When i tried to reimplement MSELoss proposed here Loss Pytroch Implementation with a real example, it gives RuntimeError: derivative for argmax is not implemented although i take argmax with nn.MSELoss and worked.
Code def my_MSELoss(predict, true):
return ((predict - true)**2).mean()
for epoch in range(5):
losses = 0.0
for data, label in train_loader:
network.zero_grad()
predict = network(data.unsqueeze(1).float())
print(predict.shape)
#predict = predict.argmax(axis = 1)
loss = my_MSELoss(predict.argmax(axis = 1), label.float())
print(loss)
loss.backward()
optimizer.step()
loss = loss.item()
losses += loss
print(“For epoch: {}, losses are: {}”.format(epoch + 1, losses))
Which PyTorch version are you using? If I remember correctly, this bug was recently fixed by @albanD in this PR and I get an error using your my_MSELoss function as:
RuntimeError: derivative for argmax is not implemented
I’m Sorry, but i don’t know how to A dd argmin , argmax and argsort to the list of non-differentiable functions
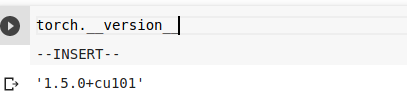
For torch version it’s 1.5 running on Google Colab
The idea is that none of your methods should work, as the derivative of argmax is not implemented.
It seems to be a bug that one of your approaches seems to have worked.
When i tried using max() it throw another error
Code is:
def my_MSELoss(predict, true):
return ((predict - true)**2).mean()
for epoch in range(5):
losses = 0.0
for data, label in train_loader:
#.float() to convert data into weights type
#you can know type of weights through:
#next(model.conv1.parameters()).dtype
network.zero_grad()
predict = network(data.unsqueeze(1).float())
print(predict.shape)
#predict = predict.argmax(axis = 1)
_, y_preds = predict.max(axis = 1)
print(y_preds.shape)
loss = my_MSELoss(y_preds, label.float())
print(loss)
loss.backward()
optimizer.step()
loss = loss.item()
losses += loss
print("For epoch: {}, losses are: {}".format(epoch + 1, losses))
Output is:
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
y_preds is still the argmax. You could get the gradients for the first output (which is the max value).
In that case max would be differentiable and the gradients would just flow back to the maximum value while all other values will get a 0 gradient.
Argmax on the other hand is not differentiable as it return integer values. So you can’t get gradients for it.
1 Like