I am pretty new at using pytorch. Currently, I have been trying to understand the concepts of using CUDA for performing better loading data and increasing speed for training models.
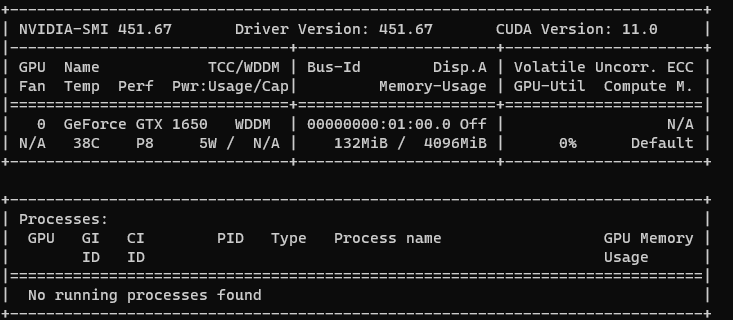
I took a look into my system, I currently have an NVIDIA GTX1650 that contains CUDA v-11, yet I see that hasn’t been installed. Normally, when I work in python, I use virtual environments to set all the libraries I use for a project. With pytorch, I saw you can run on the CPU or use CUDA.
Currently, the latest version is pytorch 2.1.0 which goes until CUDA 11.8 or 12.1. I may have a couple of questions regarding how to properly set my graphics card for usage.
1.) Since the drivers say the latest version is CUDA 11. Does that mean I have to download the 11.0 CUDA from NVIDIA? Since other versions would not work?
2.) Pytorch versioning must also meet the highest available CUDA version? In other words, downgrade pytorch 2.1.0?
3.) Is there a better way than installing for local venvs? (Conda for example).
No, you don’t need to download a full CUDA toolkit and would only need to install a compatible NVIDIA driver, since PyTorch binaries ship with their own CUDA dependencies. Your current driver should allow you to run the PyTorch binary with CUDA 11.8, but would fail to run the binary with CUDA 12.1 Update 1 as it’s too old.
I don’t understand this question, since PyTorch 2.1.0 is the latest release so what do you want to downgrade from?
You don’t need to install virtual environments if you want to use a single PyTorch version only.
hey! can you share whether torch 2.2.0 (latest) would support the latest 12.3 update for cuda
Facing this issue -
Installed CUDA version 12.3 does not match the version torch was compiled with 11.8, unable to compile cuda/cpp extensions without a matching cuda version
If you want to build a custom CUDA extension, your locally installed CUDA toolkit has to match the one used in the binaries in the major version and ideally should also match the minor version. Different major releases will error out.
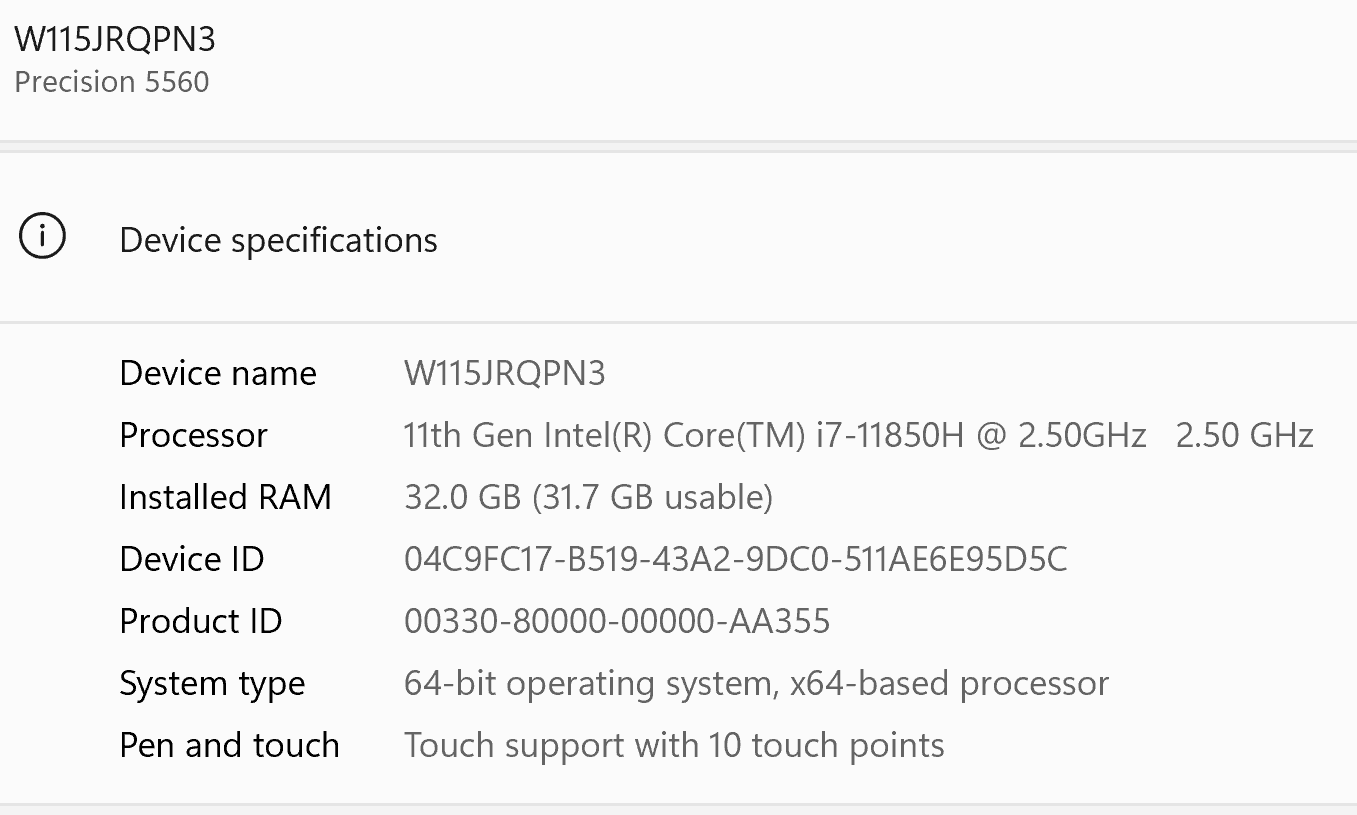
I have ‘NVIDIA T1200 Laptop GPU’ in my laptop. Which version of Cuda and Torch will go hand in hand. I tried installing ‘cuda_12.3.2_546.12_windows’ & ‘cuda_11.0.2_451.48_win10’. But failing at both. I have window 11 installed in my system. Here are my system specifications:
I don’t know what exactly you want to build, but note that your locally installed CUDA toolkit won’t be used unless you want to build PyTorch from source or a custom CUDA extension. Could you thus describe what exactly you want to build?
using above command the conda command remain in a loop. When I remove pytroch-cuda=11.8, the command successfully run and all other lib. are installed.
Next I enter the below command to install pytorch-cuda:
Unfortunately, it is not installed and I receive the following message.
Collecting package metadata (current_repodata.json): - WARNING conda.models.version:get_matcher(542): Using .* with relational operator is superfluous and deprecated and will be removed in a future version of conda. Your spec was 1.7.1., but conda is ignoring the . and treating it as 1.7.1
done
Solving environment: failed with initial frozen solve. Retrying with flexible solve.
Solving environment: failed with repodata from current_repodata.json, will retry with next repodata source.
Solving environment: /
I was wondering whether you could know what would be issue.
@ptrblck
Thanks for your quick reply. The thing is that I have created several new conda env., even I tried removing the whole Anaconda folder and reinstall again Anaconda. However, it did not work. When I enter the command to install pytorch, torchvision, and torchaudio, everything is fine. Once I add pytorch-cuda to this command, or I want to install pytorch-cuda after others, such as pytorch and torchvision, the install command remains in loop and finally stopped with the error
Solving environment: Killed
One more thing, I have a yml file including pytorch 1.13 and cuda 11.6. It is installed with conda successfully. However, the problem is with new version.
The reason I want to install new pytorch version is because in pytorch 1.13 it seems the output of hook are not stable. And the hook outputs are slightly changed in different running.
I’ve just installed the latest stable conda package in a new environment and it works fine in this thread. If conda has issues with the conflict resolution or needs too much RAM you could consider using mamba which should be faster.
where I can find the details like for a specific cuda version which version of pytorch is compatible
I have cuda11.4 what should be the pytorch version
Hi,
I did install cuda and pytorch using this command: "conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia"
and now I have the following packages on my conda env:
cuda-cudart 11.7.99 0 nvidia
cuda-cupti 11.7.101 0 nvidia
cuda-libraries 11.7.1 0 nvidia
cuda-nvrtc 11.7.99 0 nvidia
cuda-nvtx 11.7.91 0 nvidia
cuda-runtime 11.7.1 0 nvidia
nvidia-cuda-cupti-cu11 11.7.101 pypi_0 pypi
nvidia-cuda-nvrtc-cu11 11.7.99 pypi_0 pypi
nvidia-cuda-runtime-cu11 11.7.99 pypi_0 pypi
pytorch 2.0.1 py3.8_cuda11.7_cudnn8.5.0_0 pytorch
pytorch-cuda 11.7 h778d358_5 pytorch
pytorch-mutex 1.0 cuda pytorch
$ conda list | grep ‘torch’
ffmpeg 4.3 hf484d3e_0 pytorch
pytorch 2.0.1 py3.8_cuda11.7_cudnn8.5.0_0 pytorch
pytorch-cuda 11.7 h778d358_5 pytorch
pytorch-mutex 1.0 cuda pytorch
pytorch-triton 2.1.0+440fd1bf20 pypi_0 pypi
torch-tb-profiler 0.4.1 pypi_0 pypi
torchaudio 2.1.0.dev20230628+cu118 pypi_0 pypi
torchtriton 2.0.0 py38 pytorch
torchvision 0.16.0.dev20230628+cu118 pypi_0 pypi
but I still get the following error:
RuntimeError: CUDA error: no kernel image is available for execution on the device
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
I get similar output when I run "python -c “import torch; print(torch.version); print(torch.version.cuda); print(torch.cuda.get_device_properties(0)); print(torch.randn(1).cuda())”
" so what does this error mean:
Should I uninstall the normal pytorch (the non cuda version)?
The error might be raised by another library not building for your GPU architecture as PyTorch itself is able to use your device. You should try to narrow down which line of code fails and which library is used.