The dataset I use is about 500,000 images. It took a long time to load the data, so I made an lmdb file for it. And I made a dataloader using lmdb. (reference : GitHub - thecml/pytorch-lmdb: A simple Lightning Memory-Mapped Database (LMDB) converter for ImageFolder datasets in PyTorch. Using LMDB over a regular file structure improves I/O performance significantly. Works on both Windows and Linux. Comes with latest Python support.)
And using this, I trained the network.
1 - experimenting with num_workers=0 on pytorch single gpu(process)
it takes only 1~2ms to load the batch for the area cached at the beginning of iteration. Then, after some iteration, it takes about 0.2 seconds to load because caching is not done.

When num_workers = 1, it behaved the same as num_workers = 0.
2 - experimenting with num_workers > 1
similarly, it takes only 1ms to load data at the beginning of the iteration, but after the iteration is repeated to some extent, it takes 80 seconds or tens of seconds, not 0.2 seconds, as in the image below.
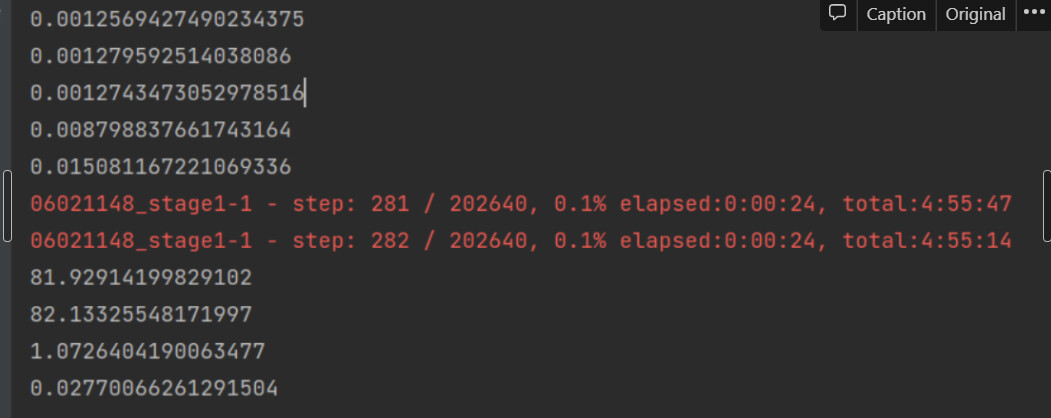
When using DDP, even if num_worker is 0, it often takes tens of seconds instead of 0.2 seconds.
It’s probably a problem when accessing the lmdb file in multi-process, how can I solve it?
For reference, even when reading an image file without using lmdb, there was still a problem that it was fast at the beginning of the iteration but became too slow after a while. I am trying to use lmdb to solve this.
One characteristic is that CPU utilization drops considerably when it’s too slow. Conversely, when it is fast (when data is read quickly), CPU utilization is high.