@ptrblck thanks for your message.
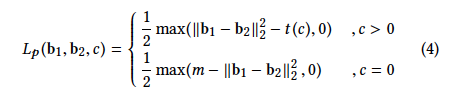
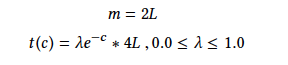
These are details about that loss function.
c: number of common labels between binary pairs
l: hash length
I use ReLu in the model because I want to produce only 0 and 1 from the network. That’s a hashing model so it should produce only binary results. That’s why sign and Relu have been used. Is it not an acceptable way?
Max function in loss function can not be differentiated in some cases as mentioned in
That’s why I changed the max function with ReLu in loss function but it still causes the same problem.
I added these two lines to existed approach to see weight updates
loss.backward()
optimizer.step()
s = torch.sum(model.FC.weight.data)
print(s)
And it returns:
Epoch 0:
tensor(8.6537, device=‘cuda:0’)
tensor(8.6536, device=‘cuda:0’)
tensor(8.6535, device=‘cuda:0’)
Epoch 1:
Tensor(8.6534, device=‘cuda:0’)
tensor(8.6532, device=‘cuda:0’)
tensor(8.6531, device=‘cuda:0’)
Epoch 2:
tensor(8.6529, device=‘cuda:0’)
tensor(8.6527, device=‘cuda:0’)
tensor(8.6525, device=‘cuda:0’)
Does it mean loss function update weights correctly? But loss value is still not decreasing.