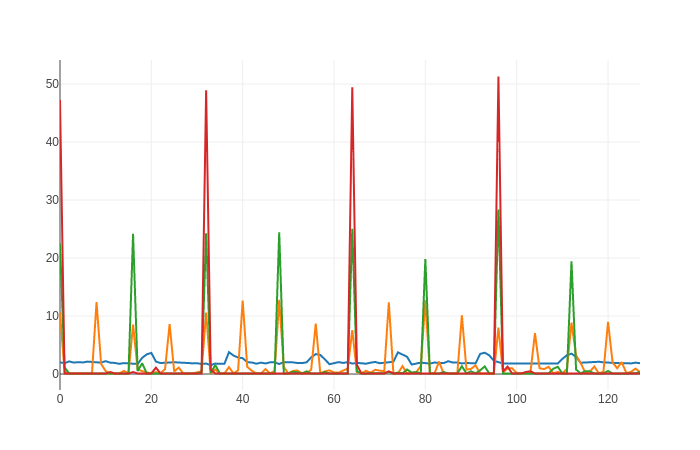
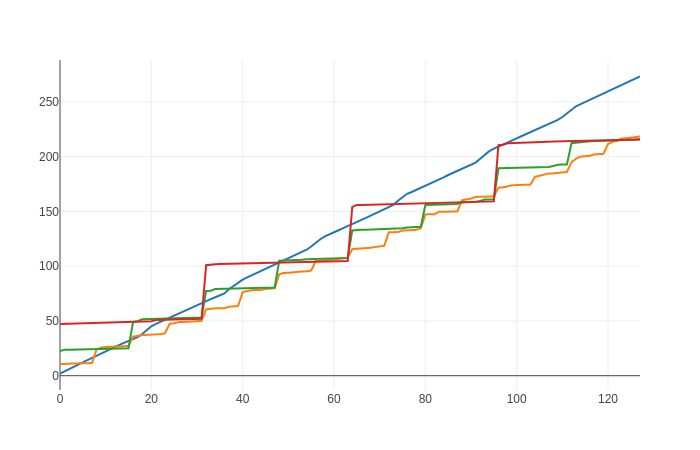
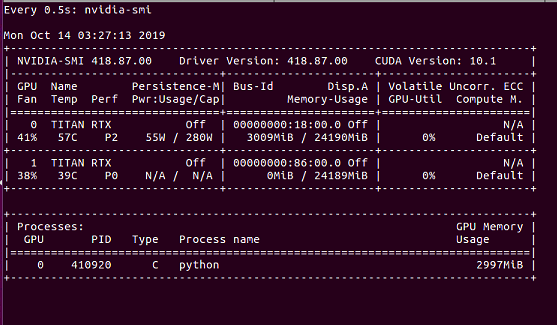
My DataLoader takes a lot of time for every nth iteration and a fraction of second for all other iterations. What could be the reason? I am using 8 threads for data reading with a batch_size of 128. Here is the log (numbers in the paranthesis are running averages):
The loading might be too slow. Have you tried to increase the number of workers or decrease the batch size?
Are you working on a HDD, SSD or do you pull your data from a server in your network?
I am pulling the data from an NFS server. But I am wondering why it impacts every nth batch only? I tried to reduce the batch size to 64, it reduces the time but the pattern is still the same. Every nth batch takes much more time as compared to other batches.
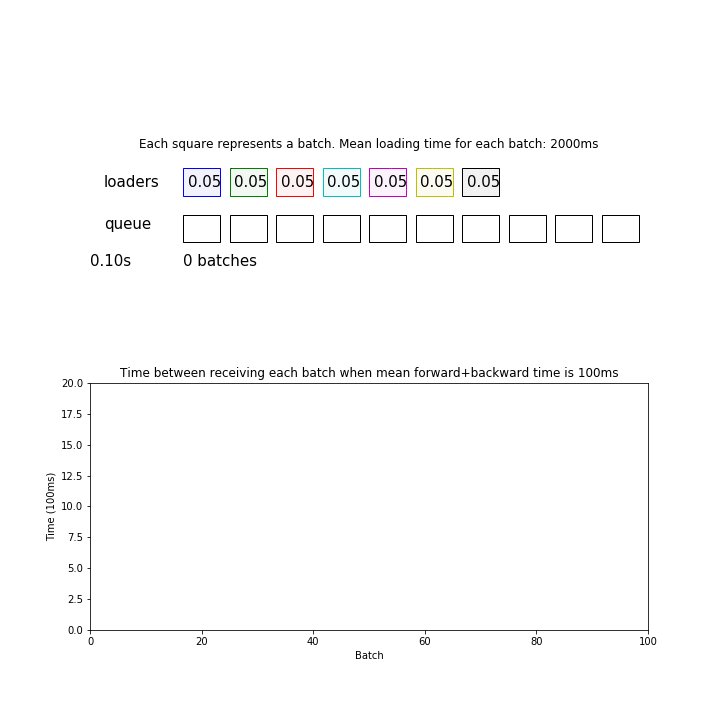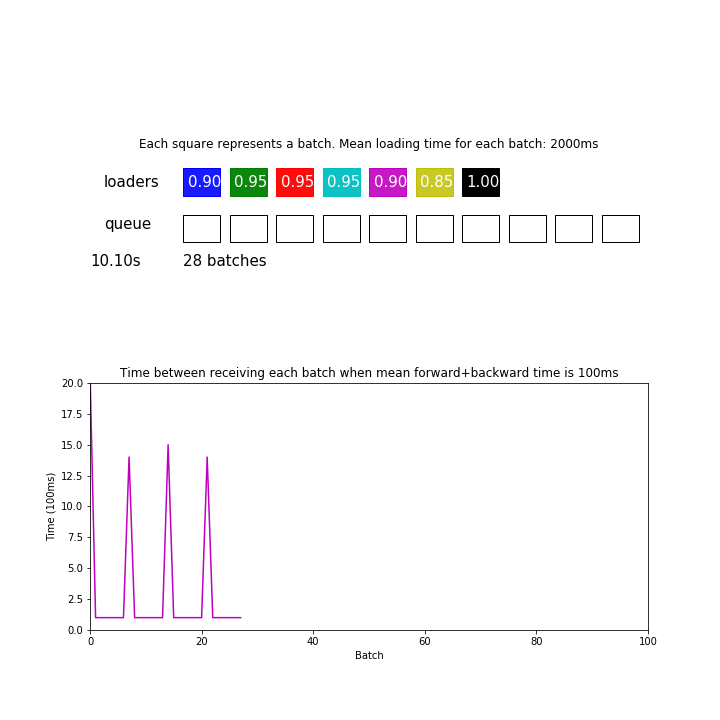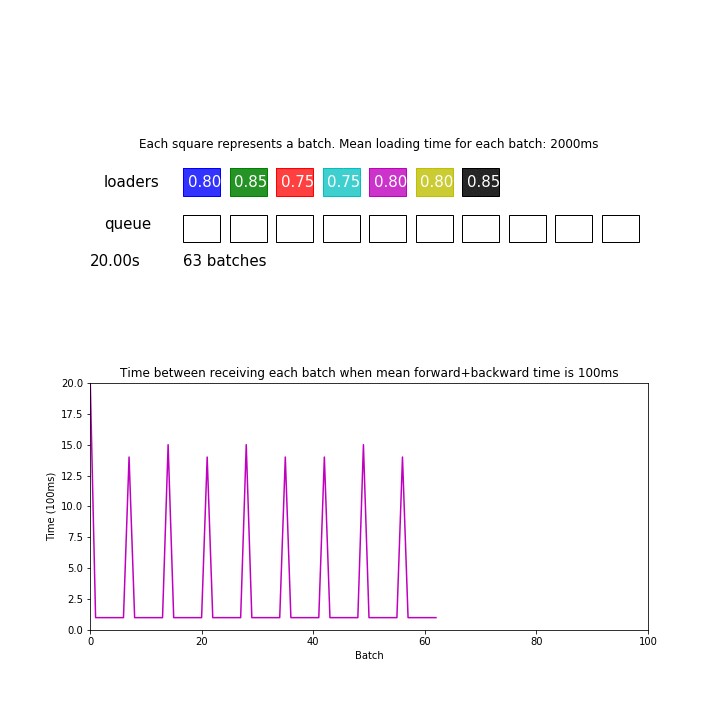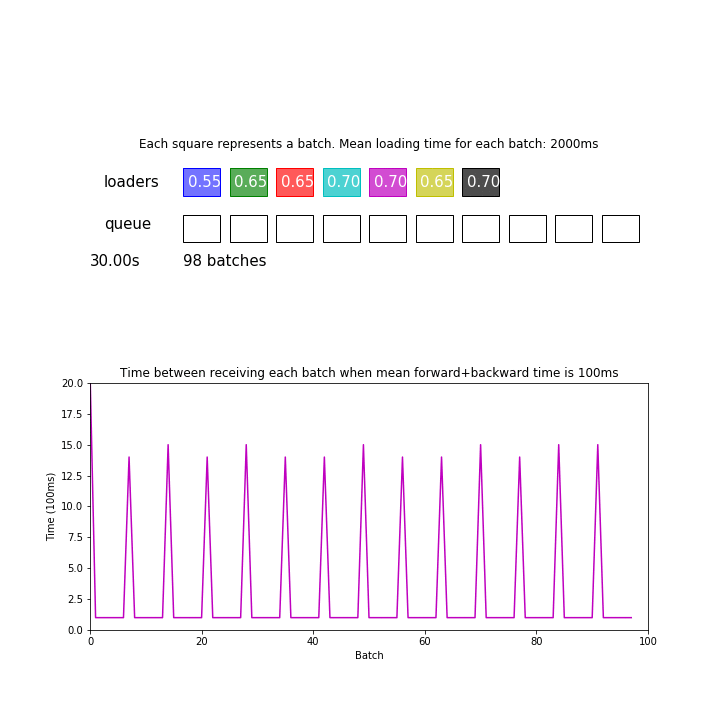
Well, as you can see, every 8th batch is slower while you are using 8 workers. Apparently it takes each worker more than 20 seconds to pull 128 samples from the server, while each training step is much faster. Probably you can also see the GPU starving in the meantime (nvidia-smi shows zero workload).
If it’s possible, save the data locally. I doubt increasing the workers will give you the desired performance boost. The connection seems to be just too slow for that.
Also, what kind of data are you using? If it’s image data and you are resizing the images as a pre processing step, you could also try to resize the images on the server and pull these smaller images.
@JiangPQ In my case, it turned out that reading the data from the NFS server was the main bottleneck. Moving the data to local hard-drive really improved the speed. How’s it in your case, how many workers are you using, and how are you reading your data, any augmentations?
@ptrblck Yes, I have a lot of processing to do, but reading data from the server was the main bottleneck, though the GPU is still starving but not as much as it was before. Saving the augmented images on disk would take a lot of space, I guess.
In my case, the ImageNet dataset is on my local HDD. I use torchvision.datasets.ImageFolder and torch.utils.data.DataLoader with batch_size=32 shuffle=True num_workers=16 to load images. Only randomcrop is applied on the images for preprocessing.
The extra time T it costs for every Nth iteration is directly proportional to the thread number N.
T is about 15s or more when batch_size=32 and num_workers=16.
How about replacing ResizedCrop with RandomCrop (just for debugging)? Are your images super big? Pytorch uses PIL for all image processing operations which is not the fastest possible option. You can write your own transformation that uses OpenCV.
Thank you for your advises!
The sequential-imagenet-dataloader improved the data reading speed a lot. Although it took about 10h to generate the .lmdb file, it’s worth it.
Will pytorch include it? This helps people without high performance computers.
I am facing same problem when working ImageNet data, things are alright when I work with other datasets like Pascal VOC. Volatile gpu util is also showing 0% most of the time. Any solution for this problem?
The ‘nth iteration problem’ probably just happens because the data loading time has low variance between workers. If the data loading is efficient enough, this problem should naturally disappear.
@pen_good The optimal num_worker/batch_size will depend on systems and augmentation pipelines. For example, if you are not using storage that supports parallel IO, you can’t benefit much from increasing num_workers since you will be bound by IO. Also, if your augmentation pipeline involves lots of CPU-workload, it could make sense to use more num_workers than the number you use in other pipelines.