@jpatrickpark Nice visualization. How did you do it? Thanks!
I just created a simulation involving loaders, queue and a consumer, and visualized each entity at each time step using matplotlib. More details can be found at the end of this post: Visualizing data loaders to diagnose deep learning pipelines | JP
Hello everyone. I read the source code of DataLoader carefully and finnaly find out the reason of the time lag after num_workers batchs. I write it in Zhihu. If you can read Chinese, you can refer to this website. pytorch dataloader 使用batch和 num_works参数的原理是什么? - 知乎
Hi,
I am facing this issue, too. Can you explain what you find out in English? (Unfortunately, I can not speak Chinese)
Hi! Thanks for the discussion. I’m solving the same problem now with the #num_workers time lag pattern. Here I’m running the model on HPC via slurm jobs, and there’s a cap for my number of workers (20), so increasing the number of workers to solve this isn’t an option for me. I wonder if there’s a way to work around different configurations like nodes, cpus-per-task, gres, ntasks-per-node?
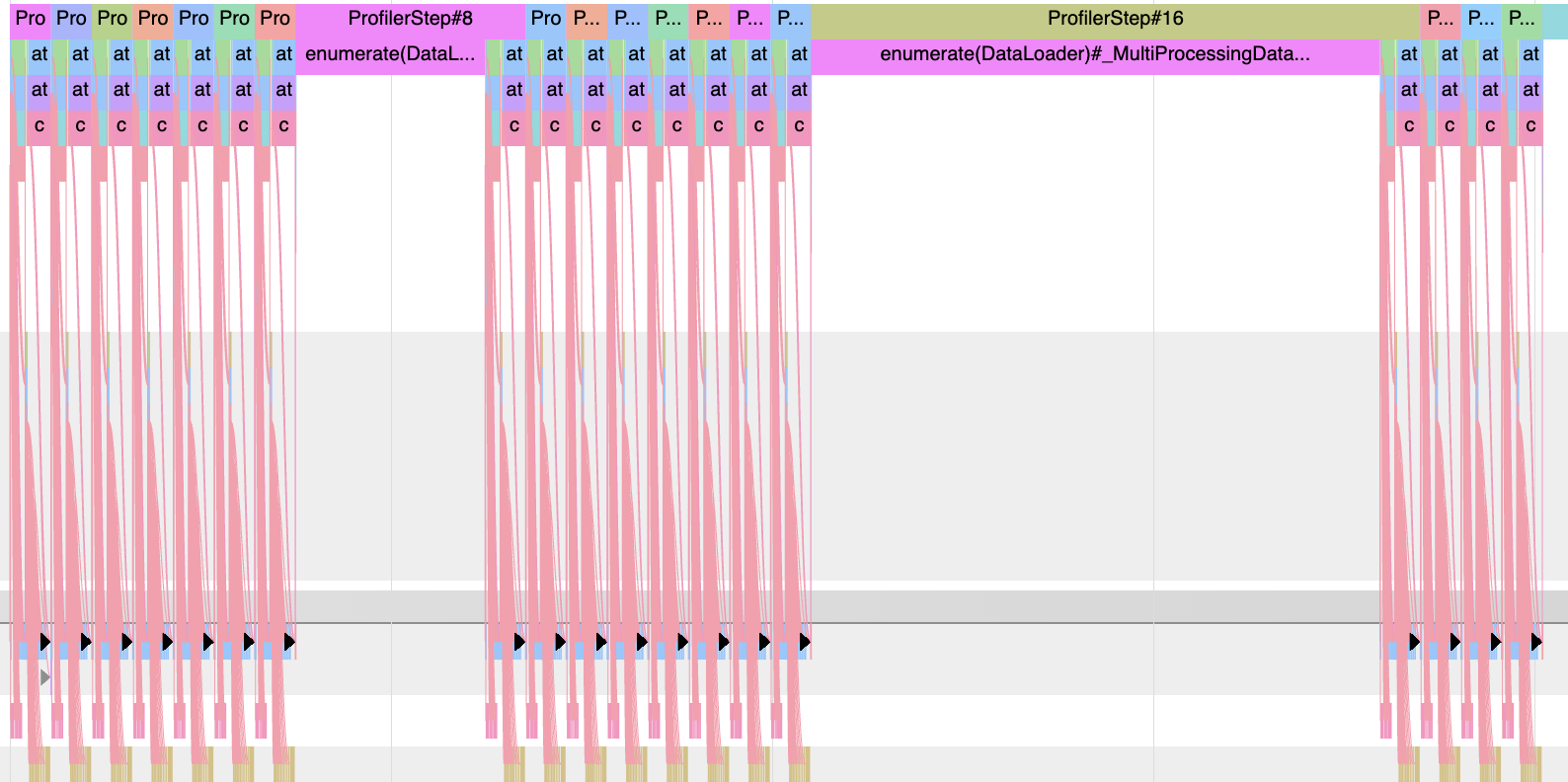
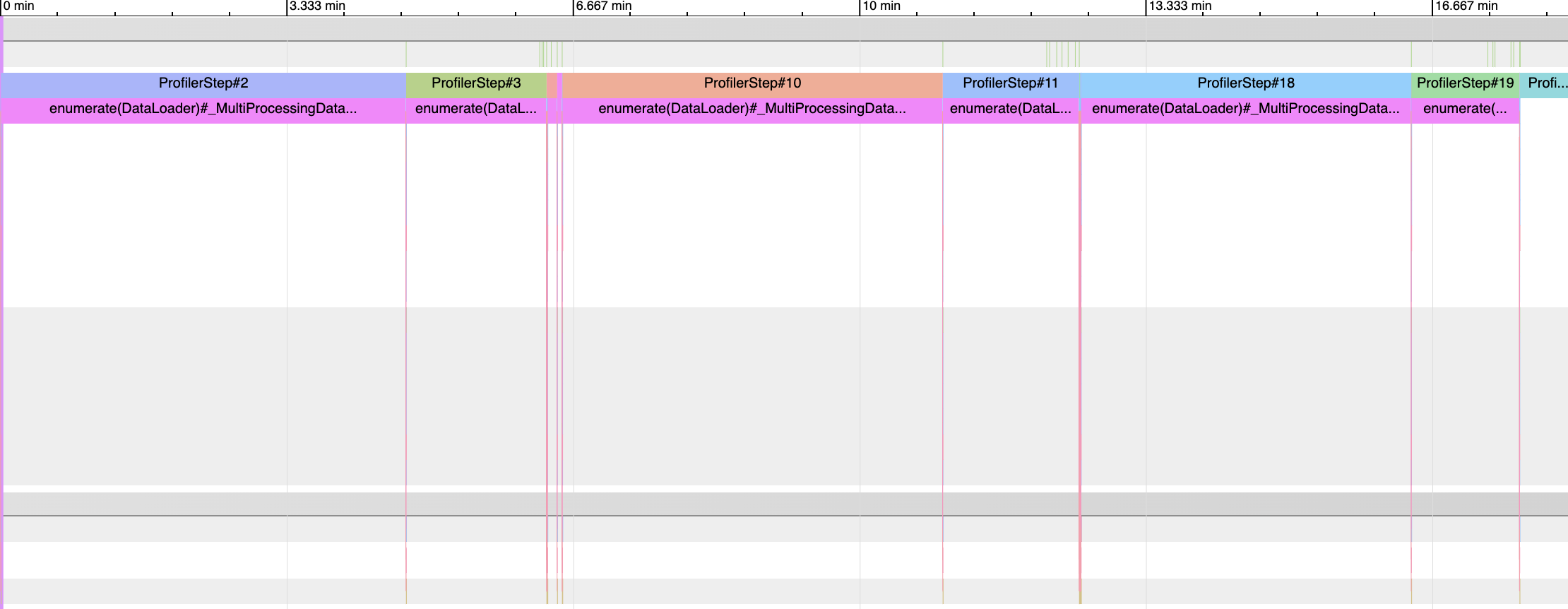
Nevermind, I figured it out, optimizing num_worker or batch_size contributes so little to the GPU util or runtime, I did a grid search about which combination works the best, but even the best one gave me only 11%. Moving the data to better IO performance file system is the key point. I moved the datasets to all flash system and the speed increased about 5 times. (although the first epoch is still so slow…)
Hi guys, this might be an old thread but I’m here to share one simple formula to determine how many workers does it need to “hide” data time during training.
Assume:
- Calling
dataset.__getitem__for one time takesTs. - Training the model with one batch of data takes
T0. - Batch size
B. - Number of workers for dataloader
N.
In the beginning, N batches are loaded by N workers, and will be consumed by training in N*T0. Meanwhile, loading N batches of data costs B*Ts with N workers. To make sure the pre-loaded data never runs out(so we have to wait for data, blocking the training), just set N*T0>=B*Ts, i.e. N>=B*Ts/T0.
In such case, the data time should be “hided” in training process, looks like data come for free.
For CPU-hungry datasets(such as heavy augmentation), this simple formula served me quite well whenever there are enough CPU cores. Haven’t done enough experiments for IO-hungry datasets though.
Simple code to test:
import time
from torch.utils.data import Dataset, DataLoader
class Timer:
def __init__(self) -> None:
self.start = time.monotonic()
def get_elapsed(self):
return time.monotonic() - self.start
def restart(self):
self.start = time.monotonic()
class MyDataset(Dataset):
def __len__(self):
return 16
def __getitem__(self, idx):
time.sleep(1) # Dataloading takes 1s for each sample
return idx
def main():
dataset = MyDataset()
dataloader = DataLoader(dataset, batch_size=2, num_workers=4)
timer = Timer()
for idx, _ in enumerate(dataloader):
print(f'step {idx} datatime', timer.get_elapsed())
time.sleep(0.5) # Training takes 0.5s.
timer.restart()
if __name__ == '__main__':
main()
In above code, num_workers = 1.0 / 0.5 * 2 = 4, output shows no data time bump as expected:
step 0 datatime 2.1367870941758156
step 1 datatime 0.0018968097865581512
step 2 datatime 0.0010941512882709503
step 3 datatime 0.0001705363392829895
step 4 datatime 0.001009829342365265
step 5 datatime 0.0010649338364601135
step 6 datatime 0.0009553171694278717
step 7 datatime 0.0009617917239665985
If we change the num worker to 3:
step 0 datatime 2.101318821310997
step 1 datatime 0.0014366395771503448
step 2 datatime 0.008020590990781784
step 3 datatime 0.47045280039310455
step 4 datatime 0.0008497759699821472
step 5 datatime 0.0008990578353404999
step 6 datatime 0.4984109178185463
step 7 datatime 0.0008906014263629913
Data time bumps every 3 iters.