seems to run ahead with the data loading (assuming “Import data…” is used in the dataset) while the GPU is executing the workload.
Yes, the CPU part is in my dataset class (torch.utils.data.Dataset) … That is in def __get_item__(self, idx), I have to download numpy data from .h5 file (I used it for the smaller file size) and convert them into pytorch tensor and cuda device.
So, could you further confirm how should I decide which part is the runtime of my network (inference)…? I have marked it as Net @ [iter 57] 14.693 ms with NVTX…
However, the reason for me to be quite confused is that …in the previously attached Nsight profiler, the (below) light blue range measured at CUDA is much longer than the (above) runtime measured at NVTX (Net @ [iter 57] 14.693 ms ). So, was it 14.693 ms? (But when I measured with Torch.cuda.event, the runtime was much longer (73ms)…? )
Or the longer range at CUDA than NVTX in the Nsight Profiler does not mean that it takes longer? Did I miss measuring anything or doing something wrong?
I am so sorry. I am quite new in understanding the Profiler. Please help.