I am quite new to PyTorch and the community, so please bear with me on this.
I want to have a neural network propose rewards for the states in a reinforcement learning task. After running my RL algorithm using these proposed rewards, I expect to have an estimated policy.
I want the loss of the network to be the distance between the estimated policy and the actual policy, which I already have. (The objective here is to learn the rewards, not the policy.)
I implemented my algorithm using numpy but now I’m trying to incorporate PyTorch and it looks desperate. Feeding states to obtain reward propositions was pretty straightforward, I did a simple forward pass. But upon receiving the rewards, I had to use detach() to get these values to calculate the loss and now, I cannot backpropagate since I have broken the computation graph when I use detach(). This is my problem.
Now, I only see two possibilities: 1) move everything to pytorch and abandon numpy 2) try to come up with a hybrid solution.
My questions are:
Is option 2 doable using PyTorch?
If so, what do I need to do to have the gradients calculated automatically?
And if not, is option 1 doable using PyTorch? Do I have to move all my code to PyTorch?
If you move your loss function from pytorch to numpy (and use
differentiable pytorch tensor functions to calculate your loss),
pytorch’s autograd will calculate the gradients for you when you
run loss.backward(). (You don’t have to move everything
to pytorch, but you do have to move the entire loss function to
pytorch.)
If by “hybrid” you mean that you want to keep your loss function
in numpy, then you will have to write an explicit backward()
function (that can be in numpy, if you choose) for your loss
function that calculates its gradients. Once you use something
other than pytorch tensor functions, you won’t be able to get
the gradients / backward() done automatically for you.
When using a custom loss function, I’ve generally preferred to
try to implement it with tensor functions to get autograd “for free.”
Plus you will get pytorch’s cpu / gpu management, and possibly
useful speed-ups from running both your loss function’s forward() and backward() on the gpu, if you so choose.
I do believe that you will have to pay one way or another: Either
port your numpy loss to pytorch; or write backward() explicitly.
Hello again. First of all, thank you for the contribution @KFrank.
I didn’t reply @KFrank 's answer immediately since I knew that it would take me some time to implement all of that. I think I have finished the code and guess what? It is not working I do understand the reason but I don’t know the solution. So here I am once more.
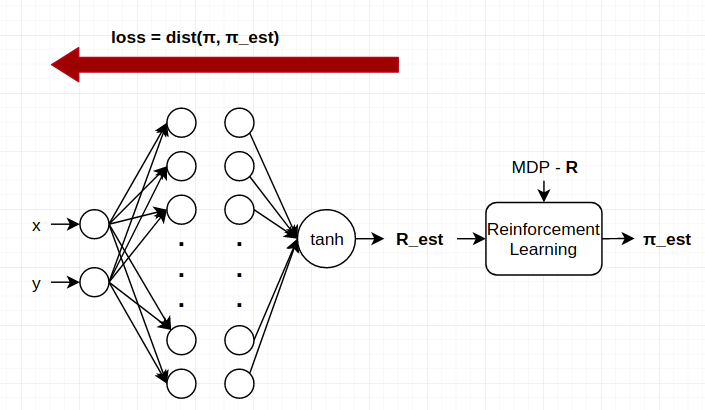
This time I’m gonna use a drawing which I hope will explain the condition far more easily. I’m trying to do Inverse RL:
I don’t have the actual rewards(R). That’s why, I cannot simply use mse_loss(R, R_est). I calculate the distance between π and π_est somehow and want to use this value as the error signal for the backpropagation.
I believe the following 2 lines sum up my issue:
loss = torch.nn.functional.mse_loss(emp_fc, esvc)
loss.backward()
I get this error: RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation: [torch.DoubleTensor []], which is output 0 of SelectBackward, is at version 200; expected version 199 instead. Hint: the backtrace further above shows the operation that failed to compute its gradient. The variable in question was changed in there or anywhere later. Good luck!
Can anybody help me solve this problem? I don’t know how can I avoid in-place operations while I have soooo many of them. Nevertheless, I have to backpropagate that value.
Hi, I have a similar problem, can you indicate if you got the solution or link to where the solution can be inspired?
thanks for the help.
regards, Mayank