Sorry for the previous (deleted) post, I accidentally created the post before writing (I still don’t know how, but whatever).
- My model:
class Module1(nn.Module):
def __init__(self):
super(Module1, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 5, 1, 2)
self.conv2 = nn.Conv2d(32, 64, 5, 1, 2)
self.conv3 = nn.Conv2d(64, 128, 5, 1, 2)
self.conv4 = nn.Conv2d(128, 128, 5, 1, 2)
self.pool = nn.MaxPool2d(2, 2)
self.fc = nn.Linear(128*8*8, 10)
def forward(self, x):
x = self.pool(F.relu(self.conv2(F.relu(self.conv1(x)))))
x = self.pool(F.relu(self.conv4(F.relu(self.conv3(x)))))
x = x.view(x.size(0), -1)
return x
- My loss:
def infoNCE(zt, ztk):
ind = np.diag_indices(b_size)
aux = torch.exp(ztk @ torch.t(zt))[ind[0], ind[1]]
aux = aux / torch.sum(torch.exp(ztk @ torch.t(zt)), axis=0)
val = -torch.sum(torch.log(aux))
return val
- My code for the training:
mod1 = Module1().to(device)
optimizer = optim.Adam(mod1.parameters(), lr=lr)
for epoch in trange(epochs):
for i, data in enumerate(trainloader):
xt = data[0][0].to(device)
xtk = data[0][1].to(device)
yt = data[1].to(device) # ignore this
optimizer.zero_grad()
zt = mod1(xt)
ztk = mod1(xtk)
loss = infoNCE(zt, ztk)
loss.backward()
optimizer.step()
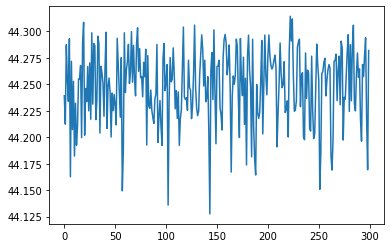
- My loss over time:
Epoch 50 Loss = 44.24047088623047
Epoch 100 Loss = 44.24409484863281
Epoch 150 Loss = 44.193824768066406
Epoch 200 Loss = 44.24012756347656
Epoch 250 Loss = 44.26813507080078
Epoch 300 Loss = 44.28200149536133