It seems the standard way to read data and feed it to a model is through the use of the data loader iterators in a loop, for example using the enumerate construct. For each iteration of this loop a single batch is loaded and then processed. I would expect the memory load of such a loop to be constant over time. Instead I observe a linear increase as if all batches are kept in memory. After a few batches I run out of memory. I suspect this behavior is due to circular references, so I tried to manually invoke the garbage collector to no avail. Has anybody run into this sort of issues?
1 Like
That shouldn’t happen. It could be a bug in your code. You’d have to provide more information.
GPU or CPU memory? In my first PyTorch training loop I made the mistake of collecting model outputs in a container before I copied from GPU tensors back to CPU and then numpy, that exhausted my GPU memory pretty quickly…
Could you share your data loader code?
Yes, it should not happen. in fact that is the whole point of having a data loader.
One possible reason I can think of - if you’re not scaling them to a fixed size while reading them, then it’s possible that a very large image makes your batch too large for your GPU.
It might be useful to see how your GPU usage grows over time across iterations. If it grows with every iteration, there’s a problem. If it suddenly grows out of bounds, there’s a problem in that batch. Anyway, let’s start by seeing your code!
Thanks for the replies. I will give more detail. First of all, I am talking about CPU RAM not GPU. My pipeline is a simple autoencoder and I have 500k images. Batches consist of 512 images. I fetch data from a local disk with a custom dataset class and then I use the dataloader from torch.utils:
loader = torch.utils.data.DataLoader(dset, batch_size=args.batch_size, shuffle=True, num_workers=args.workers, pin_memory=True)
The fact is that I can train this model but I need to ask for a huge amount of CPU RAM even though I would expect the memory load to be constant throughout one epoch of training. Instead I observe a linear increase in memory, a memory leak I guess. Here is a graphic of the memory load:

Each one of those cycles is an entire epoch. As you can see, the memory clearly increases throughout and I need more than 200GB of RAM otherwise I run out of memory.
I then stripped my code of all the unnecessary and now my train function that is called per each epoch looks like this:
def train(loader, epoch): for i, (input) in enumerate(loader): print('Epoch: [{0}][{1}/{2}]\t'.format(epoch+1, i+1, len(loader)))
Even like this the memory usage increases linearly as batches are loaded.
I have tried manually deleting variables and calling garbage collection to no avail.
Based on that graph you’ve got 512GB of RAM and it’s ramping to 200GB over the epoch and then back to 0? I’m not necessarily seeing an issue here if your system is of that scale. I assume then you may also have 8-16+ cores and may be using a high worker count, in which case you’ve could have a number of processes queuing up batches for preprocessing and ramping the memory as they do so…
To figure out whether this is expected behaviour or an issue, number of workers is required, the size of images in addition to the batch size. Also with regards to memory usage analysis, more detailed views of virtual, shared, and physical per process. Maybe an output of htop, turn off threads with ‘H’, sort by memory usage…
In these experiments I’m showing here I am using only one core and a single thread for loading. The batch size is 512 and the dataset is comprised of 500k images which means there are about 1k batches. Each image loaded is 224x224x3 but it is shrunk to 32x32x3 before being fed to a model. I feel that even with some overhead it doesn’t make sense that memory increases so much over the course of one epoch.
it’s possibly a leak. can you share a small script that reproduces the leak?
Without more details, we can’t help you. You shouldn’t reach those memory levels, you are probably loading the full dataset before iterating over it. Please refer to this post : DataLoader increases RAM usage every iteration
1 Like
I totally understand that it is hard to debug without looking at the code at least. I was thinking maybe this was a known issue with a known solution. I will post soon the code. It is a somewhat complicated pipeline and you won’t be able to run the training because the data comes from digital pathology images. Hopefully the code will illuminate on the issue. Thanks in advance.
After a lot of work into figuring this one out, it turned out that the leak was happening in a different python package, “openslide”, which is necessary for handling the digital pathology whole slides. Sorry for the trouble and thanks for your help.
1 Like
I wanna ask a question… When I running my code, I find the cached mem increased every iteration, until the RAM is full.
Is that a common issue or a memory leak?
when i use “top” command in terminal, I see that:

Thanks!
It sounds like a memory leak.
Could you provide a (small) code snippet reproducing this behavior so that we can have a look?
I just run the code for depth completion task : GitHub - abdo-eldesokey/nconv: A PyTorch implementation for our work "Confidence Propagation through CNNs for Guided Sparse Depth Regression"
(I also open an issue in that repository…)
I try to only load data and do nothing for test like:
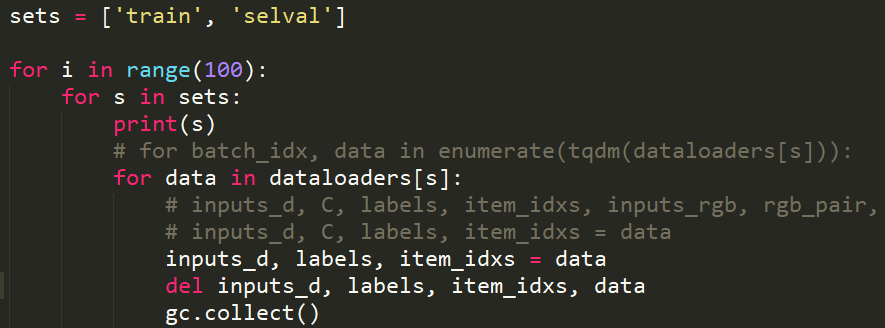
the cached mem still increases…
The dataset I used is KITTI dataset for depth completion, with resolution 1242x375 (center crop to 1216x352), batch_size=8, and I try to set the dataloader num_worker=0, it’s still the same situation.
Thank you!
I think I misread your issue.
Do you mean by “until the RAM is full” that you get an out of memory error or is the cached memory just really big?
In the latter case, I don’t think this is a memory leak.
Yes, the latter case. ( sorry about my poor English…
But do you know what may be the reason for this case? Because I did not encounter this case in other tasks.
(maybe because of the dataset? or the image resolution? or the dataloader mechanism? or something…)
Thank you very much!