I use the following code to train a model:
def train_per_epoch(self, epoch: int):
with torch.profiler.profile(
activities=[
torch.profiler.ProfilerActivity.CPU,
torch.profiler.ProfilerActivity.CUDA,
],
schedule=torch.profiler.schedule(wait=1, warmup=1, active=2, repeat=1),
on_trace_ready=torch.profiler.tensorboard_trace_handler('./plog'),
record_shapes=True,
profile_memory=True,
with_stack=True
) as profiler:
for data in self.dataloader:
data = self.dict_to_device(data)
loss = self.model(data)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
profiler.step()
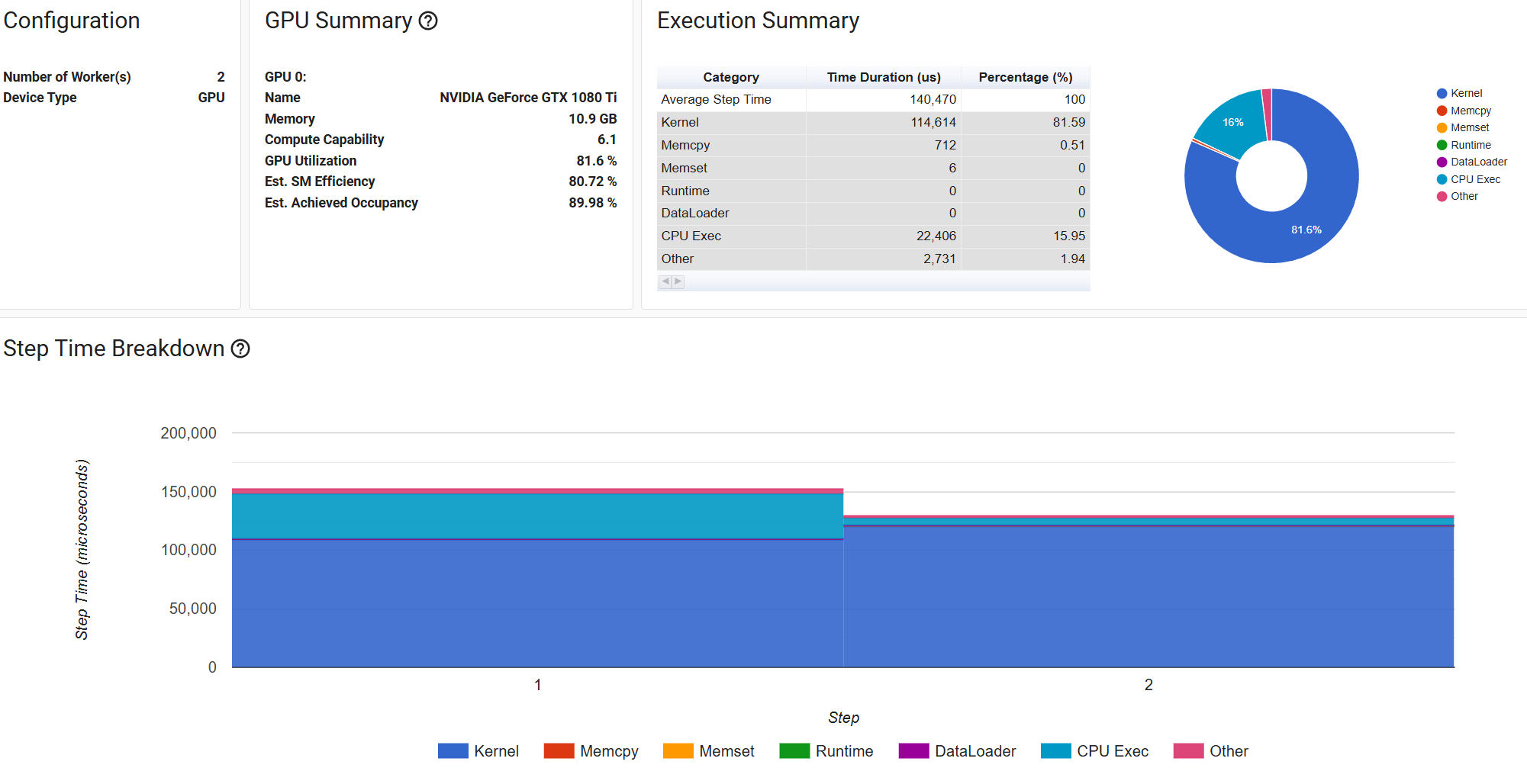
Each epoch takes about 94s. If I remove the backward process, it only takes 26s per epoch.
for data in self.dataloader:
data = self.dict_to_device(data)
loss = self.model(data)
# self.optimizer.zero_grad()
# loss.backward()
# self.optimizer.step()
profiler.step()
It seems that the backward pass is much slow.
However, when I replace the dataloader with a type of random data, each epoch (with the same number of iterations) takes only 35s:
# for data in self.dataloader:
for _ in range(712): # 712 is the number of iterations
data = {
self.model.ISeq: torch.randint(0, 1000, (1024, 50)),
self.model.IPos: torch.randint(0, 1000, (1024, 50)),
self.model.INeg: torch.randint(0, 1000, (1024, 50)),
}
data = self.dict_to_device(data)
loss = self.model(data)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
profiler.step()