Hi everyone! I am trying to use a sliding window fashion to training my neural network. The sliding window slides inside one sequence, and multiple sequences are present in the dataset. When designing my dataset class, I use the np.vstack to concatenate different sequence together so as to have a sliding window to go through all data.
def load_data(self, files):
lookuptable = np.array([])
for fp_inlist in files:
h5_file = h5py.File(fp_inlist, 'r')
print('Start iterations among files')
# Walk through all groups, extracting datasets
for gname, group in h5_file.items():
# Count how many datasets inside one group
# num_datasets = len(group)
print('Start iterations among groups')
for dname, ds in group.items():
print('Start iterations among datasets')
signal = np.array(ds[0:60000, :])
# Mapping data into image scale(0-255)
data = ((signal)/np.max(signal)*255).astype(np.uint8)
# figure = plt.figure()
# plt.imshow(data.squeeze(), cmap="gray")
# plt.show()
print(data.shape)
if lookuptable.size == 0:
lookuptable = data
else:
lookuptable = np.vstack((lookuptable, data))
However, this can also provide a problem when the window slides to an end of one sequence, it takes the spliced window from two sequence. As it is illustrated in the image.
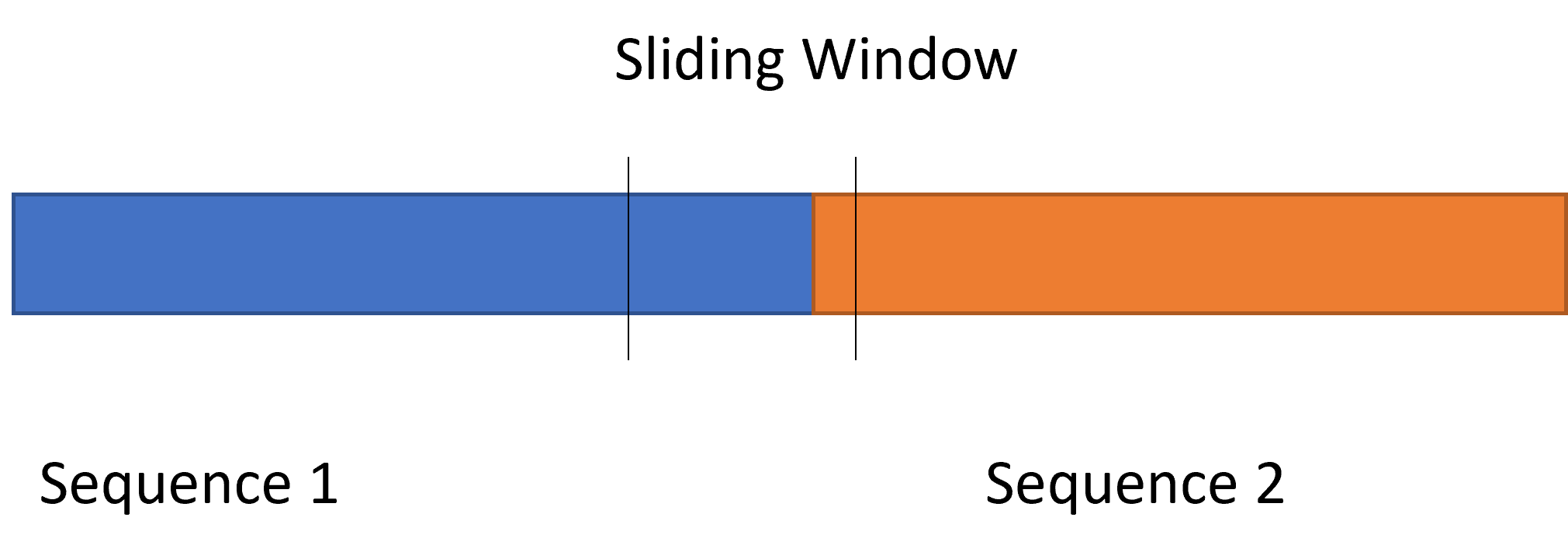
def __getitem__(self, idx): # Each time this func implemented by dataloader, rest lengths should be checked
# x = self.data[index:index+self.window]
# return x
# lookuptable = self.load_data(self.files)
# for idx in range(1, self.length - self.window):
# Mapping to [0,1] range and convert from numpy to torch.tensor
data = torch.from_numpy(self.lookuptable[10*idx : self.window+(10*idx), :]/255)
data = data.unsqueeze_(0)
if self.transform:
data = self.transform(data.unsqueeze_(0))
return data, label
The stride of the sliding is 10, goes through the whole concatenated sequence.
My question is, is there anyway to have the index picked by the dataloader can skip these spliced segments such that it only slides inside one sequence and jump to the next(without preparing data file of all sliding windows, which is really tedious and consuming lot of space).
Thanks in advance