Hey,
I’m training a standard resnet50 classifier on Imagenet dataset, which contains over 1M images and weights 150+ GB. I’m using my own training script, but it’s a basic code using my torch dataloader on top of my own costume dataset.
My dataset is simple, in the init function it just saves the path to all the images, and in the getitem function it loads the image from the path (using PIL).
I’m using pytorch 1.7.1, training on 4 GPUs using DataParllel with batch size of 256, and 4 workers per gpu (16 overall). my OS is linux.
My trochvision transforms consists of: Resize 256x256 → random crop 224x224 → random horizontal flip.
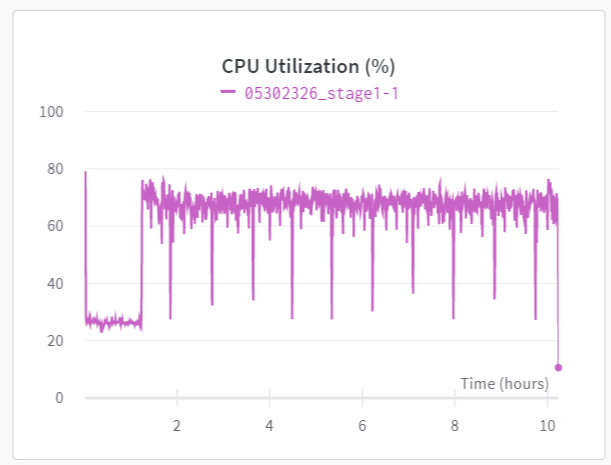
From my experience, usually the first epoch of training (for any dataset) is slower, but after that python/OS uses some caching mechanism, and reading images from the same path as before is much faster, thus training is much faster.
The problem when I’m training on imagenet, the epochs after the first one are still quite slow, so I figured maybe Imagenet is too big for the cahcing mechanism. And for some reason the first batches in each epochs are faster than the laster batches. For example:
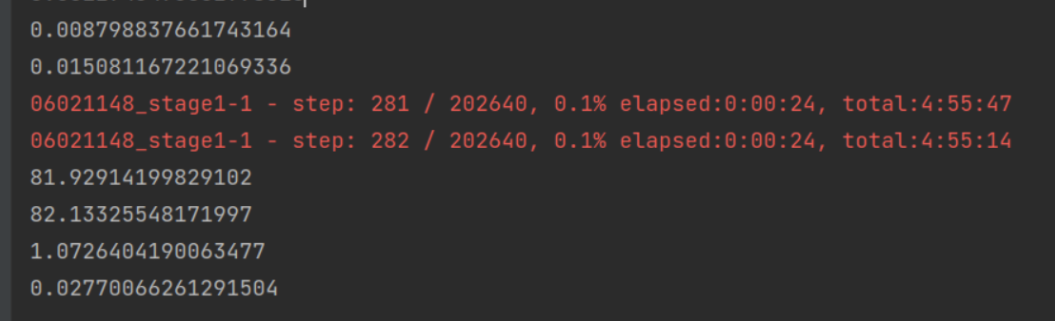
For the first batches each 100 batches take less than a minute:
04/04/2021 15:34:47 | epoch: 2/100, batch: 1/5004, loss: 0.8488723039627075, cls_loss: 0.8488723039627075, extra_losses: 0.0
04/04/2021 15:35:47 | epoch: 2/100, batch: 101/5004, loss: 0.677466869354248, cls_loss: 0.677466869354248, extra_losses: 0.0
04/04/2021 15:36:41 | epoch: 2/100, batch: 201/5004, loss: 0.7215250134468079, cls_loss: 0.7215250134468079, extra_losses: 0.0
04/04/2021 15:37:36 | epoch: 2/100, batch: 301/5004, loss: 0.716802716255188, cls_loss: 0.716802716255188, extra_losses: 0.0
04/04/2021 15:38:34 | epoch: 2/100, batch: 401/5004, loss: 0.6812710165977478, cls_loss: 0.6812710165977478, extra_losses: 0.0
For the last batches it takes more than 3 minutes:
04/04/2021 17:39:16 | epoch: 2/100, batch: 4601/5004, loss: 0.6854965686798096, cls_loss: 0.6854965686798096, extra_losses: 0.0
04/04/2021 17:42:43 | epoch: 2/100, batch: 4701/5004, loss: 0.6471158266067505, cls_loss: 0.6471158266067505, extra_losses: 0.0
04/04/2021 17:46:12 | epoch: 2/100, batch: 4801/5004, loss: 0.7266726493835449, cls_loss: 0.7266726493835449, extra_losses: 0.0
04/04/2021 17:49:42 | epoch: 2/100, batch: 4901/5004, loss: 0.6799284219741821, cls_loss: 0.6799284219741821, extra_losses: 0.0
04/04/2021 17:52:28 | epoch: 2/100, batch: 5001/5004, loss: 0.7079518437385559, cls_loss: 0.7079518437385559, extra_losses: 0.0
Question: Is there a way to make the training faster? The IO is a big bottleneck, and since my machine has around 120GB of RAM, I can’t load all my images into RAM.
Maybe is there a workaround, or some pytorch related solution?