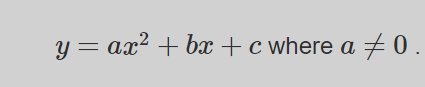I want to write a custom Linear/Quadratic regression function in Pytorch of the form-
def model(x):
pred = x @ W @ x.t() + x @ m + b
return pred
where M is an nxn matrix, m is an nx1 vector, and b is a scalar. The model function maps an n-dimensional vector to a scalar.
In the end, after training I also want to see the values of matrix W, vector m and scalar b.
I tried using the nn.Module to write my own version but wasn’t successful. Any help would be very appreciated in this direction.
Writing a custom model sounds like the right approach.
I assume you’ve taken a look at this or this tutorial? If so, could you describe where you are stuck right now?
First of all, thank you so much for the quick response.
I tried writing this custom module as the solution to my problem
class scr_model(torch.nn.Module):
def __init__(self):
"""
In the constructor we instantiate four parameters and assign them as
member parameters.
"""
super().__init__()
self.W = torch.nn.Parameter(torch.randn((26,26)))
self.m = torch.nn.Parameter(torch.randn((26,1)))
self.b = torch.nn.Parameter(torch.randn((1)))
def forward(self, x):
"""
In the forward function we accept a Tensor of input data and we must return
a Tensor of output data. We can use Modules defined in the constructor as
well as arbitrary operators on Tensors.
"""
return self.b + self.m * x + x *self.W * x.t()
But when i try to test it using
for x,y in train_loader:
preds = model(x)
print("Prediction is :\n",preds.shape)
print("\nActual targets is :\n",y.shape)
break
it shows me that
Prediction is :
torch.Size([26, 26])
In your code you are using the elementwise multiplication instead of the matmul operation from your previous post.
Change this and also the order of self.m and x and the output would have a shape of [1, 1]:
class scr_model(torch.nn.Module):
def __init__(self):
super().__init__()
self.W = torch.nn.Parameter(torch.randn((26,26)))
self.m = torch.nn.Parameter(torch.randn((26,1)))
self.b = torch.nn.Parameter(torch.randn((1)))
def forward(self, x):
return self.b + x @ self.m + x @ self.W @ x.t()
model = scr_model()
x = torch.randn(1, 26)
out = model(x)
print(out.shape)
# torch.Size([1, 1])
Note however that the output shape depends on the batch size which still sounds wrong.
I came back to this problem, that the output shape depends on the batch size, so when I change the batch size to 100, it gives me the warning UserWarning: Using a target size (torch.Size([100, 1])) that is different to the input size (torch.Size([100, 100])). This will likely lead to incorrect results due to broadcasting. Please ensure they have the same size. return F.mse_loss(input, target, reduction=self.reduction)
How to overcome this issue?
I don’t know how you would like to solve this issue as this operation:
x @ self.W @ x.t()
creates an output in the shape [batch_size, batch_size] as already mentioned.
Could you explain what this operation is supposed to do and how you are interpreting it?
I want to do a simple Quadratic regression model, given by the equation in the image.
Now to do this, the first term is given by x @ self.W @ x.t(), as square becomes transpose here. Similarly the second term in the equation bx is written as x @ self.m.
Now I want to know the values of W and m such that my input is correctly mapped to my output
Where upper case are matrices and lower case are vectors/scalars.
You could do the above and get effectively a learnable set of quadratic equations.
However, matrix multiplication is an entirely different “ball game”, so to speak. When we have some learnable vector space, it’s more like this (below variables will represent scalars):
Each scalar of the input vector effectively goes through the above when entering a Linear layer. So if you want to try some quadratic version of that, in addition to the standard linear layer, you might try:
Hey Johnson! Thank you again for the reply mate. The problem is that I want W to be a matrix, there is a reason why I am doing x.T @W x, and that is that at the end of training I want to extract this W matrix, so I cannot initiate W to be a vector of size (25,1).
It would be a matrix if your output size was larger than 1. But if you have an output size of 1, then it would need to be a vector, or you will get a size larger than 1.
Alternatively, you could just sum across dim=1, i.e. (x.T @W x).sum(dim=1), but just note that approach cross-contaminates batchwise inputs; vs. parallelized operations. Not sure if that’s what you’re going for.
When W is a matrix of dimension (25,25). and x is a vector of dimension (1,25). Then x@W is a vector of dimension (1,25). However, when we then do x@W@x.T then we get a scalar because dimension x.T is (25,1). and thus the end result has dimension 1, or a scalar
If I understand you correctly, you want your formulation return self.b + self.m * x + x *self.W * x.t() to work EXACTLY the same as it does for a batch size of 1, but with a batch size of > 1. Am I missing anything?
If that’s the case:
import torch
import torch.nn as nn
torch.manual_seed(0)
class scr_model(torch.nn.Module):
def __init__(self):
super().__init__()
self.W = torch.nn.Parameter(torch.randn((26,26)))
self.m = torch.nn.Parameter(torch.randn((26,1)))
self.b = torch.nn.Parameter(torch.randn((1)))
def forward(self, x):
return self.b + x @ self.m + x @ self.W @ x.t()
class scr_model2(torch.nn.Module):
def __init__(self):
super().__init__()
self.W = torch.nn.Parameter(torch.randn((26,26)))
self.m = torch.nn.Parameter(torch.randn((26,1)))
self.b = torch.nn.Parameter(torch.randn((1,1)))
def forward(self, x):
return self.b + x @ self.m + ((x@self.W)*x).sum(1).unsqueeze(1)
model1=scr_model()
model2=scr_model2()
with torch.no_grad():
model2.W.data=model1.W.data
model2.m.data=model1.m.data
model2.b.data=model1.b.data
x=torch.arange(26).view(1,-1)
w=torch.arange(26*3).view(3,-1)
x=model1(x.float())
w=model2(w.float())
print(x, w)
print(torch.equal(x, w[0:1,:]))