I tried to make Custom Dataset with simple tensor.
But, I couldn’t fix this Error. I don’t know what causes this, at all.
Could you help me?
Thank you.
Could you rerun the code with num_workers=0 and check, if you would see a better error message?
The current screenshot shows only that a worker is crashing.
Note that you can post code snippets by wrapping them into three backticks ```, which is easier to debug and would the search engine also allow to index the code so that other users could find it. 
train_loader = list()
test_loader = list()
for node in range(node_cnt):
train_loader.append(torch.utils.data.DataLoader(train_dataset[node], num_workers=0, batch_size=128, pin_memory=True, shuffle=True))
#train_loader.append(torch.utils.data.DataLoader(train_dataset[node], **train_kwargs))
test_loader.append(torch.utils.data.DataLoader(train_dataset[node], num_workers=0, batch_size=128, pin_memory=True, shuffle=True))
#train_loader.append(torch.utils.data.DataLoader(train_dataset[node], **test_kwargs))
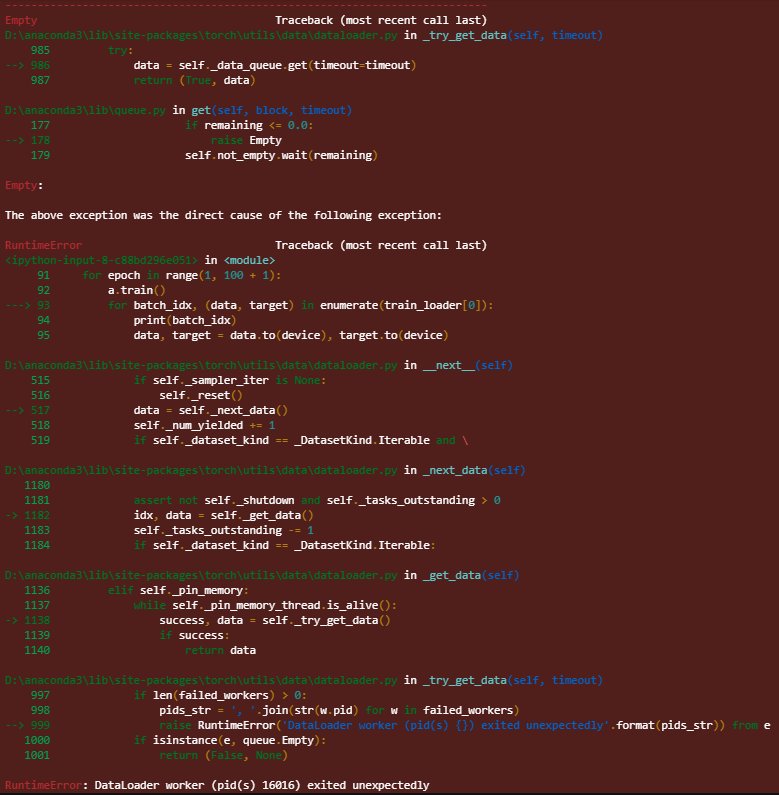
Empty Traceback (most recent call last)
D:\anaconda3\lib\site-packages\torch\utils\data\dataloader.py in _try_get_data(self, timeout)
985 try:
→ 986 data = self._data_queue.get(timeout=timeout)
987 return (True, data)
D:\anaconda3\lib\queue.py in get(self, block, timeout)
177 if remaining <= 0.0:
→ 178 raise Empty
179 self.not_empty.wait(remaining)
Empty:
The above exception was the direct cause of the following exception:
RuntimeError Traceback (most recent call last)
in
92 for epoch in range(1, 100 + 1):
93 a.train()
—> 94 for batch_idx, (data, target) in enumerate(train_loader[0]):
95 data, target = data.to(device), target.to(device)
96 optimizer.zero_grad()
D:\anaconda3\lib\site-packages\torch\utils\data\dataloader.py in **next**(self)
515 if self._sampler_iter is None:
516 self._reset()
→ 517 data = self._next_data()
518 self._num_yielded += 1
519 if self._dataset_kind == _DatasetKind.Iterable and \
D:\anaconda3\lib\site-packages\torch\utils\data\dataloader.py in _next_data(self)
1180
1181 assert not self._shutdown and self._tasks_outstanding > 0
→ 1182 idx, data = self._get_data()
1183 self._tasks_outstanding -= 1
1184 if self._dataset_kind == _DatasetKind.Iterable:
D:\anaconda3\lib\site-packages\torch\utils\data\dataloader.py in _get_data(self)
1136 elif self._pin_memory:
1137 while self._pin_memory_thread.is_alive():
→ 1138 success, data = self._try_get_data()
1139 if success:
1140 return data
D:\anaconda3\lib\site-packages\torch\utils\data\dataloader.py in _try_get_data(self, timeout)
997 if len(failed_workers) > 0:
998 pids_str = ', '.join(str(w.pid) for w in failed_workers)
→ 999 raise RuntimeError(‘DataLoader worker (pid(s) {}) exited unexpectedly’.format(pids_str)) from e
1000 if isinstance(e, queue.Empty):
1001 return (False, None)
RuntimeError: DataLoader worker (pid(s) 14792) exited unexpectedly
After I changed ‘kwargs’, it worked well. Thank you for the reply!!!
I’m glad to get your reply, the famous programmer in this forum.
Setting the number of workers to 0 was only a suggestion to hopefully get a better error message and it’s unfortunately not a solution, since your performance would suffer.
However, since num_workers=0 seems to work fine, while multiple workers crash, could you check if you have enough shared memory on your machine?
Could you teach me how to check shared memory on my machine?
My machine specs,
- OS : Windows 10 Pro
- Processor : AMD Ryzen 7 2700X
- RAM : 16.0GB
- GPU : GeForce GTX 1050
- Platform : Anaconda (conda 4.10.1)
- Environment : CUDA 11.3, Pytorch 1.8.1
Your suggestion worked! When I passed num_workers=1, “worker exited unexpectedly” appears again.
I have 64 DataLoaders. If any DataLoader has num_workers=1, “worker exited unexpectedly” appears.
training-crashes-due-to-insufficient-shared-memory-shm-nn-dataparallel
I couldn’t find any suggestion about how to increase shared memory in Windows Environment. Could you help me again??
Thank you.
I’m unfortunately not familiar enough with Windows and am not sure how multiple processes communicate with each other. However, what is your use case that you are using 64 different DataLoaders? Is your code working correctly with a single one and multiple workers?