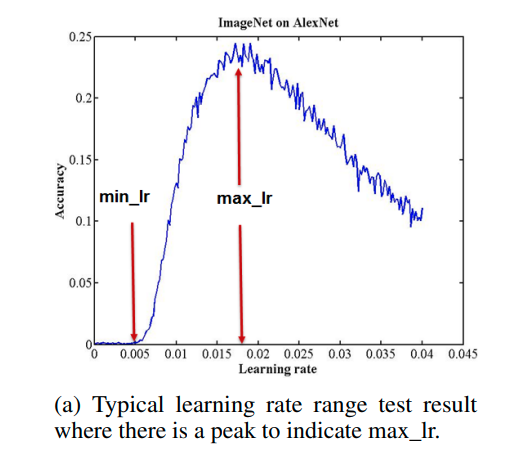
I want to plot a graph for accuracy for base_lr= 0.01 and max_lr=0.1, similar given in attached photo
accuracy = []
for cycle in range(CYCLES):
random.shuffle(unlabeled_set)
subset = unlabeled_set[:SUBSET]
# Model - create new instance for every cycle so that it resets
with torch.cuda.device(CUDA_VISIBLE_DEVICES):
resnet18 = resnet.ResNet18(num_classes=NO_CLASSES).cuda()
models = resnet18
torch.backends.cudnn.benchmark = True
models = torch.nn.DataParallel(models, device_ids=[0])
# Loss, criterion and scheduler (re)initialization
criterion = nn.CrossEntropyLoss(reduction='none')
optim_backbone = optim.SGD(models.parameters(), lr=LR,
momentum=MOMENTUM, weight_decay=WDECAY)
schedulers = torch.optim.lr_scheduler.CyclicLR(optim_backbone, base_lr= 0.01, max_lr=0.1, step_size_up=2000, step_size_down=None, mode='triangular')
optimizers = optim_backbone
#schedulers = sched_backbone
train(models, criterion, optimizers, schedulers, dataloaders, Epochs)
acc = test(models, dataloaders, mode='test')
print('Trial {}/{} || Cycle {}/{} || Label set size {}: Test acc {}'.format(trial+1, TRIALS, cycle+1, CYCLES, len(labeled_set), acc))
#np.array([method, trial+1, TRIALS, cycle+1, CYCLES, len(labeled_set), acc]).tofile(results, sep=" ")
accuracy.append(acc)
#iterations.append(cycle)
if cycle == (CYCLES-1):
# Reached final training cycle
print("Finished.")
break
# Get the indices of the unlabeled samples to train on next cycle
arg = query_samples(models, data_unlabeled, subset, labeled_set, cycle)
# Update the labeled dataset and the unlabeled dataset, respectively
labeled_set += list(torch.tensor(subset)[arg][-ADDENDUM:].numpy())
listd = list(torch.tensor(subset)[arg][:-ADDENDUM].numpy())
unlabeled_set = listd + unlabeled_set[SUBSET:]
# Create a new dataloader for the updated labeled dataset
dataloaders['train'] = DataLoader(data_train, batch_size=BATCH,
sampler=SubsetRandomSampler(labeled_set),
pin_memory=True)