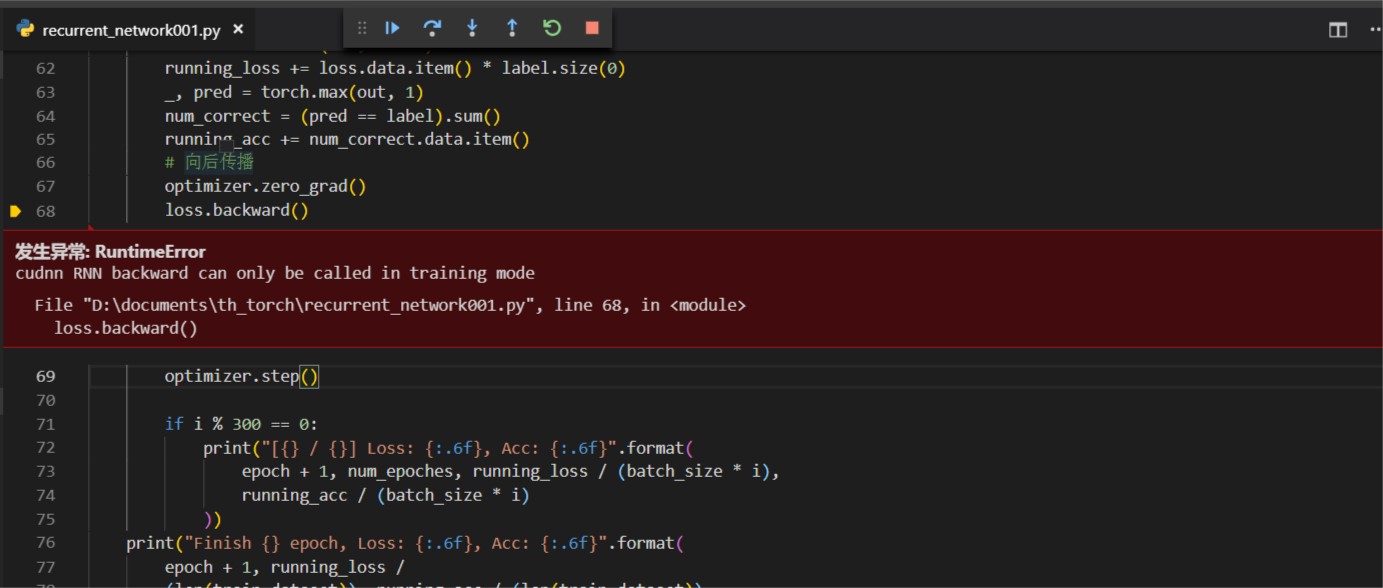
I write a code but it has a error, I can not fix it
my environment is : cuda9 + cudnn 7.1 python=3.6.6 pytorch =1.0.1
my code:
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
# 定义超参数
batch_size = 100
learning_rate = 1e-3
num_epoches = 20
# 下载训练集 MNIST 手写数字训练集
train_dataset = datasets.MNIST(
root='D:/data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(
root='D:/data', train=False, transform=transforms.ToTensor())
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
# 定义 Recurrent Network 模型
class Rnn(nn.Module):
def __init__(self, in_dim, hidden_dim, n_layer, n_class):
super(Rnn, self).__init__()
self.n_layer = n_layer
self.hidden_dim = hidden_dim
self.lstm = nn.LSTM(in_dim, hidden_dim, n_layer, batch_first=True)
self.classifiers = nn.Linear(hidden_dim, n_class)
def forward(self, x):
out, _ = self.lstm(x)
out = out[:, -1, :]
out = self.classifiers(out)
return out
model = Rnn(28, 128, 2, 10)
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(num_epoches):
running_loss = 0.
running_acc = 0.
for i, data in enumerate(train_loader, 1):
img, label = data
b, c, h, w = img.size()
assert c == 1, 'Channel must be 1'
img = img.squeeze(1)
img = Variable(img).cuda()
label = Variable(label).cuda()
# 向前传播
out = model(img)
loss = criterion(out, label)
running_loss += loss.data.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
running_acc += num_correct.data.item()
# 向后传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 300 == 0:
print("[{} / {}] Loss: {:.6f}, Acc: {:.6f}".format(
epoch + 1, num_epoches, running_loss / (batch_size * i),
running_acc / (batch_size * i)
))
print("Finish {} epoch, Loss: {:.6f}, Acc: {:.6f}".format(
epoch + 1, running_loss /
(len(train_dataset)), running_acc / (len(train_dataset))
))
model.eval()
eval_loss = 0.
eval_acc = 0.
for data in test_loader:
img, label = data
b, c, h, w = img.size()
assert c == 1, "channel must be 1"
img = img.squeeze(1)
with torch.no_grad():
img = Variable(img).cuda()
label = Variable(label).cuda()
out = model(img)
loss = criterion(out, label)
eval_loss += loss.data.item() * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
eval_acc += num_correct.data.item()
print('Test Loss: {:.6f}, Acc: {:.6f}'.format(eval_loss / (len(
test_dataset)), eval_acc / (len(test_dataset))))
# 保存模型
torch.save(model.state_dict(), './rnn.pth')
the error:
RuntimeError
cudnn RNN backward can only be called in training mode
File "D:\documents\th_torch\recurrent_network001.py", line 68, in <module>
loss.backward()