I am training a ResNet50 from scratch using ImageNet-1k using DDP and torchrun on an HPC cluster. I use a single node with 4 Tesla V100 GPUs and 2 Intel Xeon CPUs (28 cores in total). I roughly followed the PyTorch reference training code here. I realized that the DataLoader is creating a bottleneck on the duration of my training. For this, I experimented with different numbers of workers and prefetch factors, along with varying combinations of the booleans for pin memory, persistent workers, and non-blocking. For simplicity, I used True for all of these booleans when obtaining the results I put here.
In the first experiment, I used tqdm to see the time it takes for each epoch. The best performance is achieved with num_workers=0 and prefetch_factor=0. When num_workers>0, the epoch duration increases drastically.
num_workers=0&prefetch_factor=0–> epoch duration: ~46 mins 16 secsnum_workers=4&prefetch_factor=2–> epoch duration: ~2 hrs 44 min 56 secsnum_workers=4&prefetch_factor=4–> epoch duration: ~2 hrs 42 min 5 secsnum_workers=16&prefetch_factor=4–> epoch duration: ~2 hrs 43 min 25 secsnum_workers=24&prefetch_factor=4–> epoch duration: ~2 hrs 44 min 33 secs
One interesting observation I had is that, when num_workers=0 and prefetch_factor=0, the batch durations are consistently around 1.05s/it. However, when I set, for example, num_workers=16 and prefetch_factor=4, there are periodically some very long durations per batch (~10 secs/it) in between “normal” durations of ~1 sec/it per batch, as follows:
Output of the training code for num_workers=16 and prefetch_factor=4
Batches: 15%|█▌ | 376/2502 [25:54<1:00:34, 1.71s/it]
Batches: 15%|█▌ | 377/2502 [25:54<45:12, 1.28s/it]
Batches: 15%|█▌ | 378/2502 [25:54<34:27, 1.03it/s]
Batches: 15%|█▌ | 379/2502 [25:55<26:55, 1.31it/s]
Batches: 15%|█▌ | 380/2502 [25:55<21:40, 1.63it/s]
Batches: 15%|█▌ | 381/2502 [25:55<17:59, 1.97it/s]
Batches: 15%|█▌ | 382/2502 [25:57<33:07, 1.07it/s]
Batches: 15%|█▌ | 383/2502 [25:58<29:44, 1.19it/s]
Batches: 15%|█▌ | 384/2502 [25:58<23:37, 1.49it/s]
Batches: 15%|█▌ | 385/2502 [27:01<11:20:02, 19.27s/it]
Batches: 15%|█▌ | 386/2502 [27:03<8:25:04, 14.32s/it]
Batches: 15%|█▌ | 387/2502 [27:04<5:56:13, 10.11s/it]
Batches: 16%|█▌ | 388/2502 [27:04<4:12:03, 7.15s/it]
Batches: 16%|█▌ | 389/2502 [27:04<2:59:10, 5.09s/it]
Batches: 16%|█▌ | 390/2502 [27:04<2:08:09, 3.64s/it]
Batches: 16%|█▌ | 391/2502 [27:05<1:32:28, 2.63s/it]
Batches: 16%|█▌ | 392/2502 [27:05<1:07:31, 1.92s/it]
Batches: 16%|█▌ | 393/2502 [27:05<50:02, 1.42s/it]
Batches: 16%|█▌ | 394/2502 [27:06<37:49, 1.08s/it]
Batches: 16%|█▌ | 395/2502 [27:06<29:16, 1.20it/s]
Batches: 16%|█▌ | 396/2502 [27:06<23:16, 1.51it/s]
Batches: 16%|█▌ | 397/2502 [27:06<19:05, 1.84it/s]
Batches: 16%|█▌ | 398/2502 [27:16<1:56:50, 3.33s/it]
Batches: 16%|█▌ | 399/2502 [27:17<1:27:28, 2.50s/it]
Batches: 16%|█▌ | 400/2502 [27:17<1:04:02, 1.83s/it]
Batches: 16%|█▌ | 401/2502 [28:03<8:47:53, 15.08s/it]
Batches: 16%|█▌ | 402/2502 [28:06<6:38:52, 11.40s/it]
Batches: 16%|█▌ | 403/2502 [28:06<4:41:52, 8.06s/it]
Batches: 16%|█▌ | 404/2502 [28:06<3:20:00, 5.72s/it]
Batches: 16%|█▌ | 405/2502 [28:07<2:22:43, 4.08s/it]
Batches: 16%|█▌ | 406/2502 [28:07<1:42:39, 2.94s/it]
Batches: 16%|█▋ | 407/2502 [28:07<1:14:36, 2.14s/it]
Batches: 16%|█▋ | 408/2502 [28:07<54:59, 1.58s/it]
Batches: 16%|█▋ | 409/2502 [28:08<41:15, 1.18s/it]
Batches: 16%|█▋ | 410/2502 [28:08<31:39, 1.10it/s]
Batches: 16%|█▋ | 411/2502 [28:08<24:55, 1.40it/s]
Batches: 16%|█▋ | 412/2502 [28:08<20:13, 1.72it/s]
In the second experiment, I used torch.profiler to have a more detailed investigation into what causes this increase. While num_workers=0 and prefetch_factor=0 has ~1sec dataloader__next__ calls, num_workers=4 and prefetch_factor=2 has occasional ~10 secs dataloader__next__ calls in between ~1sec dataloader__next__ calls.
Profiler output for num_workers=0 and prefetch_factor=0(left) and profiler output for num_workers=4 and prefetch_factor=2 (right) (as I am allowed to put only 1 image as a new user)
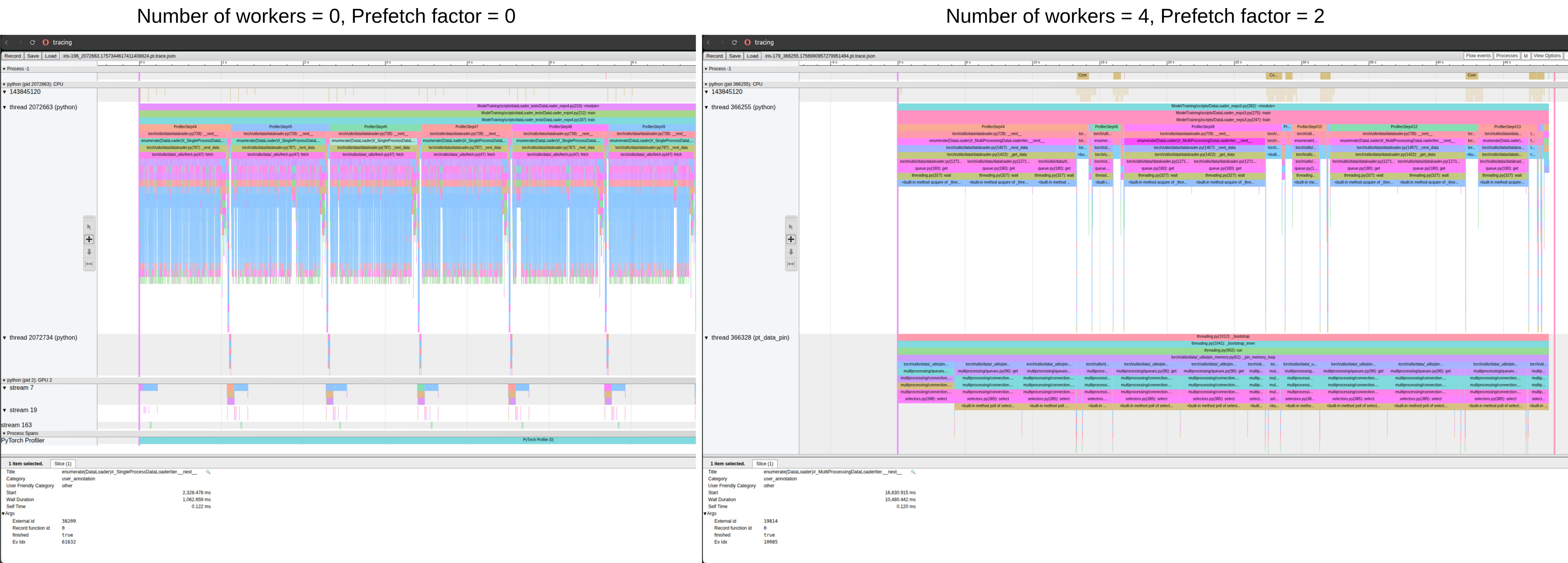
Could you please help me understand what causes this behaviour? I could also perform more experiments to see what causes this and appreciate any recommendations. Thank you!
Experiment 1: using tqdm
import torchvision
from torchvision.transforms import v2 as tvt
import torch
import argparse
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
import os
from ModelTraining.source import pytorch_utils as pu
parser = argparse.ArgumentParser()
parser.add_argument("-pb", "--Pinbool", type=str)
parser.add_argument("-nbb", "--Nonblockingbool", type=str)
parser.add_argument("-nw", "--Numworkers", type=int)
parser.add_argument("-pf", "--Prefetch", type=int)
parser.add_argument("-pw", "--Persistent", type=str)
args = parser.parse_args()
pin_bool = args.Pinbool
if pin_bool == 'True':
PINBOOL = True
elif pin_bool == 'False':
PINBOOL = False
nonblocking_bool = args.Nonblockingbool
if nonblocking_bool == 'True':
NONBLOCKINGBOOL = True
elif nonblocking_bool == 'False':
NONBLOCKINGBOOL = False
persistent_workers = args.Persistent
if persistent_workers == 'True':
PERSISTENTWORKERS = True
elif persistent_workers == 'False':
PERSISTENTWORKERS = False
NUMWORKERS = args.Numworkers
PREFETCHFACTOR = args.Prefetch
SEED = 42
iteration = 1
NGPUS = 4
BATCH_SIZE = 128
EPOCHS = 1
DATASET_SIZE = 1281167 # ImageNet training dataset size
MOMENTUM = 0.9
LEARNING_RATE = 0.5
LR_WARMUP_EPOCHS = 5
LR_WARMUP_DECAY = 0.01
WEIGHT_DECAY = 0.00002
NORM_WEIGHT_DECAY = 0.0
LABEL_SMOOTHING = 0.1
MIXUP_ALPHA=0.2
CUTMIX_ALPHA=1.0
RANDOM_ERASE=0.1
RA_SAMPLER = True
RA_REPS=4
MODEL_EMA = True
MODEL_EMA_STEPS = 32
MODEL_EMA_DECAY = 0.99998
VAL_RESIZE_SIZE = 232
VAL_CROP_SIZE = 224
TRAIN_CROP_SIZE = 176
world_size = torch.cuda.device_count()
def ddp_setup():
init_process_group(backend="nccl")
def initialize(pinbool, batchsize, numworkers, prefetchfactor, persistentworkers):
gpu_id = int(os.environ["LOCAL_RANK"])
preset_train = pu.ClassificationPresetTrain(
crop_size=TRAIN_CROP_SIZE,
interpolation=tvt.functional.InterpolationMode('bilinear'),
auto_augment_policy='ta_wide',
random_erase_prob=RANDOM_ERASE,
ra_magnitude=9,
augmix_severity=3,
backend='PIL',
use_v2=False)
traindata = torchvision.datasets.ImageFolder('/work/imagenet/train/', preset_train)
trainsampler = pu.RASampler(traindata, shuffle=True, repetitions=RA_REPS, seed=SEED)
num_classes = len(traindata.classes)
mixup_cutmix = pu.get_mixup_cutmix(mixup_alpha=MIXUP_ALPHA, cutmix_alpha=CUTMIX_ALPHA, num_classes=num_classes)
def collate_fn(batch):
return mixup_cutmix(*torch.utils.data.dataloader.default_collate(batch))
if numworkers > 0:
if prefetchfactor == 0:
trainloader = torch.utils.data.DataLoader(traindata, batch_size=batchsize, sampler=trainsampler, pin_memory=pinbool, num_workers=numworkers, collate_fn=collate_fn, prefetch_factor=None, persistent_workers=persistentworkers)
else:
trainloader = torch.utils.data.DataLoader(traindata, batch_size=batchsize, sampler=trainsampler, pin_memory=pinbool, num_workers=numworkers, collate_fn=collate_fn, prefetch_factor=prefetchfactor, persistent_workers=persistentworkers)
elif numworkers == 0:
trainloader = torch.utils.data.DataLoader(traindata, batch_size=batchsize, sampler=trainsampler, pin_memory=pinbool, num_workers=numworkers, collate_fn=collate_fn, prefetch_factor=None)
model = torchvision.models.resnet50(weights=None)
model.to(gpu_id)
model = DDP(model, device_ids=[gpu_id])
parameters = pu.set_weight_decay(
model,
WEIGHT_DECAY,
norm_weight_decay=NORM_WEIGHT_DECAY,
custom_keys_weight_decay=None,
)
criterion = torch.nn.CrossEntropyLoss(label_smoothing=LABEL_SMOOTHING).to(gpu_id)
optimizer = torch.optim.SGD(parameters, lr=LEARNING_RATE, momentum=MOMENTUM, weight_decay=WEIGHT_DECAY)
main_lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=EPOCHS - LR_WARMUP_EPOCHS, eta_min=0.0)
warmup_lr_scheduler = torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=LR_WARMUP_DECAY, total_iters=LR_WARMUP_EPOCHS)
lr_scheduler = torch.optim.lr_scheduler.SequentialLR(optimizer, schedulers=[warmup_lr_scheduler, main_lr_scheduler], milestones=[LR_WARMUP_EPOCHS])
return trainloader, model, criterion, optimizer, lr_scheduler
def train(traindata, model, criterion, optimizer, lr_scheduler, gpu_id, pinbool, numworkers, prefetchfactor, persistentworkers, nonblockingbool, epochs_run = 0):
traindata.sampler.set_epoch(epochs_run)
model.train()
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA],
schedule=torch.profiler.schedule(
wait=2,
warmup=2,
active=12),
on_trace_ready=torch.profiler.tensorboard_trace_handler('/result_pb'+str(pinbool)+'_nw'+str(numworkers)+'_pf'+str(prefetchfactor)+'_pw'+str(persistentworkers)+'_nbb' +str(nonblockingbool)),
record_shapes=True,
profile_memory=True,
with_stack=True
) as p:
for batch_idx, (data, targets) in enumerate(traindata):
if nonblockingbool == True:
data = data.to(gpu_id, non_blocking=True)
targets = targets.to(gpu_id, non_blocking=True)
elif nonblockingbool == False:
data = data.to(gpu_id)
targets = targets.to(gpu_id)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, targets)
loss.backward()
optimizer.step()
p.step()
if batch_idx==18:
break
lr_scheduler.step()
epochs_run += 1
def main():
ddp_setup()
torch.cuda.manual_seed_all(SEED)
torch.manual_seed(SEED)
trainloader, model, criterion, optimizer, lr_scheduler = initialize(PINBOOL, BATCH_SIZE, NUMWORKERS, PREFETCHFACTOR, PERSISTENTWORKERS)
torch.cuda.manual_seed_all(SEED)
torch.manual_seed(SEED)
train(trainloader, model, criterion, optimizer, lr_scheduler, int(os.environ["LOCAL_RANK"]), PINBOOL, NUMWORKERS, PREFETCHFACTOR, PERSISTENTWORKERS, NONBLOCKINGBOOL)
destroy_process_group()
if __name__ == "__main__":
main()
Experiment 2: using torch.profiler
import torchvision
from torchvision.transforms import v2 as tvt
import torch
import argparse
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.distributed import init_process_group, destroy_process_group
import os
from ModelTraining.source import pytorch_utils as pu
parser = argparse.ArgumentParser()
parser.add_argument("-pb", "--Pinbool", type=str)
parser.add_argument("-nbb", "--Nonblockingbool", type=str)
parser.add_argument("-nw", "--Numworkers", type=int)
parser.add_argument("-pf", "--Prefetch", type=int)
parser.add_argument("-pw", "--Persistent", type=str)
args = parser.parse_args()
pin_bool = args.Pinbool
if pin_bool == 'True':
PINBOOL = True
elif pin_bool == 'False':
PINBOOL = False
nonblocking_bool = args.Nonblockingbool
if nonblocking_bool == 'True':
NONBLOCKINGBOOL = True
elif nonblocking_bool == 'False':
NONBLOCKINGBOOL = False
persistent_workers = args.Persistent
if persistent_workers == 'True':
PERSISTENTWORKERS = True
elif persistent_workers == 'False':
PERSISTENTWORKERS = False
NUMWORKERS = args.Numworkers
PREFETCHFACTOR = args.Prefetch
SEED = 42
iteration = 1
NGPUS = 4
BATCH_SIZE = 128
EPOCHS = 5
DATASET_SIZE = 1281167 # ImageNet training dataset size
MOMENTUM = 0.9
LEARNING_RATE = 0.5
LR_WARMUP_EPOCHS = 5
LR_WARMUP_DECAY = 0.01
WEIGHT_DECAY = 0.00002
NORM_WEIGHT_DECAY = 0.0
LABEL_SMOOTHING = 0.1
MIXUP_ALPHA=0.2
CUTMIX_ALPHA=1.0
RANDOM_ERASE=0.1
RA_REPS=4
TRAIN_CROP_SIZE = 176
world_size = torch.cuda.device_count()
def ddp_setup():
init_process_group(backend="nccl")
def initialize(pinbool, batchsize, numworkers, prefetchfactor, persistentworkers):
gpu_id = int(os.environ["LOCAL_RANK"])
preset_train = pu.ClassificationPresetTrain(
crop_size=TRAIN_CROP_SIZE,
interpolation=tvt.functional.InterpolationMode('bilinear'),
auto_augment_policy='ta_wide',
random_erase_prob=RANDOM_ERASE,
ra_magnitude=9,
augmix_severity=3,
backend='PIL',
use_v2=False)
traindata = torchvision.datasets.ImageFolder('/work/imagenet/train/', preset_train)
trainsampler = pu.RASampler(traindata, shuffle=True, repetitions=RA_REPS, seed=SEED)
num_classes = len(traindata.classes)
mixup_cutmix = pu.get_mixup_cutmix(mixup_alpha=MIXUP_ALPHA, cutmix_alpha=CUTMIX_ALPHA, num_classes=num_classes)
def collate_fn(batch):
return mixup_cutmix(*torch.utils.data.dataloader.default_collate(batch))
if numworkers > 0:
if prefetchfactor == 0:
trainloader = torch.utils.data.DataLoader(traindata, batch_size=batchsize, sampler=trainsampler, pin_memory=pinbool, num_workers=numworkers, collate_fn=collate_fn, prefetch_factor=None, persistent_workers=persistentworkers)
else:
trainloader = torch.utils.data.DataLoader(traindata, batch_size=batchsize, sampler=trainsampler, pin_memory=pinbool, num_workers=numworkers, collate_fn=collate_fn, prefetch_factor=prefetchfactor, persistent_workers=persistentworkers)
elif numworkers == 0:
trainloader = torch.utils.data.DataLoader(traindata, batch_size=batchsize, sampler=trainsampler, pin_memory=pinbool, num_workers=numworkers, collate_fn=collate_fn, prefetch_factor=None)
model = torchvision.models.resnet50(weights=None)
model.to(gpu_id)
model = DDP(model, device_ids=[gpu_id])
parameters = pu.set_weight_decay(
model,
WEIGHT_DECAY,
norm_weight_decay=NORM_WEIGHT_DECAY,
custom_keys_weight_decay=None,
)
criterion = torch.nn.CrossEntropyLoss(label_smoothing=LABEL_SMOOTHING).to(gpu_id)
optimizer = torch.optim.SGD(parameters, lr=LEARNING_RATE, momentum=MOMENTUM, weight_decay=WEIGHT_DECAY)
main_lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=EPOCHS - LR_WARMUP_EPOCHS, eta_min=0.0)
warmup_lr_scheduler = torch.optim.lr_scheduler.LinearLR(optimizer, start_factor=LR_WARMUP_DECAY, total_iters=LR_WARMUP_EPOCHS)
lr_scheduler = torch.optim.lr_scheduler.SequentialLR(optimizer, schedulers=[warmup_lr_scheduler, main_lr_scheduler], milestones=[LR_WARMUP_EPOCHS])
return trainloader, model, criterion, optimizer, lr_scheduler
def train(traindata, model, criterion, optimizer, lr_scheduler, gpu_id, pinbool, numworkers, prefetchfactor, persistentworkers, nonblockingbool, epochs_run = 0):
traindata.sampler.set_epoch(epochs_run)
model.train()
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA],
schedule=torch.profiler.schedule(
wait=2,
warmup=2,
active=12),
on_trace_ready=torch.profiler.tensorboard_trace_handler('/result_pb'+str(pinbool)+'_nw'+str(numworkers)+'_pf'+str(prefetchfactor)+'_pw'+str(persistentworkers)+'_nbb' +str(nonblockingbool)),
record_shapes=True,
profile_memory=True,
with_stack=True
) as p:
for batch_idx, (data, targets) in enumerate(traindata):
if nonblockingbool == True:
data = data.to(gpu_id, non_blocking=True)
targets = targets.to(gpu_id, non_blocking=True)
elif nonblockingbool == False:
data = data.to(gpu_id)
targets = targets.to(gpu_id)
optimizer.zero_grad()
output = model(data)
loss = criterion(output, targets)
loss.backward()
optimizer.step()
p.step()
if batch_idx==18:
break
lr_scheduler.step()
epochs_run += 1
def main():
ddp_setup()
torch.cuda.manual_seed_all(SEED)
torch.manual_seed(SEED)
trainloader, model, criterion, optimizer, lr_scheduler = initialize(PINBOOL, BATCH_SIZE, NUMWORKERS, PREFETCHFACTOR, PERSISTENTWORKERS)
torch.cuda.manual_seed_all(SEED)
torch.manual_seed(SEED)
train(trainloader, model, criterion, optimizer, lr_scheduler, int(os.environ["LOCAL_RANK"]), PINBOOL, NUMWORKERS, PREFETCHFACTOR, PERSISTENTWORKERS, NONBLOCKINGBOOL)
destroy_process_group()
if __name__ == "__main__":
main()