I’m having an issue while training large amounts of audios(about 2 million wav). Dataloader becomes very slow when shuffle is True .When I set Shuffle False, It becomes normal. I rewrite collate_func which can use torchaudio.load to get waveforms from batch(wav_paths).
I wonder if it’s because many wavs locates different folders and it needs take time to find every wav? what should I do if I want to use Shuffle? Thanks!
You can try
train_sampler = torch.utils.data.RandomSampler(train_set)
and pass the sampler to the dataloader as
train_loaders = torch.utils.data.DataLoader(train_set,
shuffle=False,
sampler = train_sampler,
batch_size=train_batch_size,
num_workers=num_workers)
If that is still slow you can define a custom psuedo sampler by looking into the PyTorch RandomSampler.
Thanks for your reply very much ! But unfortunately ,I use RandomSampler and the problem still exists.
Then I random the wav list in my wav_path_file manually,and set the Shuffle False , It’s still slow . So I think it’s the problem of the length of wavs . I use torch.nn.utils.rnn.pad_sequence to pad the wavs_tensor in collate_func . When Shuffle is True , the wavs’s length become so different so the pad_sequence has to pad more and cost more time, and it might be the reason ?
More details:
I set num_workers = 4 and I find the workers pid becomes D . They seem to wait for something.

I try to use **ctrl+c" to interrupt the pids , and It says the pids hang to wait for something I don’t know.
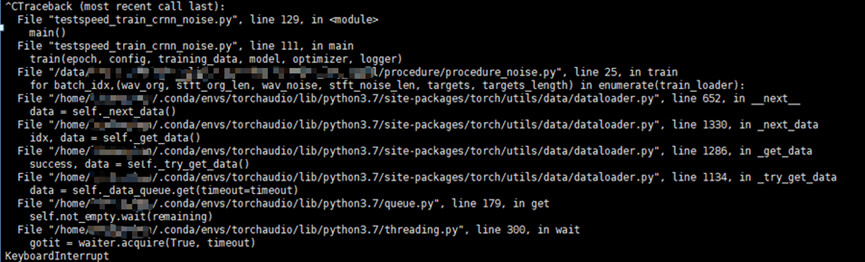
I have searched for similar problems on the Internet but they don’t work . I would appreciate it for your reply! Thanks!