Before I start, I just want you to know that I’ve read all the previous threads regarding this but still my problem persists. So, I’ve implemented a custom loss function that looks like this:
def Cosine(output, target):
'''
Custom loss function with 2 losses:
- loss_1: penalizes the area out of the unit circle
- loss_2: 0 if output = target
Inputs
output: predicted phases
target: true phases
'''
# Penalize if output is out of the unit circle
squares = output ** 2 # (x ^ 2, y ^ 2)
loss_1 = ((squares[:, ::2] + squares[:, 1::2]) - 1) ** 2 # (x ^ 2 + y ^ 2 - 1) ** 2
# Compute the second loss, 1 - cos
loss_2 = 1. - torch.cos(torch.atan2(output[:, 1::2], output[:, ::2]) - target)
return torch.mean(loss_1 + loss_2)
I’ve tried the following to debug my model:
for epoch in range(self.num_epochs):
# Train
network.train() # keep grads
print('\nEpoch {}'.format(epoch+1))
print('\nTrain:\n')
a = list(network.parameters())[0].clone()
for batch_idx, (images, labels) in enumerate(Bar(loaders['train'])):
images, labels = images.to(self.device, dtype=torch.float), labels.to(self.device, dtype=torch.float) # labels is a tensor of (512, 128) values if we use MyVgg
optimizer.zero_grad()
preds = network(images)
loss = self.criterion(preds, labels)
loss.backward()
optimizer.step()
b = list(network.parameters())[0].clone()
print(torch.equal(a.data, b.data)) # This prints always true
# Validation
print('\nValid:\n')
network.eval() # skips dropout and batch_norm
with torch.no_grad():
for batch_idx, (images, labels) in enumerate(Bar(loaders['valid'])):
images, labels = images.to(self.device, dtype=torch.float), labels.to(self.device,
dtype=torch.float)
preds = network(images)
loss = self.criterion(preds, labels)
if self.lr_scheduler:
scheduler.step(loss) # update lr_scheduler
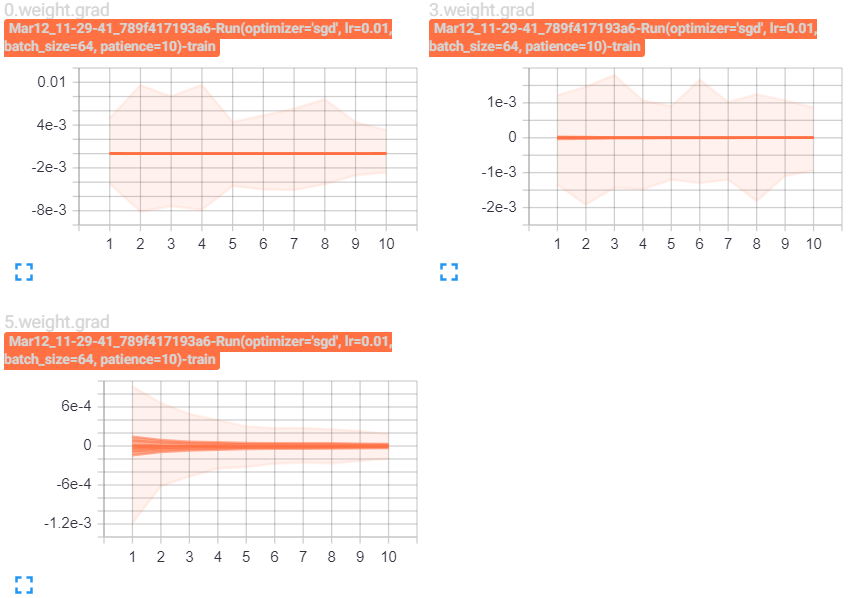
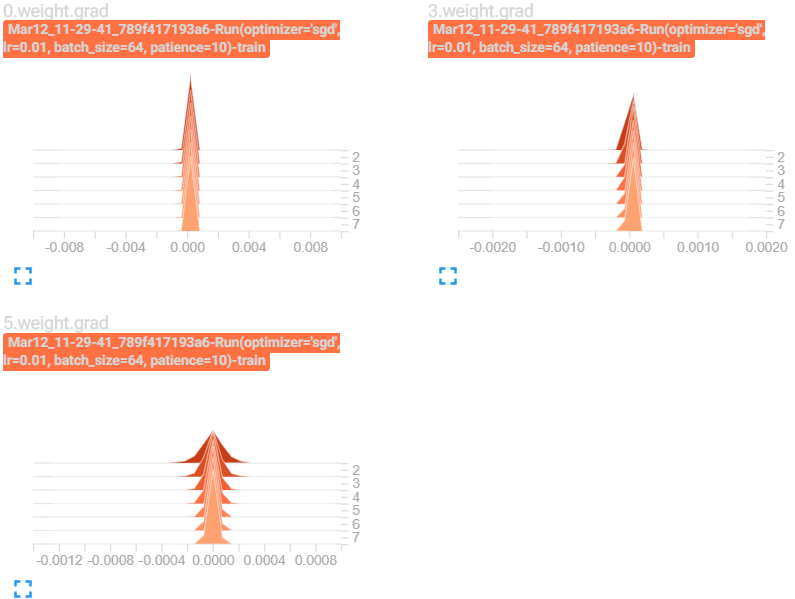
Wherever I try to print list(self.network.parameters())[0].grad is None) I always get True. Also, model.parameters() are always the same and don’t change. Model prediction, true labels, loss functions are all as I expected, but the backprop doesn’t seem to work.
Printing the loss gives me this:
tensor(1.0463, device='cuda:0', grad_fn=<MeanBackward0>)