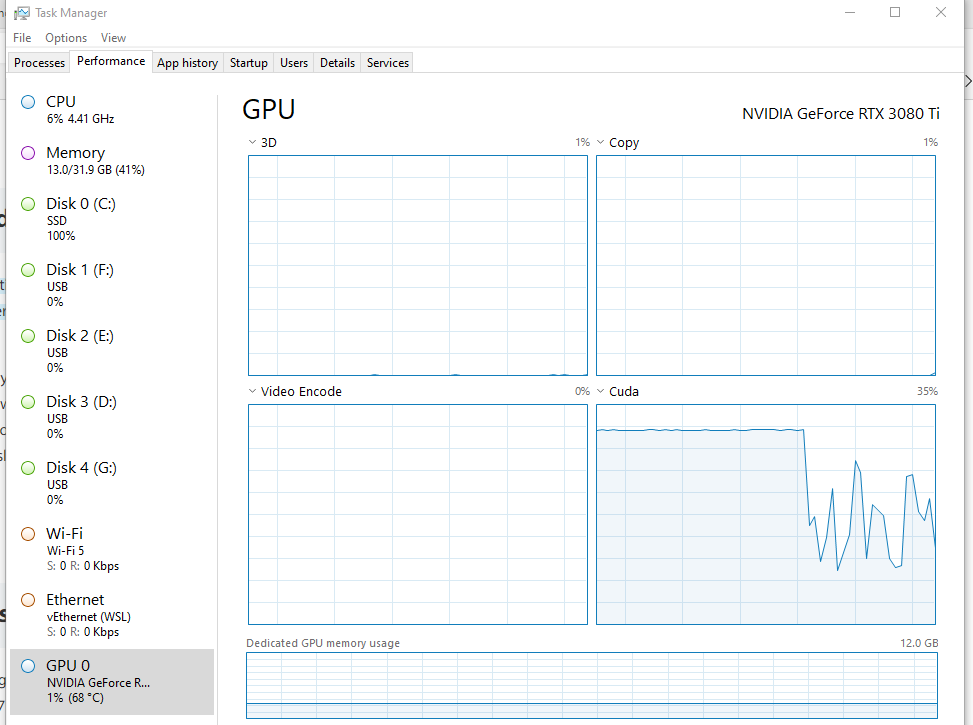
Hey all, not sure if this is the best place to post but it does seem at least potentially related to windows (or so I hope). I’ve been working on a project recently and seemingly out of nowhere I’ve hit a bottleneck where after a little training my ssd starts to max out and cuda utilization drops to low percentages as in the pic below (windows 10 pro):
Worried I pushed this ssd a little too hard and its dying now, but wanted another opinion on why this could be occurring. My external SSDs are still a little slower, however this ssd was capable of consistently utilizing cuda at 90% or so for the entirety of training only a couple days ago. This project is using mixed precision training, although I don’t imagine that would be all that relevant here (perhaps I’m wrong though). any value from 0 to 12 for num_workers has the same result after differing periods of training (although all less than one minute)
The project encountering the bottleneck is going through around 30,500 spectrogram pairs with each pair being 8MB. I tried another one of my projects which uses midi encoded into sequences of tokens where each file is 9kb, this one is able to max out cuda without issue which seems to point to the ssd being the issue. Is this in line with other peoples experiences after training for a while on an ssd? Are there any tips people might have to alleviate this issue? Not exactly a huge problem as I have free slots in my machine and can buy another ssd, but certainly something I’d like to avoid if not necessary.
I don’t know if there is a similar Windows tool, but I would try to check iotop to see the disk usage and all processes using IO operations (or are you already seeing the processes in the task manager and are sure that Python is indeed using the SSD)?
I’m not using Windows for real workloads, but have seen a high SSD usage in the past whenever Windows thought about updates performed in the background, which also decreased the overall performance massively without a warning.
Yup, I just use task manager to check it out. It is indeed Python making use of the ssd, but it looks like things are actually working as expected and it was just a data throughput issue highlighted by architecture changes in the model which had led to a speedup. I increased the depth of the architecture and now its hovering between 20% to 100% at times, but consistently at 92% utilization for cuda.
Don’t mean to resurrect an old thread, but my above assertion was incorrect - or at least partially so. The issue was apparently with the files being older and accessed quite heavily (or at least I’m guessing), and with a pure CNN the issue was alleviated due to how long all the convolutions added to each prediction. I recently regenerated my dataset from its raw source which I avoid doing as it takes a very long time, but after doing so I am able to maintain high read speeds and full utilization of my cuda cores even while using my modified architecture.