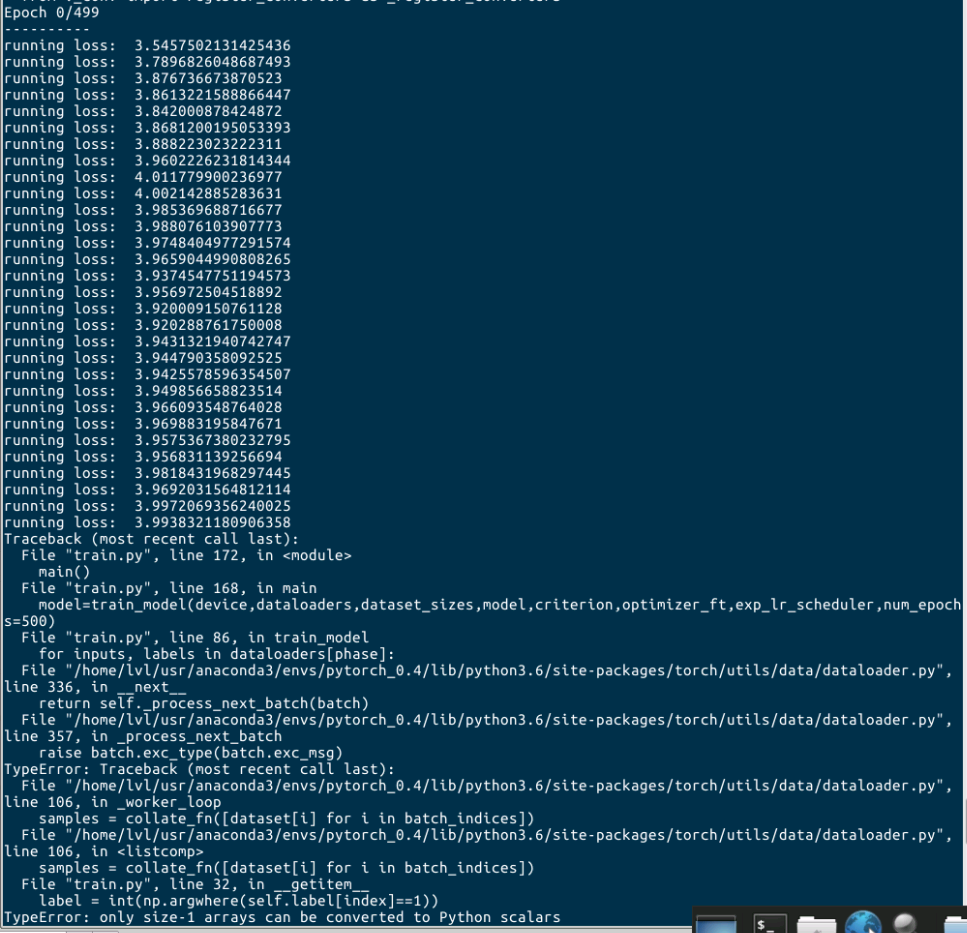
Today, when I was trying to deal with my own dataset with one-hot label, something strange happened. My snippet is like this:
`class LCZDataset(data.Dataset):
def init(self,path):
self.path = path
self.file = h5py.File(self.path)
self.sen1 = self.file[‘sen1’]
self.sen2 = self.file[“sen2”]
self.label = self.file[“label”]
Then, it errors " only size-1 arrays can be converted to Python scalars". I tried to print the self.label[index], and it printed out . However, the label of my dataset is absolutely in one-hot form. Have any one of you meet the same problem? Do you know why? Thank you.
It looks like np.argwhere returns more then one position.
Could you check, that each label is really one-hot encoded?
Probably at some index you have more then a single 1 in your label.
Printing the index and running into the error again might help to locate the problematic label.
My data label is absolutely in one-hot form. I finally find the problem. Before, the num_workers in data.Dataloader was set as 8. Then, I unintentionally changed it to 1, everything became right, label prints norm and training becomes norm. So, could you please tell me what caused my problem? Why num_workers is 1 is all right?
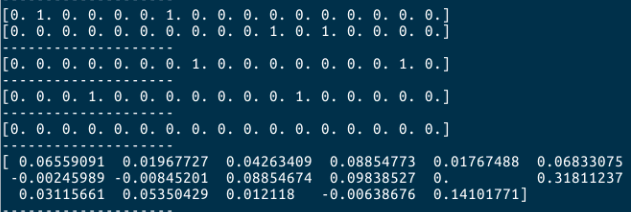 . However, the label of my dataset is absolutely in one-hot form. Have any one of you meet the same problem? Do you know why? Thank you.
. However, the label of my dataset is absolutely in one-hot form. Have any one of you meet the same problem? Do you know why? Thank you.