Hello all, I am quite new to Pytorch.
I am trying out my custom loss function in a simple single layer Neural network (x = 2, h_1 = 2, output =2). However, during a particular epoch’s iteration my loss function is first outputting “Inf” and "NaN"s in subsequent iterations. My Loss Function has a log, but it basically calculates distance and uses those as arguments for the log parameter. There might be subtle numerical instability. An Inf arises when there is a zero distance between columns. I can fix that by adding a little epsilon inside the log argument (which I didn’t).
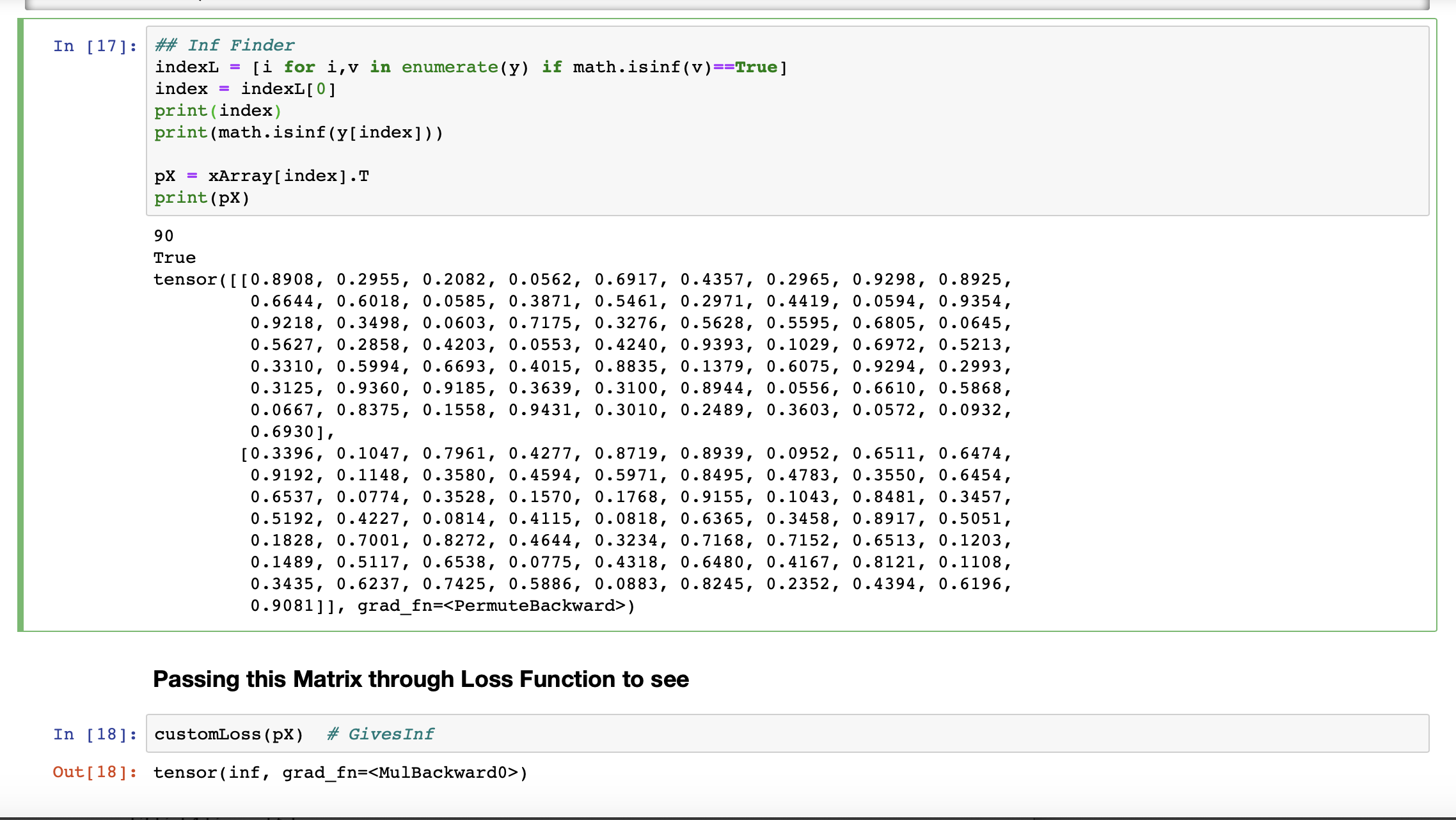
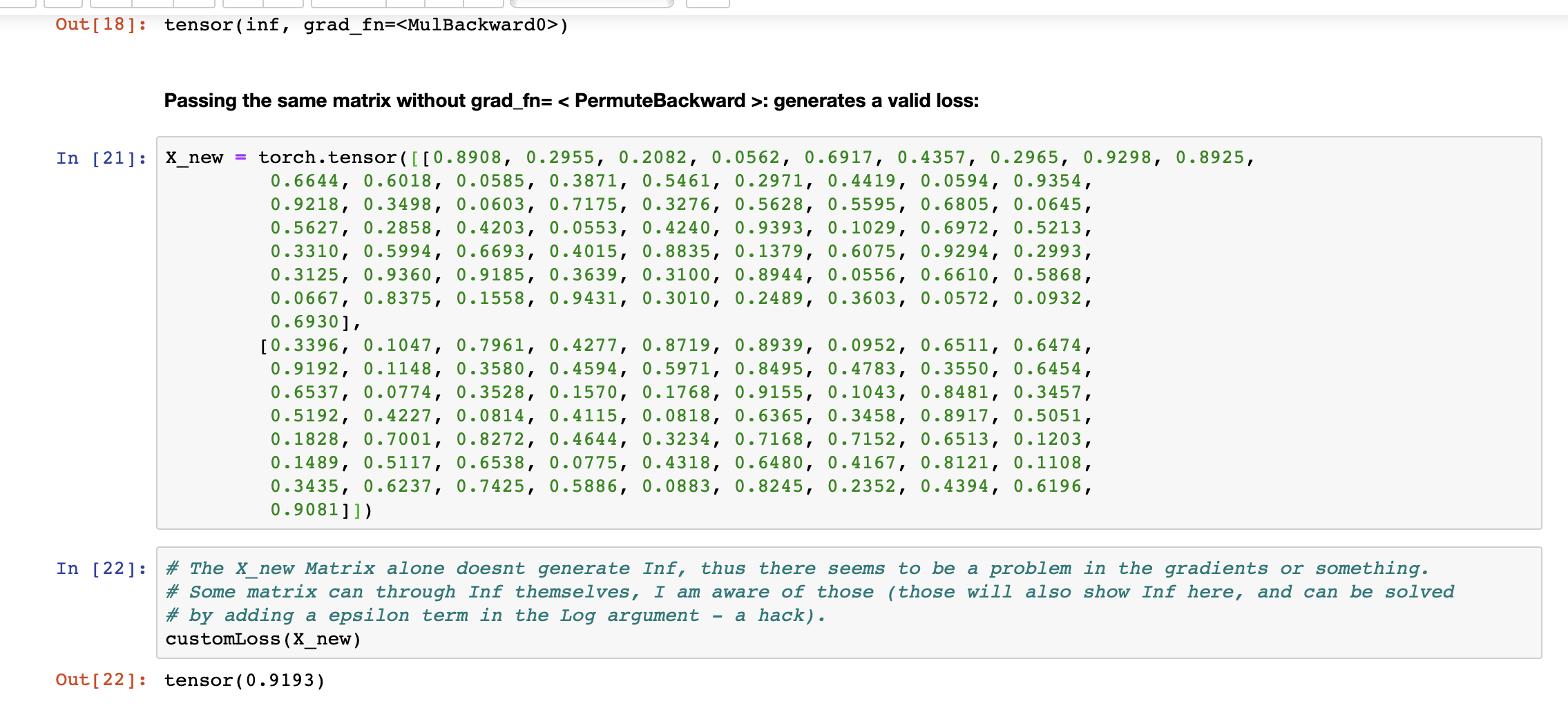
But, what I found the issue at is that, the batch X at one iteration when goes through the loss function, outputs “inf”. But the same matrix if I just copy and pass it through the loss function as a simple torch.tensor(X), then it outputs a value, not an “inf”. I concluded that it must be because of the torch.tensor(X, grad_fn = < permute_backwards> ) the backward gradient might be the reason. I do not know how that works, but without the permute backward generated inside training, the matrix alone doesn’t generate Inf.
I would be glad if someone could take a look. I’ve linked the .ipynb here. iPy NoteBook Link
You might have skipped the problematic batch somehow?
If I add torch.autograd.set_detect_anomaly(True) in cell12:
xArray = []
iter = 0
torch.autograd.set_detect_anomaly(True)
the code will raise an exception, pointing to a detected invalid value. If I run the next cells afterwards manually, I’ll get an Inf for customLoss(X.T).
Thanks for taking the time to go through the notebook. I really appreciate it!
I am still a beginner to Pytorch, could you please elaborate a bit on what you mean, specially regarding the.torch.autograd.set_detect_anomaly(True) ?
Regarding getting the Inf at last cell, please select and copy the numerical values of the tensor from cell-17 output, and paste it inside the cell-21, assigning it to the variable X_new = torch.tensor( paste here ). Afterwards, if I use the Loss function on this copy-pasted variable: X_new in cell 22, I get a valid number as output. But this same, matrix was giving Loss = inf in cell-18 and inside the main training code-block.
If it again gives Inf in the last cell, changing the two random.seed()s at the start only 1 or 2 times will surely generate this scenario.