Hello am trying to build from scratch as part of a homework, but when ever i try to train i end up with no change in the loss, after further investigation I found it is because the gradient which is always zero:
class LSTMCell(nn.Module):
"""Long short-term memory (LSTM) cell"""
def __init__(self, input_size, hidden_size):
super(LSTMCell, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.weight_ih = nn.Parameter(torch.Tensor(input_size, hidden_size * 4))
self.weight_hh = nn.Parameter(torch.Tensor(hidden_size, hidden_size * 4))
self.bias_ih = nn.Parameter(torch.Tensor(hidden_size * 4))
self.bias_hh = nn.Parameter(torch.Tensor(hidden_size * 4))
self.init_parameters()
def init_parameters(self):
stdv = 1.0 / math.sqrt(self.hidden_size)
for param in self.parameters():
nn.init.uniform_(param, -stdv, stdv)
def forward(self, x, init_states):
h_t_minus_1, c_t_minus_1 = init_states
gates = torch.mm(x, self.weight_ih) + self.bias_ih + torch.mm(h_t_minus_1, self.weight_hh) + self.bias_hh
inputgate, forgetgate, cell, outputgate = gates.chunk(4, dim=1)
c = (torch.sigmoid(forgetgate) * c_t_minus_1) + (torch.sigmoid(inputgate) * torch.tanh(cell))
h = torch.sigmoid(outputgate) * torch.tanh(c)
return (h, c)
class LSTM(nn.Module):
"""Multi-layer long short-term memory (LSTM)"""
def __init__(self, input_size, hidden_size, num_layers=1, batch_first=False):
super(LSTM, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.batch_first = batch_first
self.layers = [LSTMCell(input_size, hidden_size)]
for i in range(num_layers - 1):
layers += [LSTMCell(hidden_size, hidden_size)]
self.net = nn.Sequential(*self.layers)
def forward(self, x, init_states=None):
# Input and output size: (seq_length, batch_size, input_size)
# States size: (num_layers, batch_size, hidden_size)
if self.batch_first:
x = x.transpose(0, 1)
self.h = torch.zeros(x.size(0), self.num_layers, x.size(1), self.hidden_size).to(x.device)
self.c = torch.zeros(x.size(0), self.num_layers, x.size(1), self.hidden_size).to(x.device)
if init_states is not None:
self.h[0], self.c[0] = init_states
inputs = x
for i, cell in enumerate(self.net): # Layers
h_t, c_t = self.h[0, i].clone(), self.c[0, i].clone()
for t in range(x.size(0)): # Sequences
h_t, c_t = cell(inputs[t], (h_t, c_t))
self.h[t, i], self.c[t, i] = h_t, c_t
inputs = self.h[:, i].clone()
if self.batch_first:
return self.h[:, -1].transpose(0, 1), (self.h[-1], self.c[-1])
return self.h[:, -1], (self.h[-1], self.c[-1])
class LSTMModel(nn.Module):
def __init__(self, input_size, hidden_size, num_layers, output_size):
super(LSTMModel, self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = LSTM(input_size, hidden_size, num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, x):
out, _ = self.lstm(x, None)
out = self.fc(out[:, -1, :])
return out
Then:
net = LSTMModel(1457,14,1,2)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.1)
when i try to check the grads, i find:
net.train()
inputs, labels = X[:20].reshape(20,1,1457), y[:20].long()
optimizer.zero_grad()
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(net.lstm.layers[0].weight_ih.grad)
the result is ::
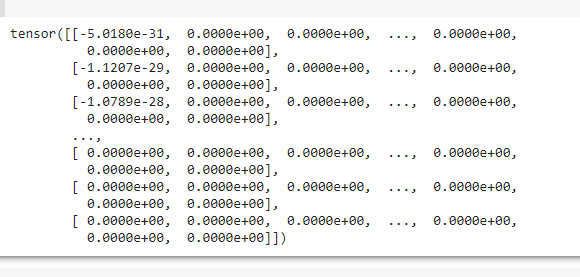
my input is a text, with 1457 token in it,
can u help me asap