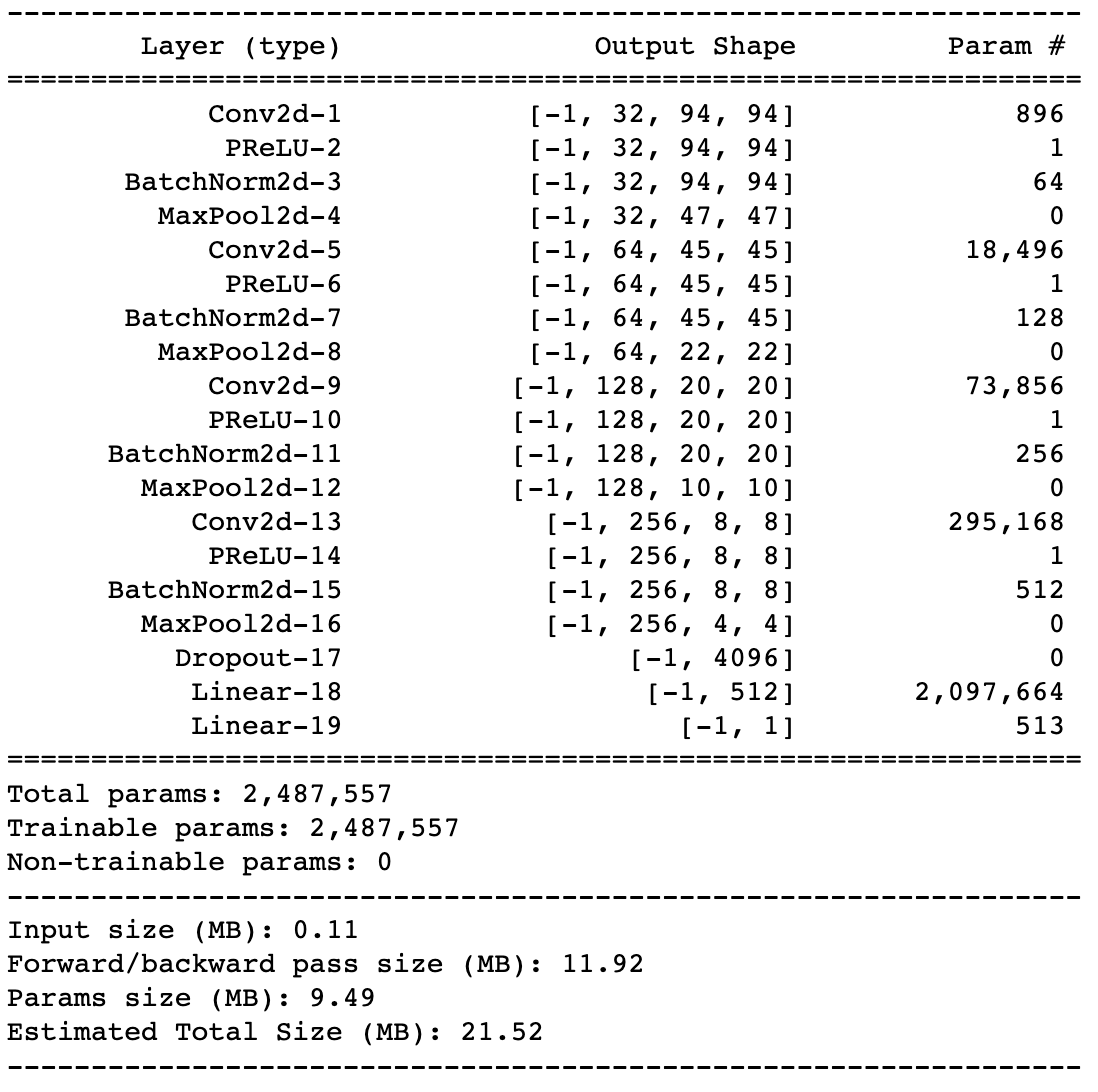
I want to be able, to reuse only a chunk of my model, let’s say inputting at Conv2d-5 and outputting at the last Linear-19, or inputting at BatchNorm2d-11 and outputting at the last layer still Linear-19.
The target is to be able to choose any intermediate layer, and give it a tensor as input w.r.t the layer input dimension, and outputting with the last layer.
I wanted to use nn.ModuleList() and append from mymodel’s layers, but mymodel.state_dict().items() doesn’t print my pooling layers.
I’ve tried also mymodel._modules.keys(), it’s viewing the pooling layer, but not in the order they are called in my Neural Network.
See:
Your solution would have worked indeed, if I always had the code of all the models.
But my purpose targets all saved models, which means I don’t have access to the code, I can only load and save, like all we do with available pre-trained models (resnet18, vgg16, …).
My project is coding TCAV technique, which is compelling me to input from all the intermediate layers, for each of the received models.
I’ve found some code in a github repo, they use the .keys() and .items() attributes from inception pretrained, but as said in my first post, .keys() and .children() don’t know how to output pooling layers, and they don’t get back the right order of the layers (see my first post):
class InceptionV3_cutted(torch.nn.Module):
def __init__(self, inception_v3, bottleneck):
super(InceptionV3_cutted, self).__init__()
names = list(inception_v3._modules.keys())
layers = list(inception_v3.children())
self.layers = torch.nn.ModuleList()
self.layers_names = []
bottleneck_met = False
for name, layer in zip(names, layers):
if name == bottleneck:
bottleneck_met = True
continue # because we already have the output of the bottleneck layer
if not bottleneck_met:
continue
if name == 'AuxLogits':
continue
self.layers.append(layer)
self.layers_names.append(name)
I’m confused by what you mean when you say you don’t have the code of the model, as all pretrained models in torchvision like the ones you named have code as well. Can you share how you’re loading and running the model?
My target is to cut any loaded model, without modifying the initial code. Hence being able to loop over all the layers, respecting their order in the neural network loaded, and input at any intermediate layer chosen for the cut.
If you can only show me how to access all the layers of a loaded model, respecting their order in the network, I’ll be able to copy weights and biases and all the parameters of the loaded model, in the new cut model. Actually, all the layers are printed not in order with .keys() and .named_parameters(), and also .state_dict().items(), so I cannot access the layers in their implemented sequence.
Also, I’ve seen that the source code of torchsummary is able to access the layers in their implemented order. They’re using hooks. I’m trying to figure how this works.
Tell me if I’m still not clear. (I’ve been using PyTorch for only 4 months, sorry for my poor level)