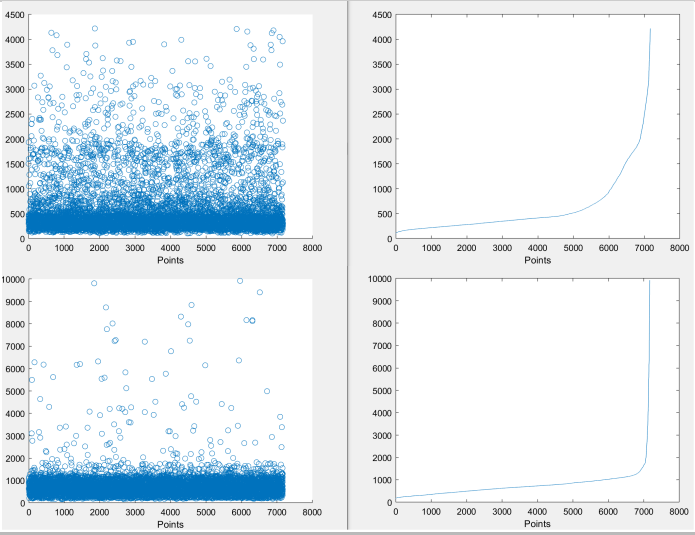
I am working on a regression problem, where I want to modify the loss function so that to address a set of data which has outliers with high importance. This characteristic can be seen in the following images of two sample cases (on the left the raw values and on the right the sorted ones):
So as you can see, usually the majority of the values are within a specific lower range and then I have a couple ones with a much higher intensity.
I’ve tried quite a few different common losses, e.g. MAE, MSE, RMSE, normal/reverse Huber loss which are failing to model the high range values since as I guess they consider them as outliers. Thus, I’ve tried to create a custom loss where for the low error it uses MAE and for the higher error MSE (which is know to be sensitive to outliers):
However, this one still did not help much. More or less in all cases I am getting a poor prediction at the high range values (a bit better with MSE).
Thus I would like to ask whether someone has any idea how I could modify my loss so that it can address these high range values without considering them as outliers.
@ptrblck Thanks for the response. Some questions just to clarify, I will have to apply the clustering to my whole training dataset (I guess I do not need to do that for the testing dataset) or only to each corresponding batch size points each time?
For creating the clusters and getting the weights for each cluster the procedure is kind of straight forward:
import torch
import numpy as np
from kmeans_pytorch import kmeans
data_size, dims, num_clusters = 7000, 1, 10 # this is for one sample (set of values/points to be regressed) with 7000 points, my batch size can vary from 4-12 samples while my whole training dataset is 400 samples
x = np.random.randn(data_size, dims)
x = torch.from_numpy(x)
cluster_ids_x, cluster_centers = kmeans(X=x, num_clusters=num_clusters, distance=‘euclidean’, device=torch.device(‘cuda:0’))
classes, class_counts = np.unique(cluster_ids_x, return_counts=True)
weight = 1. / class_counts
Now do I need to assign these weights to each value separately or what? I do not understand that part, and also when you say:
“After creating the weights, you could write a function, which accepts the current output batch with the regression prediction, as well as your cluster centers (k-means dict), and returns a batch of weights, which can then be multiplied to create the final loss.”
This is gonna be in my “CustomLoss()” function, right?
I would perform the clustering on the training dataset to reuse the same cluster indices for the input samples. If you use it on the batch-level the clusters would “move around”.
You wouldn’t need it for the test set, as the weighting should be only applied during training, if I understand the use case correctly.
Yes, now you would need to map the contiguous input features to each cluster and select the corresponding weight for this input feature. This weight can then be multiplied with the unreduced loss before calculating the gradients.
Ok, after extracting and applying the weights on the values, I used a fair enough number of 50 clusters over my training dataset values, what I am noticing is that now my regressed values are generally overestimated:
I think your issue is specific to MLP regression via mini-batch gradient descent - I wouldn’t expect this bias from GLM/robust regression methods, esp. if training data is homoscedastic.
So, you have a hidden layer that is prone to “forget” outliers due to mini-batching, plus MLPs are biased to output values in region around zero (in fact, outputs like 10000 may even be unreachable with vanilla SGD and low learning rate). Taken together, these things may explain the underfitting in your plots.
I see, your thinking is actually quite interesting. So as I understand you believe that the loss is not that a problem but rather the network architecture.
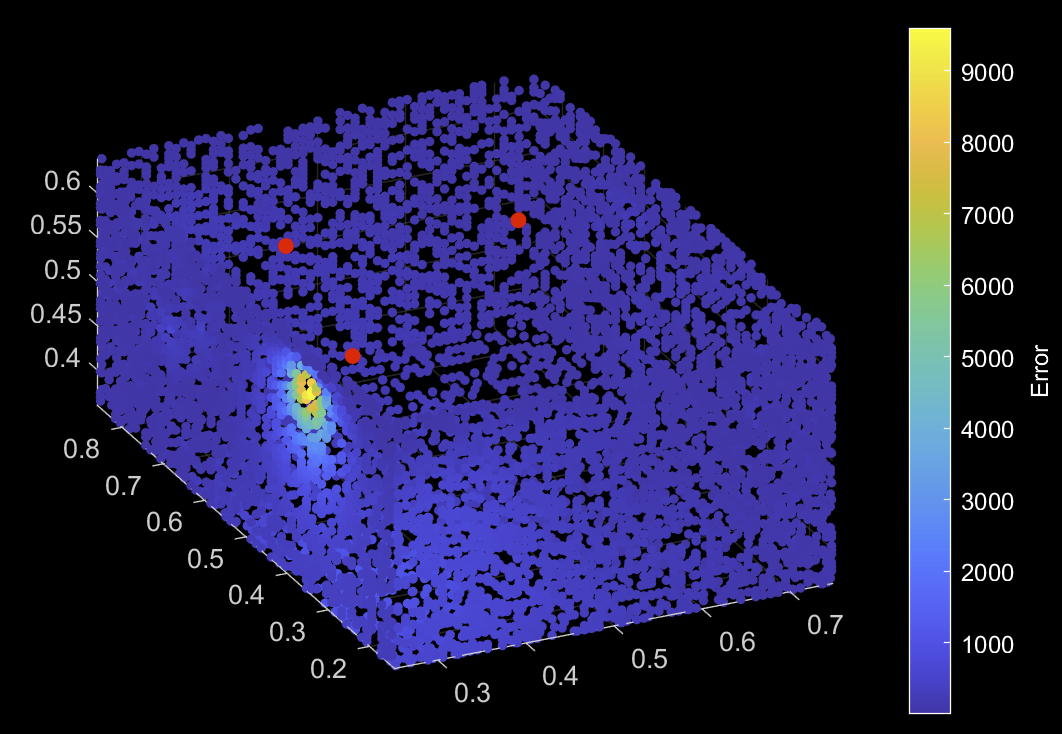
Actually to give some more details regarding the architecture that I am using I am working on 3D deep analysis and point clouds. Imagine that each value that you see on the graph corresponds to an intensity value for each point in the 3D space, and these intensity values are what I am trying to regress. For example check on the image below:
The red points are emitting elements and then I am trying to regress the effect of this emission to each point in the space respectively. As you can see the higher error is in the points closer to the emitting elements due to the smaller distance.
Currently the model that I am using is the RSConv implementation from torch-points3d with a “unet” architecture and the corresponding config file. The model initially is used for segmentation but I am trying to use it for regression. It indeed includes some MLPs and my batch size is quite relatively small imagine that for 400 point clouds my batch-size each time is 12 (maximum point clouds I can load in my gpu with the current size of 7000 points for each point cloud). Trying to downsample my point clouds and increase the batch size could help though.
Scaling/normalizing my values in the range 0-1 (initially my values can vary from 0-46000) is something I’ve tried but it doesn’t seem to work. At the end in the normalization the discripancy gap remains, so for example values that were before in the range of 0-1000 will go to the range 0-0.02 with the majority being in the 3 digits precision i.e. 0.00x so I am not sure whether this could help.
Huber loss or some similar step balancing method may still be necessary, but yea, I said “MLP” but meant deep networks in general; and more complex architectures are more prone to introduce bias.
Note that you can do gradient accumulation (i.e. do backward() without optimizer.step()), to increase effective batch size. Scheduled increasing may be optimal for faster convergence.
Scaling is not ideal here, as you’re using symmetric losses with positive only values, good thing about it is that it makes optimization paths shorter. So, log transform is the simplest correcting (and variance stabilizing) transformation for positive values, not necessarily the best one though…
I was also trying the reverse huber loss (go to the loss function section) which seems to perform quite nicely so far, except of course the high range values.
That’s actually a good point
I didn’t understand that part clearly, where and when I should apply this transformation. You also suggested it in one of your previous messages. Should I apply this before I get the error between my targets and the regressed values in my loss function or elsewhere
Yes, you change targets, so that their distribution is more similar to uniform. Actually, uniformity is also one of the reasons to use per-cluster regression for inhomogeneous targets (like you tried above IIUC)
Actually just for clarification, if I understand it correctly the use of weights is still reasonable to use after the transformation, right. I mean, in my loss function I first apply the log (or any other uniformity) transform to my target values, then I subtract them from the regressed ones and then I apply the weights, am I grasping it correctly?
let’s say weights are as good as before , as I’m not sure how such weights affect local bias with deep networks…
note that target tranformation has the same effect as adding an inverse transformation as activation function after the output layer - i.e. exp() and other smooth monotonic functions with positive outputs.
basically, you’re modulating gradient magnitudes per sample; custom loss, weights and transformations are just different (possibly complementary) methods for that.
Ok, after playing a bit with almost all the proposals (weights, transformations e.g. log and scaling (dividing by a value), gradient accumulation of mini-batches) for modulating the gradient magnitudes per sample I am still facing more or less the same behavior, still the network cannot handle this discrepancy to the high range values.
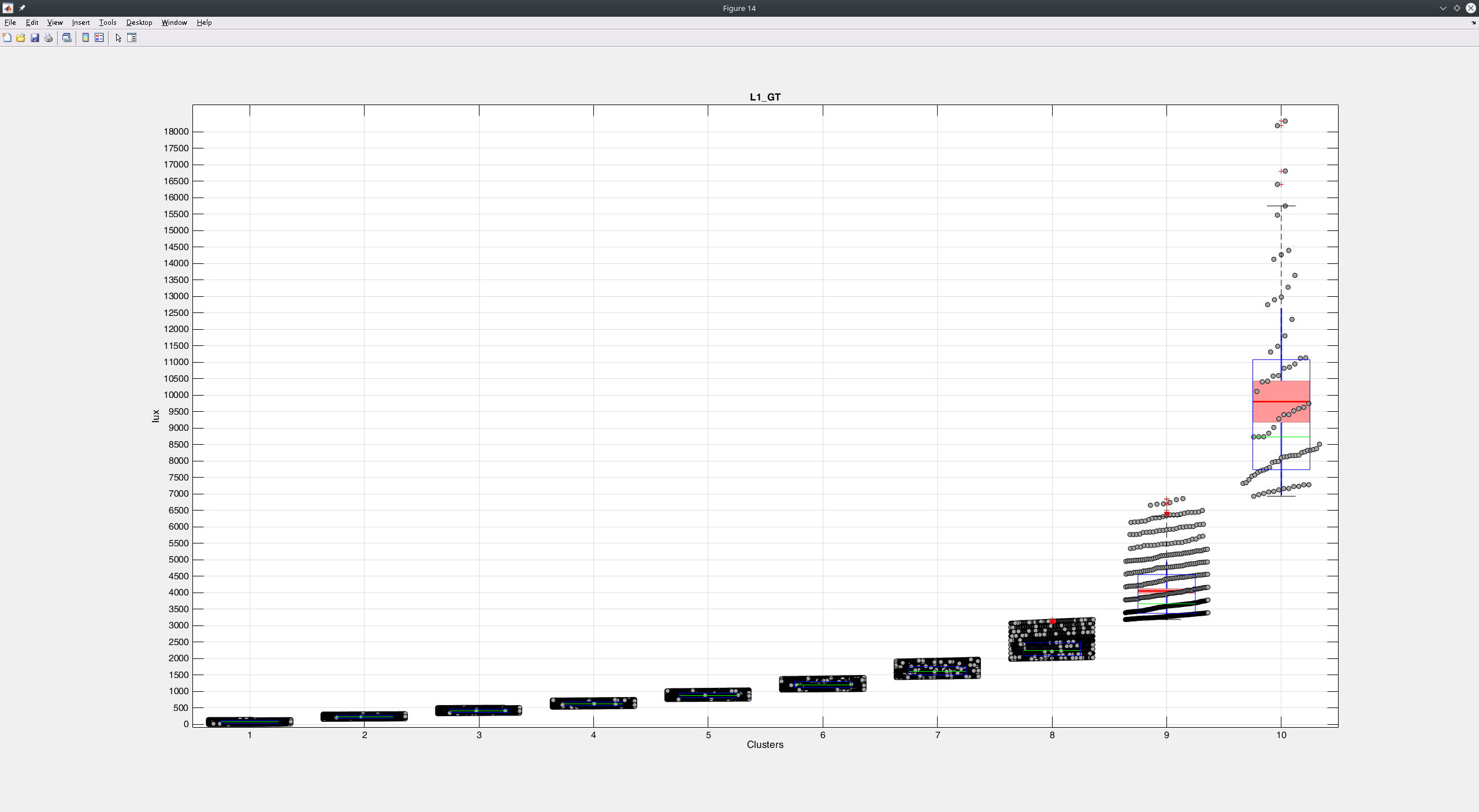
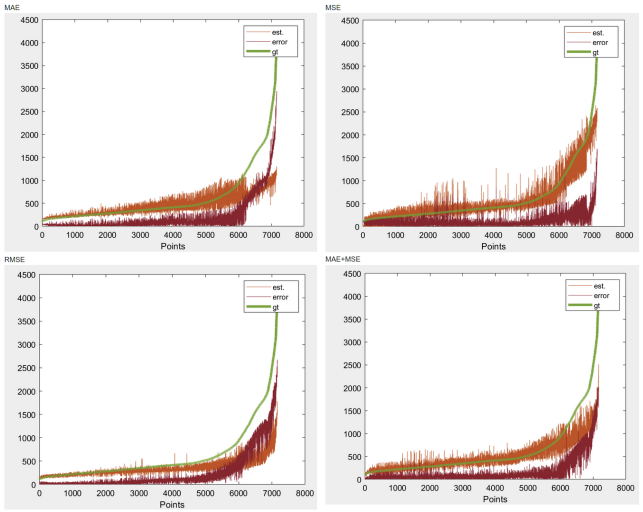
I’ve tried to make a better visualization of the problem. I’ve split my data in 10 clusters, and this is how my whole testing dataset looks like:
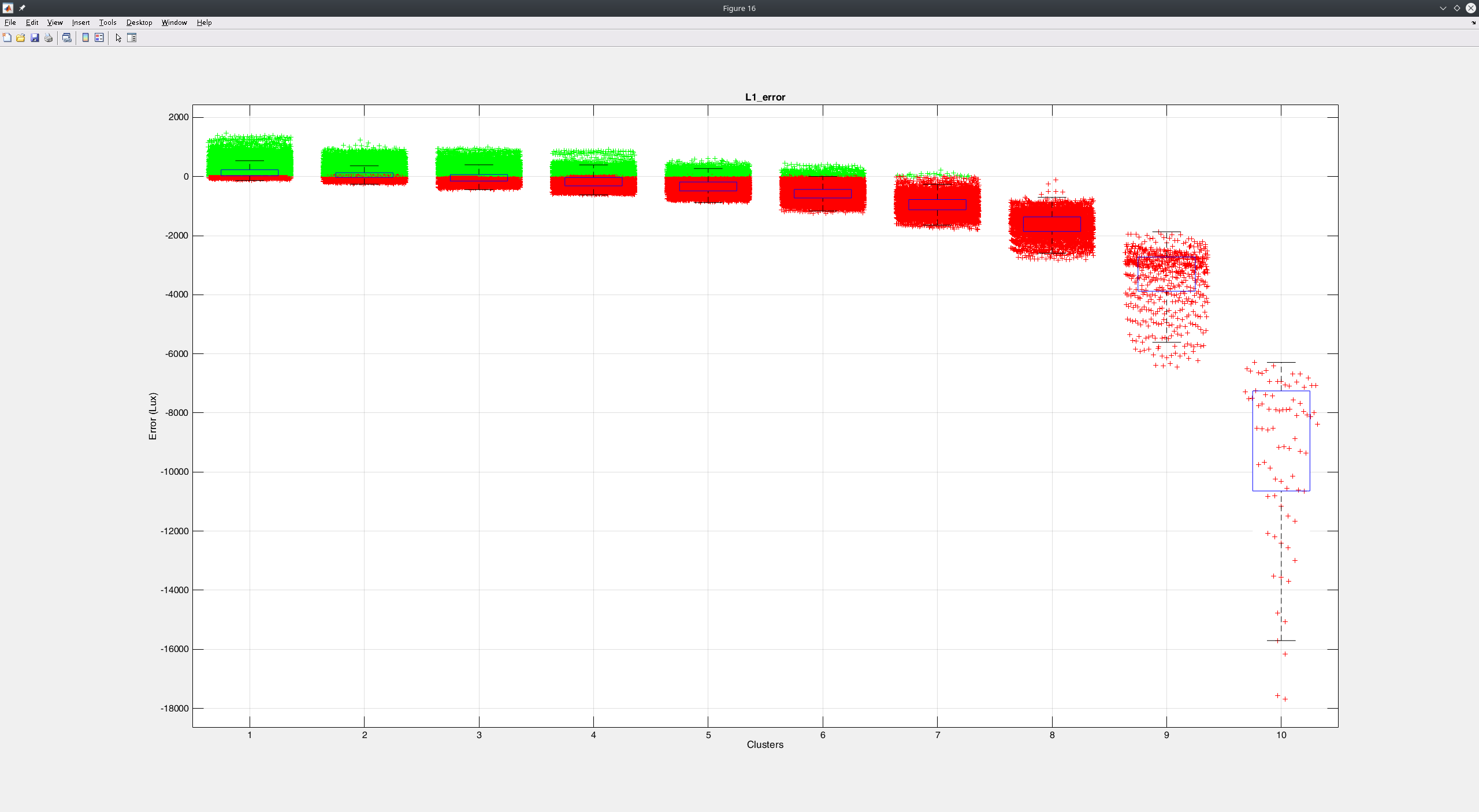
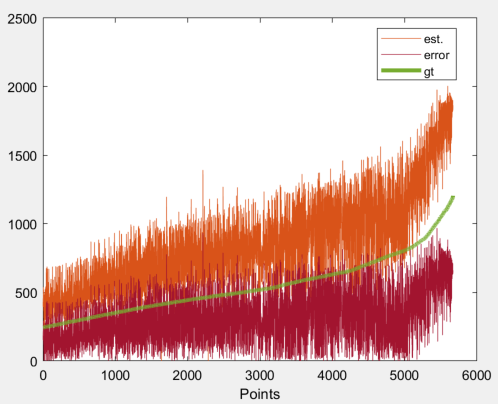
end especially on the last cluster the values are underestimated, something that can be seen clearer in the following graph (green=overestimation, red=underestimation):
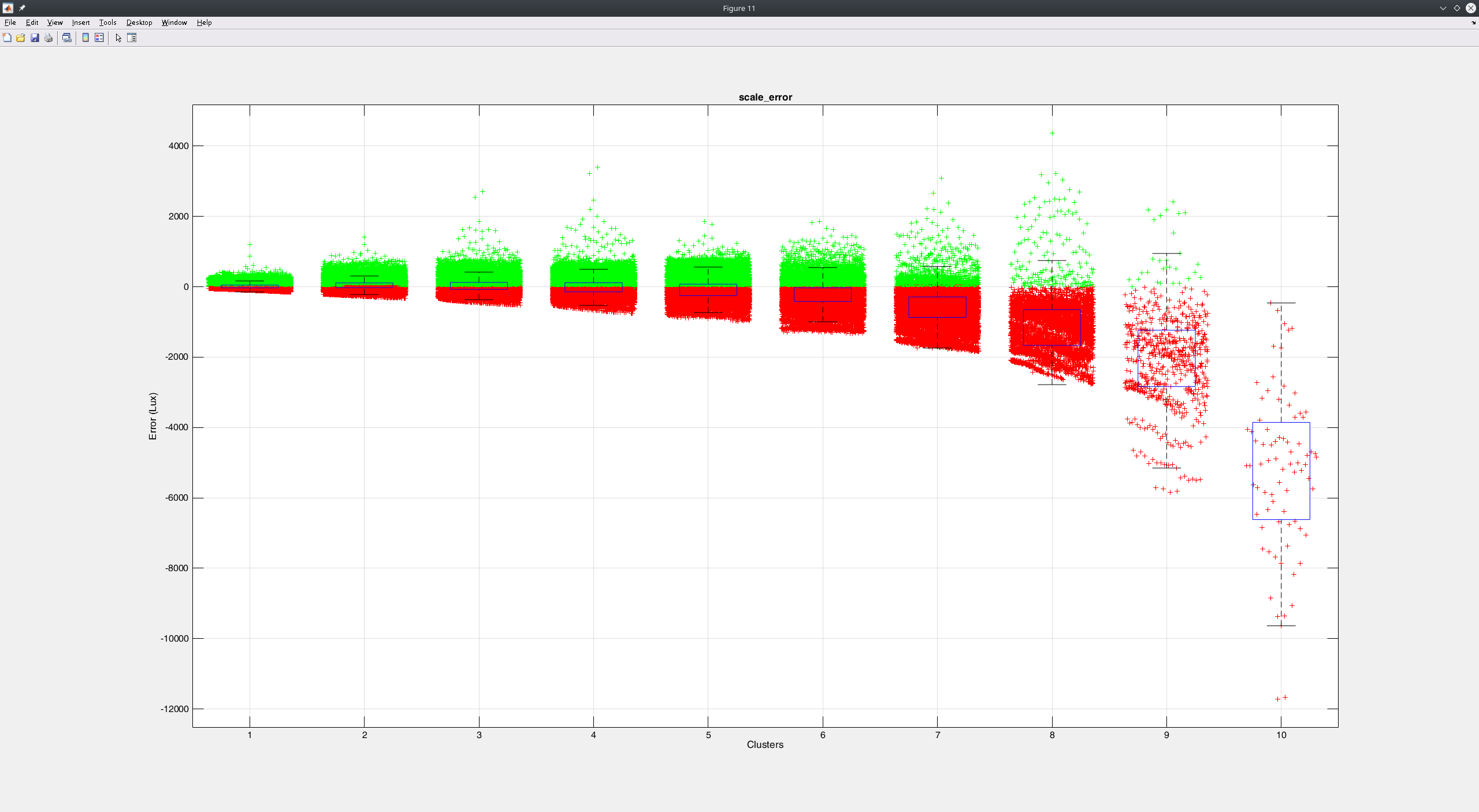
Scaling (dividing targets by 100) seems to work a bit better but still output values are underestimated especially in the last clusters with the high range values:
You should understand that with L1 loss (and non-quadaratic loss zones in general) you’re doing gradient descent based on error sign only, this may converge with help from lr scheduler and/or adaptive optimizer, but it is intrinsically harder, and big (compared to LR) initial errors may be uncorrectable w/o downscaling.
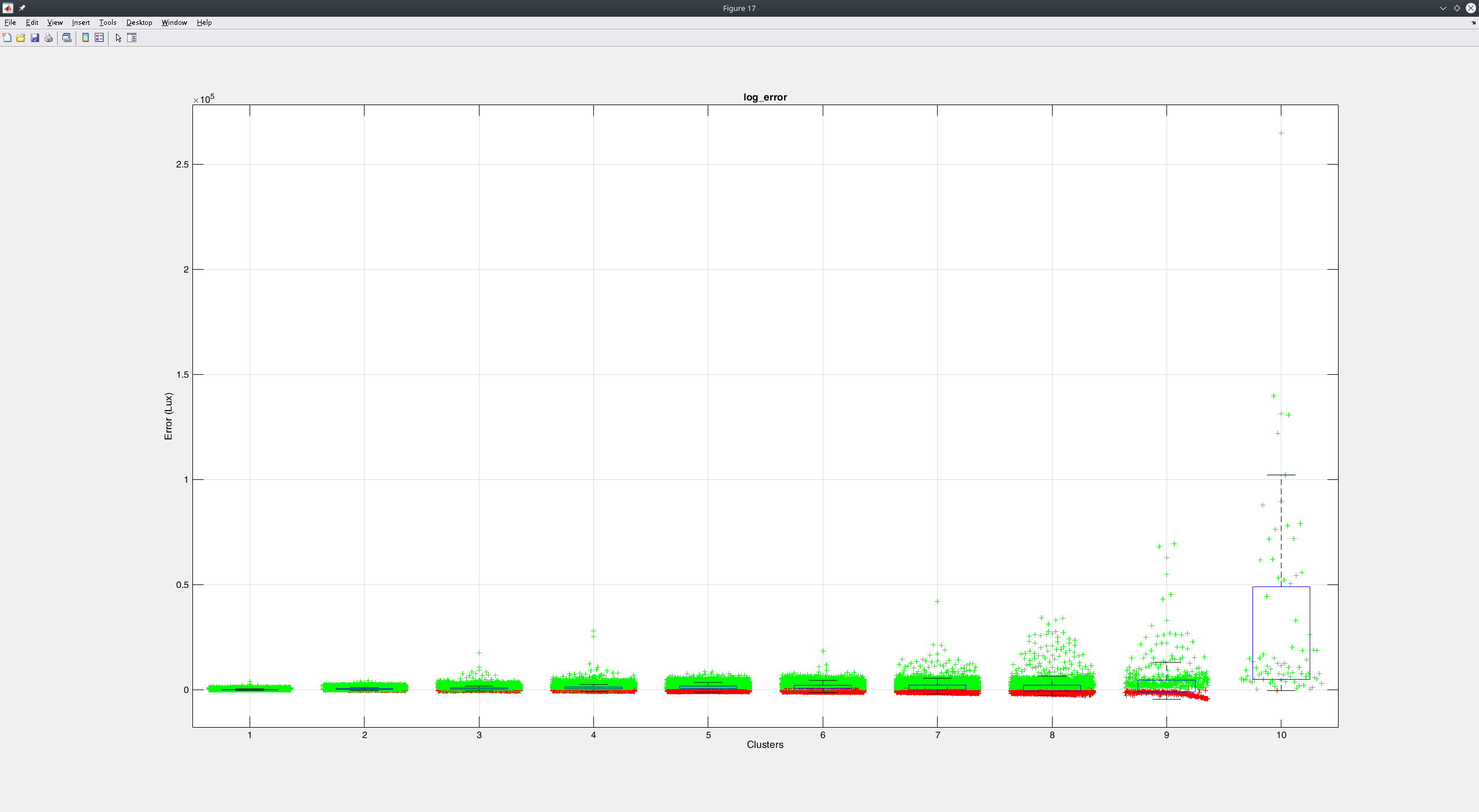
Interesting log-transform results… I’d guess that your optimizer’s steps are too big, if you end up with 10^5 errors. This stuff with clusters may actually be bad, as gradients are scaled ~100-1000 times for your last clusters; this can mess up shared parameters and gradient variance estimates too much. Other possibilities include inappropriate LR & scheduler params or non-quadratic loss issues I’ve mentioned.
Ok, got that. So downscaling my values is necessary ;-).
You’ve guessed right that my optimizer steps were big, lowering it though improved the output but not good enough. So far scaling by a factor of 100 seems to perform better than everything else, though not good enough as well.
The main issue, is that my dataset is heavily imbalanced. For example if you consider that almost 90% or more of the values are laying within the range of 0-2000. It is normal that the network will learn to predict this range of values and would consider the rest in a less meaningful way. Weighting though I am not sure yet why it didn’t help, since in principle it should improve.
Another idea that came to my mind is whether it would be better (or it is possible) if I create a separate loss output for each cluster and then either combine them to an overall loss or somehow have a different regression branch for each cluster in the architecture. But I am not sure whether this would make any difference.
Well, that’s not proper oversampling - if you would show the network an “outlier” 100 times, 100 small gradient steps would have changing directions, instead of big linear jumps.
If you rule out numerous “configuration” issues, this leaves “forgetfulness” and “limited memory” as causes for big final errors (for training set, for validation set you may also experience poor generalization). In that case, architecture tweaks with specific intents may indeed help.
I’d suggest to try attention as a way to have non-shared parameter values and deal with “forgetfulness”.
Another (a bit similar) thing to try would be to train network to output quantiles of some distribution approximating your whole dataset (log-normal perhaps), with non-trainable (0,1)->Y_domain final transform.
 , as I’m not sure how such weights affect local bias with deep networks…
, as I’m not sure how such weights affect local bias with deep networks…