Hi,
I am trying to implement a custom loss function called Wing loss. I found it in this paper: https://arxiv.org/pdf/1711.06753.pdf
It is defined on page 5 in formula 5:
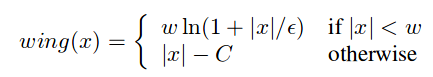
my current code is this:
class WingLoss(nn.Module):
def __init__(self, width=5, curvature=0.5):
super(WingLoss, self).__init__()
self.width = width
self.curvature = curvature
self.C = self.width - self.width * np.log(1 + self.width / self.curvature)
def forward(self, prediction, target):
diff = target - prediction
diff_abs = diff.abs()
loss = diff_abs.clone()
idx_smaller = diff_abs < self.width
idx_bigger = diff_abs >= self.width
loss[idx_smaller] = self.width * torch.log(1 + diff_abs[idx_smaller] / self.curvature)
loss[idx_bigger] = loss[idx_bigger] - self.C
loss = loss.sum()
print(loss)
return loss
The loss develops like this (mini-batch size is 32):
tensor(11278.4453, device=‘cuda:0’, grad_fn=< SumBackward0>)
tensor(2007270.2500, device=‘cuda:0’, grad_fn=< SumBackward0>)
tensor(1.3329e+16, device=‘cuda:0’, grad_fn=< SumBackward0>)
tensor(nan, device=‘cuda:0’, grad_fn=< SumBackward0>)
prediction and target both have the shape BS x N x DM = 32 x 68 x 2
I am using SGD with a learning rate of 0.1, but have also tried 0.01 and other small learning rates. the only difference is the time it takes to get a nan. The script works with other losses and does train successfully, so there must be an issue with my loss function.
I am not sure why this is. Did I implement the formula wrong?
 I came up with this idea because the default reduction for MSELoss and L1Loss also seems to be “mean”. But I don’t really know why I get nan values when I use sum… Does somebody have an idea?
I came up with this idea because the default reduction for MSELoss and L1Loss also seems to be “mean”. But I don’t really know why I get nan values when I use sum… Does somebody have an idea?