I’m trying to train a CNN on retinal images. I’m using Torch ImageFolder to load in data. However, I’m running into a TypeError that suggests the Torch dataloader is iterating through my dataset using np.float64 indices rather than integer indices. I’ve uploaded my code with comments and the full stack trace. I haven’t been able to find an answer online and I’m quite confused as to how my code could have resulted in this error. Any help would be very very much appreciated.
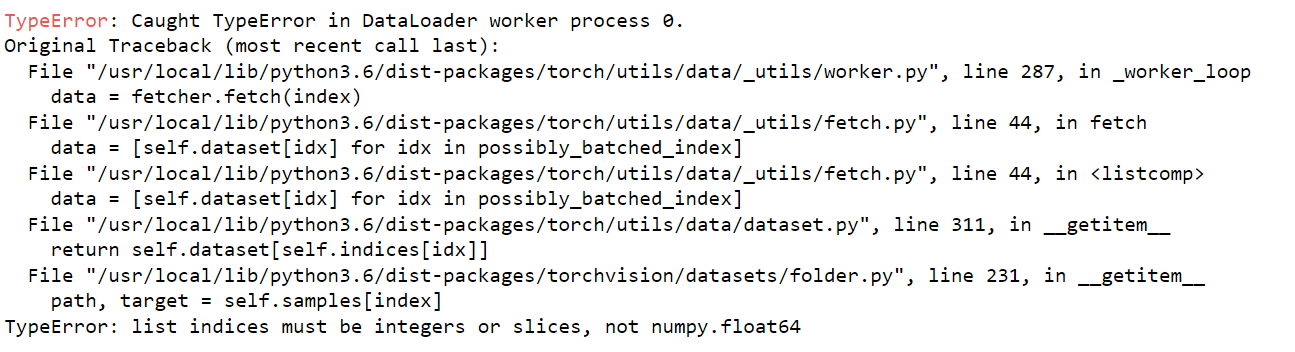
Full Stack Trace:
TypeError Traceback (most recent call last)
<ipython-input-46-94e0e5ea3e09> in <module>
13 os.makedirs(os.path.join('outputs', 'optimizers', experiment_name))
14
---> 15 train(data_dir, experiment_name, X_train, y_train) # save X_train in csv
<ipython-input-44-153a42274efe> in train(data_dir, experiment_name, X_train, y_train, num_classes, batch_size, num_epochs, lr, image_size)
125
126 print ("Model is fitting. Thank you for your patience.")
--> 127 net.fit(train_subset, y=None)
128
129 print ("Model is performing inference. Results saved in probabilities folder.")
/usr/local/lib/python3.6/dist-packages/skorch/classifier.py in fit(self, X, y, **fit_params)
139 # this is actually a pylint bug:
140 # https://github.com/PyCQA/pylint/issues/1085
--> 141 return super(NeuralNetClassifier, self).fit(X, y, **fit_params)
142
143 def predict_proba(self, X):
/usr/local/lib/python3.6/dist-packages/skorch/net.py in fit(self, X, y, **fit_params)
1213 self.initialize()
1214
-> 1215 self.partial_fit(X, y, **fit_params)
1216 return self
1217
/usr/local/lib/python3.6/dist-packages/skorch/net.py in partial_fit(self, X, y, classes, **fit_params)
1172 self.notify('on_train_begin', X=X, y=y)
1173 try:
-> 1174 self.fit_loop(X, y, **fit_params)
1175 except KeyboardInterrupt:
1176 pass
/usr/local/lib/python3.6/dist-packages/skorch/net.py in fit_loop(self, X, y, epochs, **fit_params)
1089
1090 self.run_single_epoch(dataset_valid, training=False, prefix="valid",
-> 1091 step_fn=self.validation_step, **fit_params)
1092
1093 self.notify("on_epoch_end", **on_epoch_kwargs)
/usr/local/lib/python3.6/dist-packages/skorch/net.py in run_single_epoch(self, dataset, training, prefix, step_fn, **fit_params)
1118
1119 batch_count = 0
-> 1120 for batch in self.get_iterator(dataset, training=training):
1121 self.notify("on_batch_begin", batch=batch, training=training)
1122 step = step_fn(batch, **fit_params)
/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py in __next__(self)
519 if self._sampler_iter is None:
520 self._reset()
--> 521 data = self._next_data()
522 self._num_yielded += 1
523 if self._dataset_kind == _DatasetKind.Iterable and \
/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py in _next_data(self)
1201 else:
1202 del self._task_info[idx]
-> 1203 return self._process_data(data)
1204
1205 def _try_put_index(self):
/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataloader.py in _process_data(self, data)
1227 self._try_put_index()
1228 if isinstance(data, ExceptionWrapper):
-> 1229 data.reraise()
1230 return data
1231
/usr/local/lib/python3.6/dist-packages/torch/_utils.py in reraise(self)
423 # have message field
424 raise self.exc_type(message=msg)
--> 425 raise self.exc_type(msg)
426
427
TypeError: Caught TypeError in DataLoader worker process 0.
Original Traceback (most recent call last):
File "/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/worker.py", line 287, in _worker_loop
data = fetcher.fetch(index)
File "/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/fetch.py", line 44, in fetch
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/usr/local/lib/python3.6/dist-packages/torch/utils/data/_utils/fetch.py", line 44, in <listcomp>
data = [self.dataset[idx] for idx in possibly_batched_index]
File "/usr/local/lib/python3.6/dist-packages/torch/utils/data/dataset.py", line 311, in __getitem__
return self.dataset[self.indices[idx]]
File "/usr/local/lib/python3.6/dist-packages/torchvision/datasets/folder.py", line 231, in __getitem__
path, target = self.samples[index]
TypeError: list indices must be integers or slices, not numpy.float64
My Train Code
def train(data_dir, experiment_name, X_train, y_train,
num_classes=2, batch_size=64, num_epochs=50, lr=0.001, image_size = (224, 224)):
# USING GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
if device == 'cuda:0':
torch.cuda.empty_cache()
# TRANSFORMING TRAIN/TEST DATA
train_transforms = transforms.Compose([transforms.Resize(image_size), # since not applying any of my own funcs
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(25),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])]) # why this normalizing?
test_transforms = transforms.Compose([transforms.Resize(image_size),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])])
# APPENDING DATA TO DATA FOLDERS. THE FOLDERS ARE SETUP TO EACH CONTAIN THE TWO CLASS FOLDERS
# TRAIN/CLASS1 TRAIN/CLASS2 TEST/CLASS1 TEST/CLASS2
train_folder = os.path.join(data_dir, 'train')
test_folder = os.path.join(data_dir, 'test')
train_dataset = datasets.ImageFolder(train_folder, train_transforms)
test_dataset = datasets.ImageFolder(test_folder, test_transforms)
# DEFINING VALIDATION SPLIT FOR 5-FOLD CROSS VALIDATION
indxs = np.arange(0,len(train_dataset))
skf = StratifiedKFold(n_splits=5, shuffle=True) # different splits each time
for i, (train_split, val_split) in enumerate(skf.split(X_train, y_train)):
f_params = f'./outputs/checkpoints/{experiment_name}/model_fold{i+1}.pt'
f_history = f'./outputs/histories/{experiment_name}/model_fold{i+1}.json'
f_optimize = f'./outputs/optimizers/{experiment_name}/model_fold{i+1}.json'
f_criterion = f'./outputs/criterions/{experiment_name}/model_fold{i+1}.json'
csv_name = f'./outputs/probabilities/{experiment_name}/model_fold{i+1}.csv'
val_patient = np.array(X_train.loc[val_split]['id'])
train_patient = np.array(X_train.loc[train_split]['id'])
val_indxs = np.negative(np.ones(len(train_dataset)))
for j in range(len(train_dataset.samples)):
sample_id = re.sub('.*/', '',str(train_dataset.samples[j][0]))
sample_id = sample_id.split("_")[0] # bc of new naming conv.
if np.any(val_patient == int(sample_id)) == True:
val_indxs[j] = j
val_indxs = val_indxs[val_indxs >= 0]
train_indxs = list(set(indxs) - set(val_indxs))
print(len(val_indxs), len(train_indxs))
train_subset = torch.utils.data.Subset(train_dataset, train_indxs)
val_subset = torch.utils.data.Subset(train_dataset, val_indxs)
print ("Train/Test/Val datasets have been created.")
# WEIGHTED SAMPLING}
labels = [x[1] for x in train_subset]
labels = np.array(labels)
labels = labels.astype(int)
black_weight = 1 / len(labels[labels == 0])
white_weight = 1 / len(labels[labels == 1])
sample_weights = np.array([black_weight, white_weight])
weights = sample_weights[labels]
sampler = torch.utils.data.WeightedRandomSampler(weights, len(train_subset), replacement=True)
print()
print(f'Data Directory: {data_dir}')
print(f'Number of black eyes: {len(labels[labels == 0])}')
print(f'Number of white eyes: {len(labels[labels == 1])}')
print(f'Device: {device}')
print()
# SETTING MODEL PARAMETERS WITH SKORCH
checkpoint = Checkpoint(monitor='valid_loss_best',
f_params=f_params,
f_history=f_history,
f_optimizer=f_optimize,
f_criterion=f_criterion)
train_acc = EpochScoring(scoring='accuracy',
on_train=True,
name='train_acc',
lower_is_better=False)
train_auc = EpochScoring(scoring='roc_auc', name ='train_auc', on_train=True, lower_is_better=False)
valid_auc = EpochScoring(scoring='roc_auc', name ='valid_auc', lower_is_better=False)
early_stopping = EarlyStopping()
callbacks = [train_auc, valid_auc, checkpoint, train_acc, early_stopping]
net = NeuralNetClassifier(PretrainedModel,
criterion=nn.CrossEntropyLoss,
lr=lr,
batch_size=batch_size,
max_epochs=num_epochs,
module__output_features=num_classes,
optimizer=optim.SGD,
optimizer__momentum=0.9,
iterator_train__num_workers=1,
iterator_train__sampler=sampler,
iterator_valid__shuffle=False,
iterator_valid__num_workers=1,
train_split=predefined_split(val_subset),
callbacks=callbacks,
device=device)
# SKORCH MODEL FITTING
print ("Model is fitting. Thank you for your patience.")
net.fit(train_subset, y=None)
print ("Model is performing inference. Results saved in probabilities folder.")
# SAVING RESULTS
img_locs = [loc for loc, _ in test_dataset.samples]
test_probs = net.predict_proba(test_dataset)
test_probs = [prob[0] for prob in test_probs]
data = {'img_loc' : img_locs, 'probability' : test_probs}
pd.DataFrame(data=data).to_csv(csv_name, index=False)
print (f"Model {i} is done and saved.")
print ("The code is done.")```